Introduction to Data Science: A Comp-Math-Stat Approach¶
YOIYUI001, Summer 2019¶
©2019 Raazesh Sainudiin. Attribution 4.0 International (CC BY 4.0)
06. Statistics from Data: Fetching New Zealand Earthquakes & Live Play with data/¶
- Live Data-fetch of NZ EQ Data
- More on Statistics
- Sample Mean
- Sample Variance
- Order Statistics
- Frequencies
- Empirical Mass Function
- Empirical Distribution Function
- List Comprehensions
- New Zealand Earthquakes
- Live Play with
data/- Swedish election data
- Biergartens in Germany
Live Data-fetching Exercise Now¶
Go to https://quakesearch.geonet.org.nz/ and download data on NZ earthquakes.
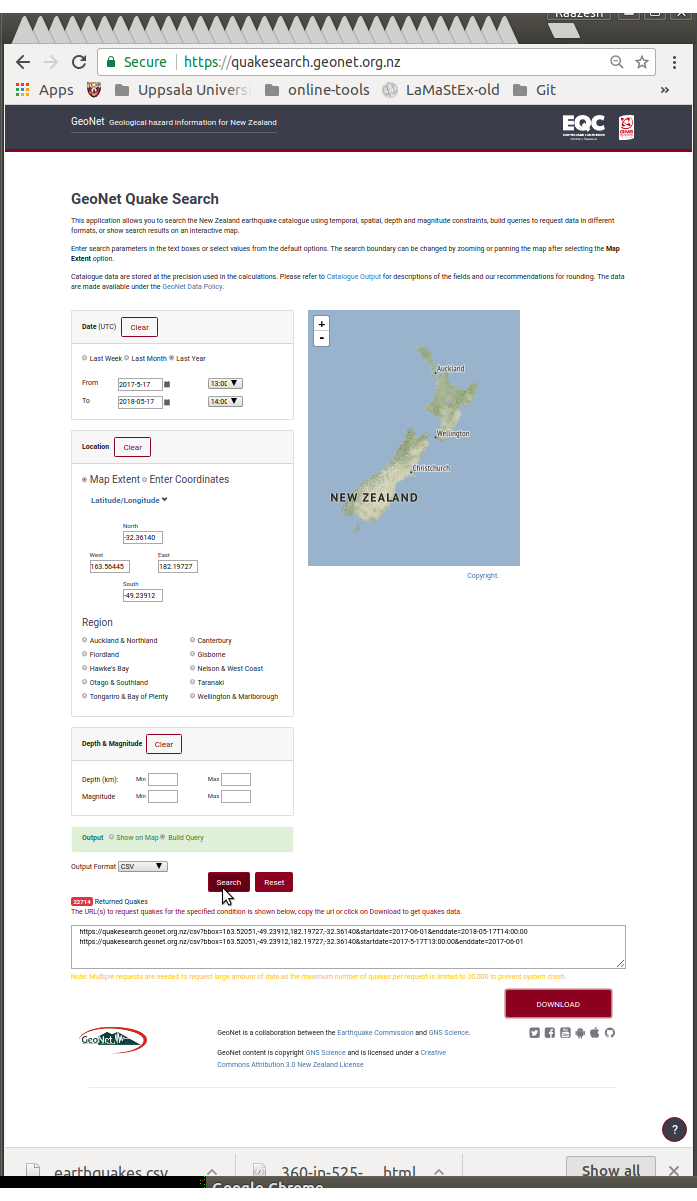
In my attempt above to zoom out to include both islands of New Zealand (NZ) and get one year of data using the Last Year button choice from this site:
- https://quakesearch.geonet.org.nz/
and hitting
Searchbox gave the following URLs for downloading data. I used theDOWNLOADbutton to get my own data in Outpur FormatCSVas chosen earlier.
https://quakesearch.geonet.org.nz/csv?bbox=163.52051,-49.23912,182.19727,-32.36140&startdate=2017-06-01&enddate=2018-05-17T14:00:00 https://quakesearch.geonet.org.nz/csv?bbox=163.52051,-49.23912,182.19727,-32.36140&startdate=2017-5-17T13:00:00&enddate=2017-06-01
What should you do now?¶
Try to DOWNLOAD your own CSV data and store it in a file named my_earthquakes.csv (NOTE: rename the file when you download so you don't replace the file earthquakes.csv!) inside the folder named data that is inside the same directory that this notebook is in.
%%sh
# print working directory
pwd
%%sh
#s # list contents of working directory
%%sh
# after download you should have the following file in directory named data
ls data
%%sh
# first three lines
head -3 data/earthquakes_small.csv
%%sh
# last three lines
tail -3 data/earthquakes_small.csv
%%sh
# number of lines in the file; menmonic from `man wc` is wc = word-count option=-l is for lines
wc -l data/earthquakes_small.csv
#%%sh
#man wc
Let's analyse the measured earth quakes in data/earthquakes.csv¶
This will ensure we are all looking at the same file!
But feel free to play with your own data/my_earthquakes.csv on the side.
