Introduction
- Course Name: Scalable Data Science and Distributed Machine Learning
- Course Acronym: ScaDaMaLe or sds-3.x.
The course is given in several modules.
Expected Reference Readings
Note that you need to be logged into your library with access to these publishers:
- https://learning.oreilly.com/library/view/high-performance-spark/9781491943199/
- https://learning.oreilly.com/library/view/spark-the-definitive/9781491912201/
- https://learning.oreilly.com/library/view/learning-spark-2nd/9781492050032/
- Introduction to Algorithms, Third Edition, Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein from
- Reading Materials Provided
Course Sponsors
The course builds on contents developed since 2016 with support from New Zealand's Data Industry. The 2017-2019 versions were academically sponsored by Uppsala University's Inter-Faculty Course grant, Department of Mathematics and The Centre for Interdisciplinary Mathematics and industrially sponsored by databricks, AWS and Swedish data industry via Combient AB, SEB and Combient Mix AB. The 2021-2023 versions were/are academically sponsored by WASP Graduate School and Centre for Interdisciplinary Mathematics, and industrially sponsored by databricks and AWS via databricks University Alliance and Combient Mix AB via industrial mentorships and internships.
Course Instructor
I, Raazesh Sainudiin or Raaz, will be an instructor for the course.
I have
- more than 16 years of academic research experience in applied mathematics and statistics and
- over 8 years of experience in the data industry.
I currently (2022) have an effective joint appointment as:
- Associate Professor of Mathematics with specialisation in Data Science at Department of Mathematics, Uppsala University, Uppsala, Sweden and
- Researching,Developing and Enabling Chair in Mathematical Data Engineering Sciences at Combient Mix AB, Stockholm, Sweden
Quick links on Raaz's background:
What is the Data Science Process
The Data Science Process in one picture

Data Science Process under the Algorithms-Machines-Peoples-Planet Framework
Note that the Data Product that is typically a desired outcome of the Data Science Process can be anything that has commercial value (to help make a livig, colloquially speaking), including a software product, hardware product, personalized medicine for a specific individual, or pasture-raised chicken based on intensive data collection from field experiments in regenerative agriculture, among others.
It is extremely important to be aware of the underlying actual costs and benefits in any Data Science Process under the Algorithms-Machines-Peoples-Planet Framework. We will see this in the sequel at a high level.
What is scalable data science and distributed machine learning?
Scalability merely refers to the ability of the data science process to scale to massive datasets (popularly known as big data).
For this we need distributed fault-tolerant computing typically over large clusters of commodity computers -- the core infrastructure in a public cloud today.
Distributed Machine Learning allows the models in the data science process to be scalably trained and extract value from big data.
What is Data Science?
It is increasingly accepted that Data Science
is an inter-disciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from many structural and unstructured data. Data science is related to data mining, machine learning and big data.
Data science is a "concept to unify statistics, data analysis and their related methods" in order to "understand and analyze actual phenomena" with data. It uses techniques and theories drawn from many fields within the context of mathematics, statistics, computer science, domain knowledge and information science. Turing award winner Jim Gray imagined data science as a "fourth paradigm" of science (empirical, theoretical, computational and now data-driven) and asserted that "everything about science is changing because of the impact of information technology" and the data deluge.
Now, let us look at two industrially-informed academic papers that influence the above quote on what is Data Science, but with a view towards the contents and syllabus of this course.
key insights in the above paper
- Data Science is the study of the generalizabile extraction of knowledge from data.
- A common epistemic requirement in assessing whether new knowledge is actionable for decision making is its predictive power, not just its ability to explain the past.
- A data scientist requires an integrated skill set spanning
- mathematics,
- machine learning,
- artificial intelligence,
- statistics,
- databases, and
- optimization,
- along with a deep understanding of the craft of problem formulation to engineer effective solutions.
key insights in the above paper
- ML is concerned with the building of computers that improve automatically through experience
- ML lies at the intersection of computer science and statistics and at the core of artificial intelligence and data science
- Recent progress in ML is due to:
- development of new algorithms and theory
- ongoing explosion in the availability of online data
- availability of low-cost computation (through clusters of commodity hardware in the cloud )
- The adoption of data science and ML methods is leading to more evidence-based decision-making across:
- life sciences (neuroscience, genomics, agriculture, etc. )
- manufacturing
- robotics (autonomous vehicle)
- vision, speech processing, natural language processing
- education
- financial modeling
- policing
- marketing
US CIA's CTO Gus Hunt's View on Big Data and Data Science
This is recommended viewing for historical insights into Big Data and Data Science skills - thanks to Snowden's Permanent Record for this pointer. At least watch for a few minutes from about 23 minutes to see what Gus Hunt, the then CTO of the American CIA, thinks about the combination of skills needed for Data Science. Watch the whole talk by Gus Hunt titled CIA's Chief Tech Officer on Big Data: We Try to Collect Everything and Hang Onto It Forever if you have 20 minutes or so to get a better framework for this first lecture on the data science process.

Apache Spark actually grew out of Obama era Big Data straetigic grants to UC Berkeley's AMP Lab (the academic origins of Apark and databricks).
The Gus Hunt's distinction proposed here between enumeration versus modeling is mathematically fundamental. The latter is within the realm of classical probabilistic learning theory (eg. Probabilistic Theory of Pattern Recognition, Devroye, Luc; Györfi, László; Lugosi, Gábor, 1996), including, Deep Learning, Reinforcement Learning, etc.), while the former is partly frameable within a wider mathematical setting known as predicting individual sequences (eg. Prediction, Learning and Games, Cesa-Bianchi, N., & Lugosi, G., 2006).
But what is Data Engineering (including Machine Learning Engineering and Operations) and how does it relate to Data Science?
Data Engineering
There are several views on what a data engineer is supposed to do:
Some views are rather narrow and emphasise division of labour between data engineers and data scientists:
- https://www.oreilly.com/ideas/data-engineering-a-quick-and-simple-definition
- Let's check out what skills a data engineer is expected to have according to the link above.
"Ian Buss, principal solutions architect at Cloudera, notes that data scientists focus on finding new insights from a data set, while data engineers are concerned with the production readiness of that data and all that comes with it: formats, scaling, resilience, security, and more."
What skills do data engineers need? Those “10-30 different big data technologies” Anderson references in “Data engineers vs. data scientists” can fall under numerous areas, such as file formats, > ingestion engines, stream processing, batch processing, batch SQL, data storage, cluster management, transaction databases, web frameworks, data visualizations, and machine learning. And that’s just the tip of the iceberg.
Buss says data engineers should have the following skills and knowledge:
- They need to know Linux and they should be comfortable using the command line.
- They should have experience programming in at least Python or Scala/Java.
- They need to know SQL.
- They need some understanding of distributed systems in general and how they are different from traditional storage and processing systems.