Exercise:¶
Grab origin-time, lat, lon, magnitude, depth
with open("data/earthquakes_small.csv") as f:
reader = f.read()
dataList = reader.split('\n')
len(dataList)
dataList[0]
myDataAccumulatorList =[]
for data in dataList[1:-2]:
dataRow = data.split(',')
myData = [dataRow[4],dataRow[5],dataRow[6]]#,dataRow[7]]
myFloatData = tuple([float(x) for x in myData])
myDataAccumulatorList.append(myFloatData)
points(myDataAccumulatorList)
More on Statistics¶
Recall that a statistic is any measureable function of the data: $T(x): \mathbb{X} \rightarrow \mathbb{T}$.
Thus, a statistic $T$ is also an RV that takes values in the space $\mathbb{T}$.
When $x \in \mathbb{X}$ is the observed data, $T(x)=t$ is the observed statistic of the observed data $x$.
Let's Play Live with other datasets, shall we?¶
Swedish 2018 National Election Data¶
Swedish Election Outcomes 2018¶
See: http://www.lamastex.org/datasets/public/elections/2018/sv/README!
This was obtained by processing using the scripts at:
You already have this dataset in your /data directory.
%%sh
cd data
# if you don't see final.csv in data/ below
# then either uncomment and try the next line in linux/Mac OSX
#tar -zxvf final.tgz
# or try the next line after uncommenting it to extract final.csv
# unzip final.csv.zip
ls -al
%%sh
wc data/final.csv
head data/final.csv
Counting total votes per party¶
Let's quickly load the data using csv.reader and count the number of votes for each party over all of Sweden next.
import csv, sys
filename = 'data/final.csv'
linesAlreadyRead=0
partyVotesDict={}
with open(filename, 'rb') as f:
reader = csv.reader(f,delimiter=',',quotechar='"')
headers = next(reader) # skip first line of header
try:
for row in reader:
linesAlreadyRead+=1
party=row[3].decode('utf-8') # convert str to unicode
votes=int(row[4])
if party in partyVotesDict: # the data value already exists as a key
partyVotesDict[party] = partyVotesDict[party] + votes # add 1 to the count
else: # the data value does not exist as a key value
# add a new key-value pair for this new data value, frequency 1
partyVotesDict[party] = votes
except csv.Error as e:
sys.exit('file %s, line %d: %s' % (filename, reader.line_num, e))
print "lines read = ", linesAlreadyRead
# fancy printing of non-ASCII string
for kv in partyVotesDict.items():
print "party ",kv[0], "\thas a total of votes =\t", kv[1]
# let's sort by descending order of votes
for party in sorted(partyVotesDict, key=partyVotesDict.get, reverse=True):
print party, "\t", partyVotesDict[party]
# To get a dictionary back with the top K=3 most popular parties
top3PartiesDict={} # make an empty dict
for party in sorted(partyVotesDict, key=partyVotesDict.get, reverse=True):
top3PartiesDict[party]=partyVotesDict[party]
top3PartiesDict
Recall how we downloaded Pride and Prejudice and processed it as a String and split it by Chapters. These code snippets are at our disposal now - all we need to do is copy-paste the right set of cells from earlier into the cells below here to have the string from that Book for more refined processing.
Think about what algorithmic constructs and methods one will need to split each sentence by the English words it contains and then count the number of each distinct word.
Now that you have understood for loops, list comprehensions and anonymous functions, and can learn about the needed methods on strings for splitting (which you can search by adding a . after a srt and hitting the Tab button to look through existing methods and followed by ? for their docstrings), the dictionary data structure, and already seen how to count the number of ball labels, you are ready for this problem stated below. If you attended the lab then you have an advantage if you tried to work on this with some help from your instructors.
Problem: Process the English words in a text file, such as those in the book Pride and Prejudice by Jane Austin, and obtain the top K most frequent words that are longer than a given parameter wordLongerThan which can be any value in $\mathbb{Z}_+ := \{ 0, 1, 2, 3, 4, \ldots \}$, i.e., words that are longer than wordLongerThan many characters in length.
Your function must be generic and named as follows including input parameter order and names:
frequencyOftheKMostCommonWordsIn(thisTextFile, wordLongerThan, K)
This function must be capable of:
- reading any available text file in the
data/directory that can be passed as the parameterthisTextFile - and return a
dicttype whose:- key is the word whose character length is longer than the parameter
wordlongerThanand - value is the frequency of this word in the text file.
- Yor returned
dictshould only contain the topKmost frequent words longer thanwordLongerThanand be already sorted in descending order of in frequency.
- key is the word whose character length is longer than the parameter
Use the next cell to submit your answer and for rough-work use more cells as needed in order to copy-paste code snippets from earlier content to get this working. But please remove the cells for rough-work when done.
Note: that you may not import libraries that have not been introduced in the course so far.