- They need a deep understanding of the ecosystem, including ingestion (e.g. Kafka, Kinesis), processing frameworks (e.g. Spark, Flink) and storage engines (e.g. S3, HDFS, HBase, Kudu). They should know the strengths and weaknesses of each tool and what it's best used for.
- They need to know how to access and process data.
Let's dive deeper into such highly compartmentalised views of data engineers and data scientists and the so-called "machine learning engineers" according the following view:
- https://www.oreilly.com/ideas/data-engineers-vs-data-scientists
Industry will keep evolving, so expect new titles in the future to get new types of jobs done.
The Data Engineering Scientist as "The Middle Way"
Here are some basic axioms that should be self-evident.
- Yes, there are differences in skillsets across humans
- some humans will be better and have inclinations for engineering and others for pure mathematics by nature and nurture
- one human cannot easily be a master of everything needed for innovating a new data-based product or service (very very rarely though this happens)
- Skills can be gained by any human who wants to learn to the extent s/he is able to expend time, energy, etc.
For the Scalable Data Engineering Science Process: towards Production-Ready and Productisable Prototyping we need to allow each data engineer to be more of a data scientist and each data scientist to be more of a data engineer, up to each individual's comfort zones in technical and mathematical/conceptual and time-availability planes, but with some minimal expectations of mutual appreciation.
This course is designed to help you take the first minimal steps towards such a data engineering science process.
In the sequel it will become apparent why a team of data engineering scientists with skills across the conventional (2022) spectrum of data engineer versus data scientist is crucial for Production-Ready and Productisable Prototyping, whose outputs include standard AI products today.
A Brief Tour of Data Science
History of Data Analysis and Where Does "Big Data" Come From?
- A Brief History and Timeline of Data Analysis and Big Data
- https://en.wikipedia.org/wiki/Big_data
- https://whatis.techtarget.com/feature/A-history-and-timeline-of-big-data
- Where does Data Come From?
- Some of the sources of big data.
- online click-streams (a lot of it is recorded but a tiny amount is analyzed):
- record every click
- every ad you view
- every billing event,
- every transaction, every network message, and every fault.
- User-generated content (on web and mobile devices):
- every post that you make on Facebook
- every picture sent on Instagram
- every review you write for Yelp or TripAdvisor
- every tweet you send on Twitter
- every video that you post to YouTube.
- Science (for scientific computing):
- data from various repositories for natural language processing:
- Wikipedia,
- the Library of Congress,
- twitter firehose and google ngrams and digital archives,
- data from scientific instruments/sensors/computers:
- the Large Hadron Collider (more data in a year than all the other data sources combined!)
- genome sequencing data (sequencing cost is dropping much faster than Moore's Law!)
- output of high-performance computers (super-computers) for data fusion, estimation/prediction and exploratory data analysis
- data from various repositories for natural language processing:
- Graphs are also an interesting source of big data (network science).
- social networks (collaborations, followers, fb-friends or other relationships),
- telecommunication networks,
- computer networks,
- road networks
- machine logs:
- by servers around the internet (hundreds of millions of machines out there!)
- internet of things.
- online click-streams (a lot of it is recorded but a tiny amount is analyzed):
Data Science with Cloud Computing and What's Hard about it?
- See Cloud Computing to understand the work-horse for analysing big data at data centers
Cloud computing is the on-demand availability of computer system resources, especially data storage (cloud storage) and computing power, without direct active management by the user. Large clouds often have functions distributed over multiple locations, each location being a data center. Cloud computing relies on sharing of resources to achieve coherence and economies of scale, typically using a "pay-as-you-go" model which can help in reducing capital expenses but may also lead to unexpected operating expenses for unaware users.
-
In fact, if you are logged into
https://*.databricks.com/*you are computing in the cloud! So the computations are actually running in an instance of the hardware available at a data center like the following: -
Here is a data center used by CERN in 2010.
-
What's hard about scalable data science in the cloud?
- To analyse datasets that are big, say more than a few TBs, we need to split the data and put it in several computers that are networked - a typical cloud

- However, as the number of computer nodes in such a network increases, the probability of hardware failure or fault (say the hard-disk or memory or CPU or switch breaking down) also increases and can happen while the computation is being performed
- Therefore for scalable data science, i.e., data science that can scale with the size of the input data by adding more computer nodes, we need fault-tolerant computing and storage framework at the software level to ensure the computations finish even if there are hardware faults.


Here is a recommended light reading on What is "Big Data" -- Understanding the History (18 minutes): - https://towardsdatascience.com/what-is-big-data-understanding-the-history-32078f3b53ce
What should you be able to do at the end of this course?
By following these online interactions in the form of lab/lectures, asking questions, engaging in discussions, doing HOMEWORK assignments and completing the group project, you should be able to:
- Understand the principles of fault-tolerant scalable computing in Spark
- in-memory and generic DAG extensions of Map-reduce
- resilient distributed datasets for fault-tolerance
- skills to process today's big data using state-of-the art techniques in Apache Spark 3.0, in terms of:
- hands-on coding with realistic datasets
- an intuitive understanding of the ideas behind the technology and methods
- pointers to academic papers in the literature, technical blogs and video streams for you to futher your theoretical understanding.
- More concretely, you will be able to:
- Extract, Transform, Load, Interact, Explore and Analyze Data
- Build Scalable Machine Learning Pipelines (or help build them) using Distributed Algorithms and Optimization
- How to keep up?
- This is a fast-changing world.
- Recent videos around Apache Spark are archived here (these videos are a great way to learn the latest happenings in industrial R&D today!):
- What is mathematically stable in the world of 'big data'?
- There is a growing body of work on the analysis of parallel and distributed algorithms, the work-horse of big data and AI.
- We will see the core of this in the theoretical material from Reza Zadeh's course on Distributed Algorithms and Optimisation.
Data Science Process under the Algorithms-Machines-Peoples-Planet Framework
Preparatory perusal at some distance, without necessarily associating oneself with any particular "philosophy", in order to intuitively understand the Data Science Process under the Algorithms-Machines-Peoples-Planet (AMPP) Framework, as formal Decision Problems and Decision Procedures (including any AI/ML algorithm) for consideration before Action using Mathematical Decision Theory.
- Kate Crawford and Vladan Joler, “Anatomy of an AI System: The Amazon Echo As An Anatomical Map of Human Labor, Data and Planetary Resources,” AI Now Institute and Share Lab, (September 7, 2018)
- Browse anatomyof.ai.
- View full-scale map as PDF
- Read Map + Essay as PDF in A3 format (expected time is about 1.5 hours for thorough comprehension)
- MANIFESTO ON THE FUTURE OF SEEDS. Produced by The International Commission on the Future of Food and Agriculture, 36 pages. (2006). Disseminated as PDF from http://lamastex.org/JOE/ManifestoOnFutureOfSeeds*2006.pdf.
- The Joint Operating Environment (JOE) limited to the perspective of The United States:
- Read at least page 3 on "About this Study" https://www.jcs.mil/Portals/36/Documents/Doctrine/concepts/joe*2008.pdf
- Do a deeper dive if interested at https://www.jcs.mil/Doctrine/Joint-Concepts/JOE/ following through Joint Operating Environment, 2010 and Joint Operating Environment 2035, 14 July 2016
- Read at least page 3 on "About this Study" https://www.jcs.mil/Portals/36/Documents/Doctrine/concepts/joe*2008.pdf
- Know the doctrine of Mutual Assured Destruction (MAD). Peruse: https://en.wikipedia.org/wiki/Mutual*assured*destruction
- Peruse https://www.oneearth.org/our-mission/, and more specifically inform yourself by further perusing
- Energy Transition: https://www.oneearth.org/science/energy/
- Nature Conservation: https://www.oneearth.org/science/nature/
- Regenerative Agriculture: https://www.oneearth.org/science/agriculture/
Interactions
When you are involved in a data science process (to "make a living", say) under the AMPP framework, your Algorithms implemented on Machines can have different effects on Peoples (meaning, any living populations of any species, including different human sub-populations, plants, animals, microbes, etc.) and our Planet (soils, climates, oceans, etc.) as long as the Joint Operating Environment is stable to avoid Mutual Assured Destruction.
Discussion 0
- Is it important to be aware of such different effects when building of a data product in some data science process?
- We will limit the discussions on the concrete matter of "Alexa", AWS's voice assistant.
- what are your thoughts on https://anatomyof.ai/?
- We will limit the discussions on the concrete matter of "Alexa", AWS's voice assistant.
This is a primer for our industrial guest speakers from https://www.trase.earth/ who will talk about supply chains.
Why Apache Spark?
- Apache Spark: A Unified Engine for Big Data Processing By Matei Zaharia, Reynold S. Xin, Patrick Wendell, Tathagata Das, Michael Armbrust, Ankur Dave, Xiangrui Meng, Josh Rosen, Shivaram Venkataraman, Michael J. Franklin, Ali Ghodsi, Joseph Gonzalez, Scott Shenker, Ion Stoica Communications of the ACM, Vol. 59 No. 11, Pages 56-65 10.1145/2934664

Right-click the above image-link, open in a new tab and watch the video (4 minutes) or read about it in the Communications of the ACM in the frame below or from the link above.
Key Insights from Apache Spark: A Unified Engine for Big Data Processing
- A simple programming model can capture streaming, batch, and interactive workloads and enable new applications that combine them.
- Apache Spark applications range from finance to scientific data processing and combine libraries for SQL, machine learning, and graphs.
- In six years, Apache Spark has grown to 1,000 contributors and thousands of deployments.

Spark 3.0 is the latest version now (20200918) and it should be seen as the latest step in the evolution of tools in the big data ecosystem as summarized in https://towardsdatascience.com/what-is-big-data-understanding-the-history-32078f3b53ce:
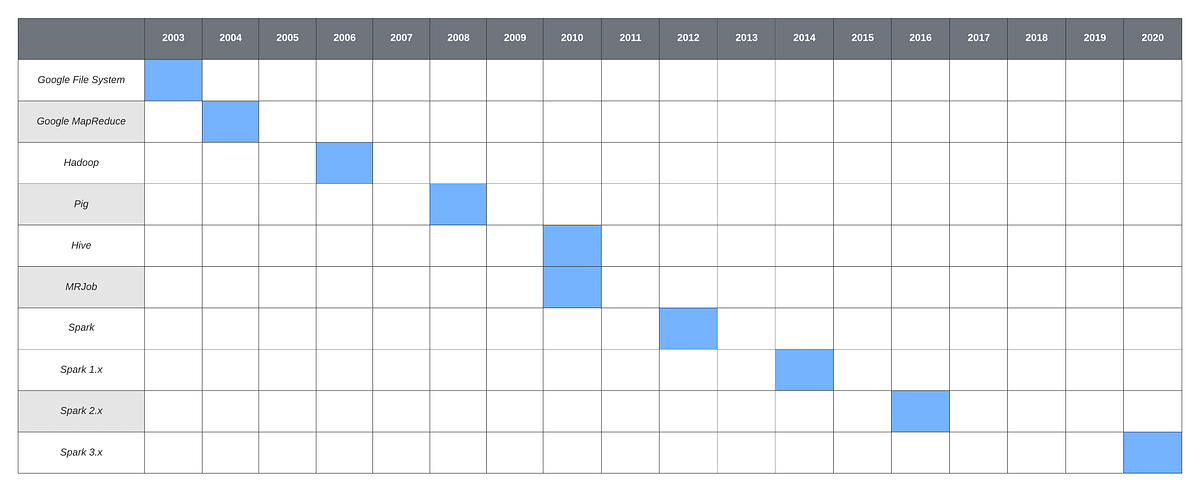
Alternatives to Apache Spark
There are several alternatives to Apache Spark, but none of them have the penetration and community of Spark as of 2021.
For real-time streaming operations Apache Flink is competitive. See Apache Flink vs Spark – Will one overtake the other? for a July 2021 comparison. Most scalable data science and engineering problems faced by several major industries in Sweden today are routinely solved using tools in the ecosystem around Apache Spark. Therefore, we will focus on Apache Spark here which still holds the world record for 10TB or 10,000 GB sort by Alibaba cloud in 06/17/2020.
Several alternatives to Apache Spark exist. See the following for verious commercial options: - https://sourceforge.net/software/product/Apache-Spark/alternatives
Read the following for a comparison of three popular frameworks in 2022 for distributed computing:
Here, we will focus on Apache Spark as it is still a popular framework for distributed computing with a rich ecosystem around it.
The big data problem
Hardware, distributing work, handling failed and slow machines
Let us recall and appreciate the following:
- The Big Data Problem
- Many routine problems today involve dealing with "big data", operationally, this is a dataset that is larger than a few TBs and thus won't fit into a single commodity computer like a powerful desktop or laptop computer.
- Hardware for Big Data
- The best single commodity computer can not handle big data as it has limited hard-disk and memory
- Thus, we need to break the data up into lots of commodity computers that are networked together via cables to communicate instructions and data between them - this can be thought of as a cloud
- How to distribute work across a cluster of commodity machines?
- We need a software-level framework for this.
- How to deal with failures or slow machines?
- We also need a software-level framework for this.