# Report these variables so the exam can be calibrated fairly - your report will be used to justify exam-difficulty
timeToCompleteThisProblemInMinutes = 0 # replace 0 by a positive integer if it applies
# Do NOT change the name of the function and names of paramaters !
thisTextFile = 'data/someTextFilename' # try a text file in data/ directory
wordLongerThan = 0 # this can be any larger integer also
K = 20 # this can be any integer larger than 0 also
def frequencyOftheKMostCommonWordsIn(thisTextFile, wordLongerThan, K):
'''explain what the function is supposed to do briefly'''
# write the body of the function and replace 'None' with the correct return value
# ...
# ...
return None
Geospatial adventures¶
Say you want to visit some places of interest in Germany. This tutorial on Open Street Map's Overpass API shows you how to get the locations of "amenity"="biergarten" in Germany.
We may come back to https://www.openstreetmap.org later. If we don't then you know where to go for openly available data for geospatial statistical analysis.
import requests
import json
overpass_url = "http://overpass-api.de/api/interpreter"
overpass_query = """
[out:json];
area["ISO3166-1"="DE"][admin_level=2];
(node["amenity"="biergarten"](area);
way["amenity"="biergarten"](area);
rel["amenity"="biergarten"](area);
);
out center;
"""
response = requests.get(overpass_url,
params={'data': overpass_query})
data = response.json()
#data # uncomment this cell to see the raw JSON
import numpy as np
# Collect coords into list
coords = []
for element in data['elements']:
if element['type'] == 'node':
lon = element['lon']
lat = element['lat']
coords.append((lon, lat))
elif 'center' in element:
lon = element['center']['lon']
lat = element['center']['lat']
coords.append((lon, lat))
# Convert coordinates into numpy array
X = np.array(coords)
p = points(zip(X[:, 0], X[:, 1]))
p += text('Biergarten in Germany',(12,56))
p.axes_labels(['Longitude','Latitude'])
#plt.axis('equal')
p.show()

Pubs in Sweden¶
With a minor modification to the above code we can view amenity=pub in Sweden.
import requests
import json
overpass_url = "http://overpass-api.de/api/interpreter"
overpass_query = """
[out:json];
area["ISO3166-1"="SE"][admin_level=2];
(node["amenity"="pub"](area);
way["amenity"="pub"](area);
rel["amenity"="pub"](area);
);
out center;
"""
response = requests.get(overpass_url,
params={'data': overpass_query})
data = response.json()
import numpy as np
# Collect coords into list
coords = []
for element in data['elements']:
if element['type'] == 'node':
lon = element['lon']
lat = element['lat']
coords.append((lon, lat))
elif 'center' in element:
lon = element['center']['lon']
lat = element['center']['lat']
coords.append((lon, lat))
# Convert coordinates into numpy array
X = np.array(coords)
p = points(zip(X[:, 0], X[:, 1]))
p += text('Pubar i Sverige',(14,68))
p.axes_labels(['Longitude','Latitude'])
#plt.axis('equal')
p.show()

Recall the problem above on counting the number of votes by party across all of Sweden from the Swedish 2018 National Election Data.
Your task is to adapt the code snippets there and others we have encountered thus far to count the total number of votes by each district and return a list of Integers giving the number of votes for the top K districts with the most votes. Your function numberOfVotesInKMostVotedDistrictsInSE('data/final.csv', K) should work for any valid integer K.
Note: that you may not import libraries that have not been introduced in the course so far.
unzip issues: If you are unable to call unzip final.csv.zip on your windows laptop. You can either do it in the computer lab or do the following with internet access to download the large final.csv file from the internet:
%%sh
cd data
curl -O http://lamastex.org/datasets/public/elections/2018/sv/final.csvThen you should have the needed data/final.csv file.
# Report these variables so the exam can be calibrated fairly - your report will be used to justify exam-difficulty
timeToCompleteThisProblemInMinutes = 0 # replace 0 by a positive integer if it applies
# Do NOT change the name of the function and names of paramaters !
K = 20 # this can be any integer larger than 0 also, change K and make sure your function works
filename = 'data/final.csv' # this has to be a csv file with the same structure as out final.csv
def numberOfVotesInKMostVotedDistrictsInSE(filename, K):
'''explain what the function is supposed to do briefly'''
# write the body of the function and replace 'None' with the correct return value
# ...
# ...
return None
Local Test for Assignment 2, PROBLEM 2¶
Evaluate cell below to make sure your answer is valid. You should not modify anything in the cell below when evaluating it to do a local test of your solution. You may need to include and evaluate code snippets from lecture notebooks in cells above to make the local test work correctly sometimes (see error messages for clues). This is meant to help you become efficient at recalling materials covered in lectures that relate to this problem. Such local tests will generally not be available in the exam.
# test that your answer is indeed a probability by evaluating this cell after you replaced XXX above and evaluated it.
try:
assert(numberOfVotesInKMostVotedDistrictsInSE('data/final.csv', 3) == [13435, 10625, 7910])
assert(numberOfVotesInKMostVotedDistrictsInSE('data/final.csv', 1) == [13435])
print("Your answer is correct for two test cases with K=3 and K=1. Hopefully it works correctly for any K")
except AssertionError:
print("Try again! and make sure you are actually producing what is expected of you.")