Key Papers
- Key Historical Milestones
- 1956-1979: Stanford, MIT, CMU, and other universities develop set/list operations in LISP, Prolog, and other languages for parallel processing
- 2004: READ: Google's MapReduce: Simplified Data Processing on Large Clusters, by Jeffrey Dean and Sanjay Ghemawat
- 2006: Yahoo!'s Apache Hadoop, originating from the Yahoo!’s Nutch Project, Doug Cutting - wikipedia
- 2009: Cloud computing with Amazon Web Services Elastic MapReduce, a Hadoop version modified for Amazon Elastic Cloud Computing (EC2) and Amazon Simple Storage System (S3), including support for Apache Hive and Pig.
- 2010: READ: The Hadoop Distributed File System, by Konstantin Shvachko, Hairong Kuang, Sanjay Radia, and Robert Chansler. IEEE MSST
- Apache Spark Core Papers
- 2012: READ: Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing, Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker and Ion Stoica. NSDI
- 2016: Apache Spark: A Unified Engine for Big Data Processing By Matei Zaharia, Reynold S. Xin, Patrick Wendell, Tathagata Das, Michael Armbrust, Ankur Dave, Xiangrui Meng, Josh Rosen, Shivaram Venkataraman, Michael J. Franklin, Ali Ghodsi, Joseph Gonzalez, Scott Shenker, Ion Stoica , Communications of the ACM, Vol. 59 No. 11, Pages 56-65, 10.1145/2934664
- A lot has happened since 2016 to improve efficiency of Spark and embed more into the big data ecosystem
- More research papers on Spark are available from here and we will refer to them in the sequel as needed:
MapReduce and Apache Spark.
MapReduce as we will see shortly in action is a framework for distributed fault-tolerant computing over a fault-tolerant distributed file-system, such as Google File System or open-source Hadoop for storage.
- Unfortunately, Map Reduce is bounded by Disk I/O and can be slow
- especially when doing a sequence of MapReduce operations requirinr multiple Disk I/O operations
- Apache Spark can use Memory instead of Disk to speed-up MapReduce Operations
- Spark Versus MapReduce - the speed-up is orders of magnitude faster
- SUMMARY
- Spark uses memory instead of disk alone and is thus fater than Hadoop MapReduce
- Spark's resilience abstraction is by RDD (resilient distributed dataset)
- RDDs can be recovered upon failures from their lineage graphs, the recipes to make them starting from raw data
- Spark supports a lot more than MapReduce, including streaming, interactive in-memory querying, etc.
- Spark demonstrated an unprecedented sort of 1 petabyte (1,000 terabytes) worth of data in 234 minutes running on 190 Amazon EC2 instances (in 2015).
- Spark expertise corresponds to the highest Median Salary in the US (~ 150K)
Login to databricks
We will use databricks community edition and later on the databricks project shard granted for this course under the databricks university alliance with cloud computing grants from databricks for waived DBU units and AWS.
Please go here for a relaxed and detailed-enough tour (later):
databricks community edition
First obtain a free Obtain a databricks community edition account at https://community.cloud.databricks.com by following these instructions: https://youtu.be/FH2KDhaFkZg.
Let's get an overview of the databricks managed cloud for processing big data with Apache Spark.

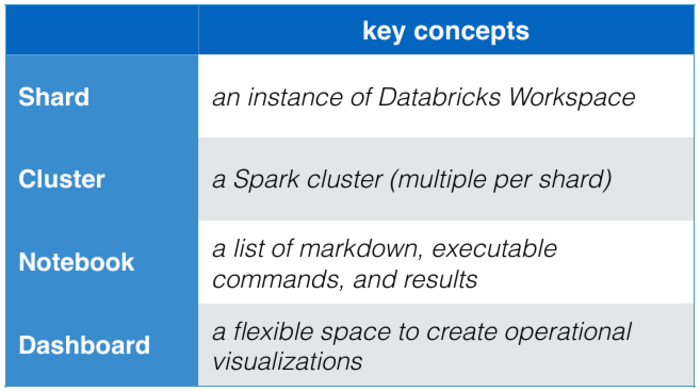
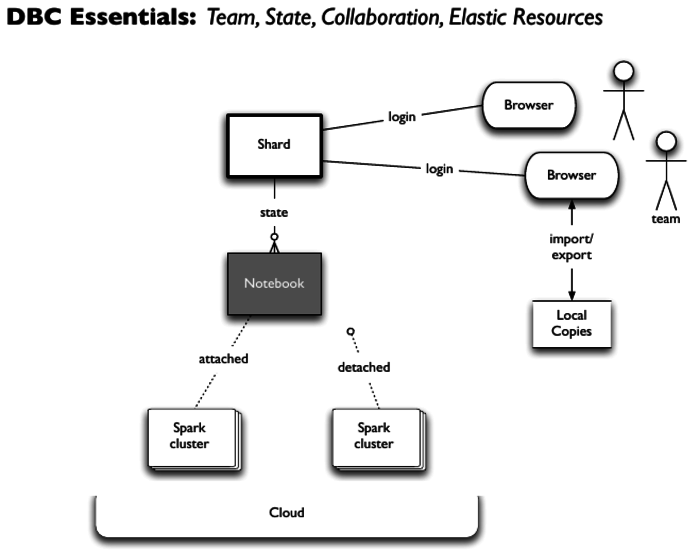
DBC Essentials: Team, State, Collaboration, Elastic Resources in one picture
You Should All Have databricks community edition account by now! and have successfully logged in to it.
Import Course Content Now!
Two Steps:
- Create a folder named
scalable-data-sciencein yourWorkspace(NO Typos due to hard-coding of paths in the sequel!)
- Import the following
.dbcarchives from the following URL intoWorkspace/scalable-data-sciencefolder you just created:- https://github.com/lamastex/scalable-data-science/raw/master/dbcArchives/latest/
- start with the first file for now and import more as needed:
Open-Source Computing Environment
We will mainly use docker for local development on our own infrastructure, such as a laptop.
docker
You can install and learn docker on your laptop; https://docs.docker.com/get-started/.
In a Terminal, after installing docker, type:
$ docker run --rm -it lamastex/dockerdev:latest
The above docker container has already downloaded the needed sources for a very basic Spark developer environment using this Dockerfile which builds on this spark3x.Dockerfile. Having the source for a dockerfile is helpful when one needs to adapt it for the future.
You can test your docker installation by launching the spark-shell inside the docker container, compute 1+1 and :quit from spark-shell and exit from docker.
root@7715366c86a4:~# spark-shell
22/08/18 12:24:26 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://7715366c86a4:4040
Spark context available as 'sc' (master = local[*], app id = local-1660825477089).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 1.8.0_312)
Type in expressions to have them evaluated.
Type :help for more information.
scala> 1+1
res0: Int = 2
scala> :quit
root@c6ced3348c97:~# exit
zeppelin
You may also use the open source project https://zeppelin.apache.org/ through the provided zeppelin spark docker container lamastex/zeppelin-spark after successfully installing docker in your laptop.
Several companies use databricks notebooks but several others use zeppelin or jupyter or other notebook servers. Therefore, it is good to be familiar with a couple notebook servers and formats.
Please go here for a relaxed and detailed-enough tour (later):
Multi-lingual Notebooks
Write Spark code for processing your data in notebooks.
Note that there are several open-sourced notebook servers including:
For comparison between pairs of notebook servers see:
- https://datasciencenotebook.org/compare/zeppelin/databricks
- https://datasciencenotebook.org/compare/jupyter/databricks
Here, we are mainly focused on using databricks notebooks due to its effeciently managed engineering layers over AWS (or Azure or GPC public clouds).
This allows us to focus on the concepts and models and get to implement codes with ease.
NOTE: By now you should have already opened this notebook and attached it to a cluster:
- that you started in the Community Edition of databricks
- or that you started in the zeppelin spark docker container similar to lamastex/zeppelin-spark
Databricks Notebook
Next we delve into the mechanics of working with databricks notebooks.
- But many of the details also apply to other notebook environments such as zeppelin with minor differences.
Some Zeppelin caveats
- Since many companies use other notebook servers we will make remarks on minor differences between databricks and zeppelin notebook formats, in case you want to try zeppelin server on your laptop or your own infrastructure.
- Note that one can run Jupyter within Zeppelin. We use Zeppelin as opposed to Jupyter here because Zeppelin comes with a much broader collection of default interpreters for today's big data ecosystem and we wanted to only have one other open-source notebook server to complement learning in the currently (2022) closed-source notebook server of databricks.
Notebooks can be written in Python, Scala, R, or SQL.
- This is a Scala notebook - which is indicated next to the title above by
(Scala). - One can choose the default language of the notebook when it is created.
Creating a new Notebook
- Select Create > Notebook.
- Enter the name of the notebook, the language (Python, Scala, R or SQL) for the notebook, and a cluster to run it on.
- From Left Menu you can go to 'Workspace' and then Click the tiangle on the right side of a folder to open the folder menu and create notebook in the folder.
Cloning a Notebook
- You can clone a notebook to create a copy of it, for example if you want to edit or run an Example notebook like this one.
- Click File > Clone in the notebook context bar above.
- Enter a new name and location for your notebook. If Access Control is enabled, you can only clone to folders that you have Manage permissions on.
Clone Or Import This Notebook
-
From the File menu at the top left of this notebook, choose Clone or click Import Notebook on the top right. This will allow you to interactively execute code cells as you proceed through the notebook.
-
Enter a name and a desired location for your cloned notebook (i.e. Perhaps clone to your own user directory or the "Shared" directory.)
-
Navigate to the location you selected (e.g. click Menu > Workspace >
Your cloned location)
Attach the Notebook to a cluster
- A Cluster is a group of machines which can run commands in cells.
- Check the upper left corner of your notebook to see if it is Attached or Detached.
- If Detached, click on the right arrow and select a cluster to attach your notebook to.
- If there is no running cluster, create one.
Deep-dive into databricks notebooks
Let's take a deeper dive into a databricks notebook next.
Cells are units that make up notebooks
Cells each have a type - including scala, python, sql, R, markdown, filesystem, and shell.
- While cells default to the type of the Notebook, other cell types are supported as well.
- This cell is in markdown and is used for documentation. Markdown is a simple text formatting syntax.
Beware of minor differences across notebook formats
- Different notebook formats use different tags for the same language interpreter. But they are quite easy to remember.
- For example in zeppelin
%sparkand%pysparkare used instead of databricks'%scalaand%pythonto denote spark and pyspark cells. - However
%mdand%share used for markdown and shell in both notebook formats. ***
- For example in zeppelin
Create and Edit a New Markdown Cell in this Notebook
NOTE: You will be writing your group project report as databricks notebooks, therefore it is important to use markdown effectively.
-
When you mouse between cells, a + sign will pop up in the center that you can click on to create a new cell.
-
Type
%md Hello, world!into your new cell (%mdindicates the cell is markdown). -
Click out of the cell or double-click to see the cell contents update.
Running a cell in your notebook.
- Press Shift+Enter when in the cell to run it and proceed to the next cell.
- The cells contents should update.
- NOTE: Cells are not automatically run each time you open it.
- Instead, Previous results from running a cell are saved and displayed.
- Alternately, press Ctrl+Enter when in a cell to run it, but not proceed to the next cell.
You Try Now! Just double-click the cell below, modify the text following %md and press Ctrl+Enter to evaluate it and see it's mark-down'd output.
> %md Hello, world!
Hello, world!
Markdown Cell Tips
- To change a non-markdown cell to markdown, add
%mdto very start of the cell. - After updating the contents of a markdown cell, click out of the cell to update the formatted contents of a markdown cell.
- To edit an existing markdown cell, doubleclick the cell.
Learn more about markdown:
Note that there are flavours or minor variants and enhancements of markdown, including those specific to databricks, github, pandoc, etc.
It will be future-proof to remain in the syntactic zone of pure markdown (at the intersection of various flavours) as much as possible and go with pandoc-compatible style if choices are necessary. ***
Run a Scala Cell
- Run the following scala cell.
- Note: There is no need for any special indicator (such as
%md) necessary to create a Scala cell in a Scala notebook. - You know it is a scala notebook because of the
(Scala)appended to the name of this notebook. - Make sure the cell contents updates before moving on.
- Press Shift+Enter when in the cell to run it and proceed to the next cell.
- The cells contents should update.
- Alternately, press Ctrl+Enter when in a cell to run it, but not proceed to the next cell.
- characters following
//are comments in scala. - RECALL: In zeppelin
%sparkis used instead of%scala. ***
1+1
res0: Int = 2
println(System.currentTimeMillis) // press Ctrl+Enter to evaluate println that prints its argument as a line
1664271875320
1+1
res2: Int = 2
Spark is written in Scala, but ...
For this reason Scala will be the primary language for this course is Scala.
However, let us use the best language for the job! as each cell can be written in a specific language in the same notebook. Such multi-lingual notebooks are the norm in any realistic data science process today!
The beginning of each cells has a language type if it is not the default language of the notebook. Such cell-specific language types include the following with the prefix %:
-
%scalafor Spark Scala,%sparkin zeppelin
-
%pyfor PySpark,%pysparkin zeppelin
-
%rfor R, -
%sqlfor SQL, -
%shfor BASH SHELL and -
%mdfor markdown. -
While cells default to the language type of the Notebook (scala, python, r or sql), other cell types are supported as well in a cell-specific manner.
-
For example, Python Notebooks can contain python, sql, markdown, and even scala cells. This lets you write notebooks that do use multiple languages.
-
This cell is in markdown as it begins with
%mdand is used for documentation purposes.
Thus, all language-typed cells can be created in any notebook, regardless of the the default language of the notebook itself, provided interpreter support exists for the languages.
Cross-language cells can be used to mix commands from other languages.
Examples:
print("For example, this is a scala notebook, but we can use %py to run python commands inline.")
// you can be explicit about the language even if the notebook's default language is the same
println("We can access Scala like this.")
We can access Scala like this.
Command line cells can be used to work with local files on the Spark driver node. * Start a cell with %sh to run a command line command
# This is a command line cell. Commands you write here will be executed as if they were run on the command line.
# For example, in this cell we access the help pages for the bash shell.
ls
whoami
Notebooks can be run from other notebooks using %run
This is commonly used to import functions you defined in other notebooks.
- Syntax in databricks:
%run /full/path/to/notebook - Syntax in zeppelin:
z.runNote("id")
Displaying in notebooks
Notebooks are great for displaying data in the input cell immediately in the result or output cell. This is often an effective web-based REPL environment to prototype for the data science process.
To display a dataframe or tabular data named myDataFrame:
- Notebook-agnostic syntax in Spark for textual display:
myDataFrame.show() - Syntax in databricks:
display(myDataFrame) - Syntax in zeppelin:
z.show(myDataFrame)
One can also display more sophisticated outputs involving HTML and D3 using display_HTML in databricks or %html in zeppelin. See respective documentation for details. Zeppelin is extremely flexible via helium when it comes to creating interactive visualisations of results from a data science process pipeline.
Further Pointers
Here are some useful links to bookmark as you will need to use them for Reference.
These links provide a relaxed and detailed-enough tour (that you may need to take later):
- databricks
- zeppelin (if you want an open-source notebook server deployed on your own computing infrastructure)
Load Datasets into Databricks
Simply, hit run Runa all cells in this Notebook to load all the core datasets we will be using in the first couple of modules in this course.
It can take about 2-3 minutes once your cluster starts.
Note This notebook should be skipped in docker-compose zeppelin instance of the course.
wget https://github.com/lamastex/sds-datasets/raw/master/datasets-sds.zip
ls -al *
unzip datasets-sds.zip
pwd
rm -r dbfs:///datasets/sds/
res0: Boolean = true
mkdirs dbfs:///datasets/sds/
res1: Boolean = true
cp -r file:///databricks/driver/datasets-sds/ dbfs:///datasets/sds/
res2: Boolean = true
ls /datasets/sds/
| path | name | size | modificationTime |
|---|---|---|---|
| dbfs:/datasets/sds/Rdatasets/ | Rdatasets/ | 0.0 | 1.664296004294e12 |
| dbfs:/datasets/sds/cs100/ | cs100/ | 0.0 | 1.664296004295e12 |
| dbfs:/datasets/sds/flights/ | flights/ | 0.0 | 1.664296004295e12 |
| dbfs:/datasets/sds/mnist-digits/ | mnist-digits/ | 0.0 | 1.664296004295e12 |
| dbfs:/datasets/sds/people/ | people/ | 0.0 | 1.664296004295e12 |
| dbfs:/datasets/sds/people.json/ | people.json/ | 0.0 | 1.664296004295e12 |
| dbfs:/datasets/sds/power-plant/ | power-plant/ | 0.0 | 1.664296004295e12 |
| dbfs:/datasets/sds/social_media_usage.csv/ | social_media_usage.csv/ | 0.0 | 1.664296004295e12 |
| dbfs:/datasets/sds/songs/ | songs/ | 0.0 | 1.664296004295e12 |
| dbfs:/datasets/sds/souall.txt.gz | souall.txt.gz | 3576868.0 | 1.664296002e12 |
| dbfs:/datasets/sds/spark-examples/ | spark-examples/ | 0.0 | 1.664296004295e12 |
| dbfs:/datasets/sds/weather/ | weather/ | 0.0 | 1.664296004295e12 |
| dbfs:/datasets/sds/wikipedia-datasets/ | wikipedia-datasets/ | 0.0 | 1.664296004295e12 |
sc.textFile("/datasets/sds/souall.txt.gz").count // should be 22258
res4: Long = 22258
Now you have loaded the core datasets for the course.
Scala Crash Course
Here we take a minimalist approach to learning just enough Scala, the language that Apache Spark is written in, to be able to use Spark effectively.
In the sequel we can learn more Scala concepts as they arise. This learning can be done by chasing the pointers in this crash course for a detailed deeper dive on your own time.
There are two basic ways in which we can learn Scala:
1. Learn Scala in a notebook environment
For convenience we use databricks Scala notebooks like this one here.
You can learn Scala locally on your own computer using Scala REPL (and Spark using Spark-Shell).
2. Learn Scala in your own computer
The most easy way to get Scala locally is through sbt, the Scala Build Tool. You can also use an IDE that integrates sbt.
See: https://docs.scala-lang.org/getting-started/index.html to set up Scala in your own computer.
Software Engineering NOTE: You can use docker pull lamastex/dockerdev:spark3x and use the docker container for local development based on minimal pointers here: https://github.com/lamastex/dockerDev. Being able to modularise and reuse codes modularly requires the building of libraries which inturn requires building them locally with tools such as sbt or mvn for instance. You can also set-up modern IDEs like https://code.visualstudio.com/ or https://www.jetbrains.com/idea/, etc. for this.
Scala Resources
You will not be learning scala systematically and thoroughly in this course. You will learn to use Scala by doing various Spark jobs.
If you are interested in learning scala properly, then there are various resources, including:
- scala-lang.org is the core Scala resource. Bookmark the following three links:
- tour-of-scala - Bite-sized introductions to core language features.
- we will go through the tour in a hurry now as some Scala familiarity is needed immediately.
- scala-book - An online book introducing the main language features
- you are expected to use this resource to figure out Scala as needed.
- scala-cheatsheet - A handy cheatsheet covering the basics of Scala syntax.
- visual-scala-reference - This guide collects some of the most common functions of the Scala Programming Language and explain them conceptual and graphically in a simple way.
- tour-of-scala - Bite-sized introductions to core language features.
- Online Resources, including:
- Books
The main sources for the following content are (you are encouraged to read them for more background):
- Martin Oderski's Scala by example
- Scala crash course by Holden Karau
- Darren's brief introduction to scala and breeze for statistical computing
What is Scala?
"Scala smoothly integrates object-oriented and functional programming. It is designed to express common programming patterns in a concise, elegant, and type-safe way." by Matrin Odersky.
- High-level language for the Java Virtual Machine (JVM)
- Object oriented + functional programming
- Statically typed
- Comparable in speed to Java
- Type inference saves us from having to write explicit types most of the time Interoperates with Java
- Can use any Java class (inherit from, etc.)
- Can be called from Java code
See a quick tour here:
Why Scala?
- Spark was originally written in Scala, which allows concise function syntax and interactive use
- Spark APIs for other languages include:
- Java API for standalone use
- Python API added to reach a wider user community of programmes
- R API added more recently to reach a wider community of data analyststs
- Unfortunately, Python and R APIs are generally behind Spark's native Scala (for eg. GraphX is only available in Scala currently and datasets are only available in Scala as of 20200918).
- See Darren Wilkinson's 11 reasons for scala as a platform for statistical computing and data science. It is embedded in-place below for your convenience.
Scala Versus Python for Apache Spark
Read: https://www.projectpro.io/article/scala-vs-python-for-apache-spark/213 for an interesting overview.
Learn Scala in Notebook Environment
Run a Scala Cell
- Run the following scala cell.
- Note: There is no need for any special indicator (such as
%md) necessary to create a Scala cell in a Scala notebook. - You know it is a scala notebook because of the
(Scala)appended to the name of this notebook. - Make sure the cell contents updates before moving on.
- Press Shift+Enter when in the cell to run it and proceed to the next cell.
- The cells contents should update.
- Alternately, press Ctrl+Enter when in a cell to run it, but not proceed to the next cell.
- characters following
//are comments in scala. ***
1+1
res0: Int = 2
println(System.currentTimeMillis) // press Ctrl+Enter to evaluate println that prints its argument as a line
1664271977227
Let's get our hands dirty in Scala
We will go through the following programming concepts and tasks by building on https://docs.scala-lang.org/tour/basics.html.
- Scala Types
- Expressions and Printing
- Naming and Assignments
- Functions and Methods in Scala
- Classes and Case Classes
- Methods and Tab-completion
- Objects and Traits
- Collections in Scala and Type Hierarchy
- Functional Programming and MapReduce
- Lazy Evaluations and Recursions
Remark: You need to take a computer science course (from CourseEra, for example) to properly learn Scala. Here, we will learn to use Scala by example to accomplish our data science tasks at hand. You can learn more Scala as needed from various sources pointed out above in Scala Resources.
Scala Types
In Scala, all values have a type, including numerical values and functions. The diagram below illustrates a subset of the type hierarchy.

For now, notice some common types we will be usinf including Int, String, Double, Unit, Boolean, List, etc. For more details see https://docs.scala-lang.org/tour/unified-types.html. We will return to this at the end of the notebook after seeing a brief tour of Scala now.
Expressions
Expressions are computable statements such as the 1+1 we have seen before.
1+1
res2: Int = 2
We can print the output of a computed or evaluated expressions as a line using println:
println(1+1) // printing 2
2
println("hej hej!") // printing a string
hej hej!
Naming and Assignments
value and variable as val and var
You can name the results of expressions using keywords val and var.
Let us assign the integer value 5 to x as follows:
val x : Int = 5 // <Ctrl+Enter> to declare a value x to be integer 5.
x: Int = 5
x is a named result and it is a value since we used the keyword val when naming it.
Scala is statically typed, but it uses built-in type inference machinery to automatically figure out that x is an integer or Int type as follows. Let's declare a value x to be Int 5 next without explictly using Int.
val x = 5 // <Ctrl+Enter> to declare a value x as Int 5 (type automatically inferred)
x: Int = 5
Let's declare x as a Double or double-precision floating-point type using decimal such as 5.0 (a digit has to follow the decimal point!)
val x = 5.0 // <Ctrl+Enter> to declare a value x as Double 5
x: Double = 5.0
Alternatively, we can assign x as a Double explicitly. Note that the decimal point is not needed in this case due to explicit typing as Double.
val x : Double = 5 // <Ctrl+Enter> to declare a value x as Double 5 (type automatically inferred)
x: Double = 5.0
Next note that labels need to be declared on first use. We have declared x to be a val which is short for value. This makes x immutable (cannot be changed).
Thus, x cannot be just re-assigned, as the following code illustrates in the resulting error: ... error: reassignment to val.
//x = 10 // uncomment and <Ctrl+Enter> to try to reassign val x to 10
Scala allows declaration of mutable variables as well using var, as follows:
var y = 2 // <Shift+Enter> to declare a variable y to be integer 2 and go to next cell
y: Int = 2
y = 3 // <Shift+Enter> to change the value of y to 3
y: Int = 3
y = y+1 // adds 1 to y
y: Int = 4
y += 2 // adds 2 to y
println(y) // the var y is 6 now
6
Blocks
Just combine expressions by surrounding them with { and } called a block.
println({
val x = 1+1
x+2 // expression in last line is returned for the block
})// prints 4
4
println({ val x=22; x+2})
24
Functions
Functions are expressions that have parameters. A function takes arguments as input and returns expressions as output.
A function can be nameless or anonymous and simply return an output from a given input. For example, the following annymous function returns the square of the input integer.
(x: Int) => x*x
res10: Int => Int = $Lambda$5453/989605864@15857286
On the left of => is a list of parameters with name and type. On the right is an expression involving the parameters.
You can also name functions:
val multiplyByItself = (x: Int) => x*x
multiplyByItself: Int => Int = $Lambda$5454/1749476144@41de911a
println(multiplyByItself(10))
100
A function can have no parameters:
val howManyAmI = () => 1
howManyAmI: () => Int = $Lambda$5457/1325610144@72b8fd99
println(howManyAmI()) // 1
1
A function can have more than one parameter:
val multiplyTheseTwoIntegers = (a: Int, b: Int) => a*b
multiplyTheseTwoIntegers: (Int, Int) => Int = $Lambda$5458/1327542156@7adcf443
println(multiplyTheseTwoIntegers(2,4)) // 8
8
Methods
Methods are very similar to functions, but a few key differences exist.
Methods use the def keyword followed by a name, parameter list(s), a return type, and a body.
def square(x: Int): Int = x*x // <Shitf+Enter> to define a function named square
square: (x: Int)Int
Note that the return type Int is specified after the parameter list and a :.
square(5) // <Shitf+Enter> to call this function on argument 5
res14: Int = 25
val y = 3 // <Shitf+Enter> make val y as Int 3
y: Int = 3
square(y) // <Shitf+Enter> to call the function on val y of the right argument type Int
res15: Int = 9
val x = 5.0 // let x be Double 5.0
x: Double = 5.0
//square(x) // <Shift+Enter> to call the function on val x of type Double will give type mismatch error
def square(x: Int): Int = { // <Shitf+Enter> to declare function in a block
val answer = x*x
answer // the last line of the function block is returned
}
square: (x: Int)Int
square(5000) // <Shift+Enter> to call the function
res17: Int = 25000000
// <Shift+Enter> to define function with input and output type as String
def announceAndEmit(text: String): String =
{
println(text)
text // the last line of the function block is returned
}
announceAndEmit: (text: String)String
Scala has a return keyword but it is rarely used as the expression in the last line of the multi-line block is the method's return value.
// <Ctrl+Enter> to call function which prints as line and returns as String
announceAndEmit("roger roger")
roger roger
res18: String = roger roger
A method can have output expressions involving multiple parameter lists:
def multiplyAndTranslate(x: Int, y: Int)(translateBy: Int): Int = (x * y) + translateBy
multiplyAndTranslate: (x: Int, y: Int)(translateBy: Int)Int
println(multiplyAndTranslate(2, 3)(4)) // (2*3)+4 = 10
10
A method can have no parameter lists at all:
def time: Long = System.currentTimeMillis
time: Long
println("Current time in milliseconds is " + time)
Current time in milliseconds is 1664271993372
println("Current time in milliseconds is " + time)
Current time in milliseconds is 1664271993681
Classes
The class keyword followed by the name and constructor parameters is used to define a class.
class Box(h: Int, w: Int, d: Int) {
def printVolume(): Unit = println(h*w*d)
}
defined class Box
- The return type of the method
printVolumeisUnit. - When the return type is
Unitit indicates that there is nothing meaningful to return, similar tovoidin Java and C, but with a difference. - Because every Scala expression must have some value, there is actually a singleton value of type
Unit, written()and carrying no information.
We can make an instance of the class with the new keyword.
val my1Cube = new Box(1,1,1)
my1Cube: Box = Box@2f0a334c
And call the method on the instance.
my1Cube.printVolume() // 1
1
Our named instance my1Cube of the Box class is immutable due to val.
You can have mutable instances of the class using var.
var myVaryingCuboid = new Box(1,3,2)
myVaryingCuboid: Box = Box@41dfc388
myVaryingCuboid.printVolume()
6
myVaryingCuboid = new Box(1,1,1)
myVaryingCuboid: Box = Box@3b1898db
myVaryingCuboid.printVolume()
1
See https://docs.scala-lang.org/tour/classes.html for more details as needed.
Case Classes
Scala has a special type of class called a case class that can be defined with the case class keyword.
Unlike classes, whose instances are compared by reference, instances of case classes are immutable by default and compared by value. This makes them useful for defining rows of typed values in Spark.
case class Point(x: Int, y: Int, z: Int)
defined class Point
Case classes can be instantiated without the new keyword.
val point = Point(1, 2, 3)
val anotherPoint = Point(1, 2, 3)
val yetAnotherPoint = Point(2, 2, 2)
point: Point = Point(1,2,3)
anotherPoint: Point = Point(1,2,3)
yetAnotherPoint: Point = Point(2,2,2)
Instances of case classes are compared by value and not by reference.
if (point == anotherPoint) {
println(point + " and " + anotherPoint + " are the same.")
} else {
println(point + " and " + anotherPoint + " are different.")
} // Point(1,2,3) and Point(1,2,3) are the same.
if (point == yetAnotherPoint) {
println(point + " and " + yetAnotherPoint + " are the same.")
} else {
println(point + " and " + yetAnotherPoint + " are different.")
} // Point(1,2,3) and Point(2,2,2) are different.
Point(1,2,3) and Point(1,2,3) are the same.
Point(1,2,3) and Point(2,2,2) are different.
By contrast, instances of classes are compared by reference.
myVaryingCuboid.printVolume() // should be 1 x 1 x 1
1
my1Cube.printVolume() // should be 1 x 1 x 1
1
if (myVaryingCuboid == my1Cube) {
println("myVaryingCuboid and my1Cube are the same.")
} else {
println("myVaryingCuboid and my1Cube are different.")
} // they are compared by reference and are not the same.
myVaryingCuboid and my1Cube are different.
More about case classes here: https://docs.scala-lang.org/tour/case-classes.html.
Methods and Tab-completion
Many methods of a class can be accessed by ..
val s = "hi" // <Ctrl+Enter> to declare val s to String "hi"
s: String = hi
You can place the cursor after . following a declared object and find out the methods available for it as shown in the image below.

You Try doing this next.
//s. // place cursor after the '.' and press Tab to see all available methods for s
For example,
- scroll down to
containsand double-click on it. - This should lead to
s.containsin your cell. - Now add an argument String to see if
scontains the argument, for example, try:s.contains("f")s.contains("")ands.contains("i")
//s // <Shift-Enter> recall the value of String s
s.contains("f") // <Shift-Enter> returns Boolean false since s does not contain the string "f"
res31: Boolean = false
s.contains("") // <Shift-Enter> returns Boolean true since s contains the empty string ""
res32: Boolean = true
s.contains("i") // <Ctrl+Enter> returns Boolean true since s contains the string "i"
res33: Boolean = true
Objects
Objects are single instances of their own definitions using the object keyword. You can think of them as singletons of their own classes.
object IdGenerator {
private var currentId = 0
def make(): Int = {
currentId += 1
currentId
}
}
defined object IdGenerator
You can access an object through its name:
val newId: Int = IdGenerator.make()
val newerId: Int = IdGenerator.make()
newId: Int = 1
newerId: Int = 2
println(newId) // 1
println(newerId) // 2
1
2
For details see https://docs.scala-lang.org/tour/singleton-objects.html
Traits
Traits are abstract data types containing certain fields and methods. They can be defined using the trait keyword.
In Scala inheritance, a class can only extend one other class, but it can extend multiple traits.
trait Greeter {
def greet(name: String): Unit
}
defined trait Greeter
Traits can have default implementations also.
trait Greeter {
def greet(name: String): Unit =
println("Hello, " + name + "!")
}
defined trait Greeter
You can extend traits with the extends keyword and override an implementation with the override keyword:
class DefaultGreeter extends Greeter
class SwedishGreeter extends Greeter {
override def greet(name: String): Unit = {
println("Hej hej, " + name + "!")
}
}
class CustomizableGreeter(prefix: String, postfix: String) extends Greeter {
override def greet(name: String): Unit = {
println(prefix + name + postfix)
}
}
defined class DefaultGreeter
defined class SwedishGreeter
defined class CustomizableGreeter
Instantiate the classes.
val greeter = new DefaultGreeter()
val swedishGreeter = new SwedishGreeter()
val customGreeter = new CustomizableGreeter("How are you, ", "?")
greeter: DefaultGreeter = DefaultGreeter@737bf119
swedishGreeter: SwedishGreeter = SwedishGreeter@6bdaad03
customGreeter: CustomizableGreeter = CustomizableGreeter@4564c74a
Call the greet method in each case.
greeter.greet("Scala developer") // Hello, Scala developer!
swedishGreeter.greet("Scala developer") // Hej hej, Scala developer!
customGreeter.greet("Scala developer") // How are you, Scala developer?
Hello, Scala developer!
Hej hej, Scala developer!
How are you, Scala developer?
A class can also be made to extend multiple traits.
For more details see: https://docs.scala-lang.org/tour/traits.html.
Main Method
The main method is the entry point of a Scala program.
The Java Virtual Machine requires a main method, named main, that takes an array of strings as its only argument.
Using an object, you can define the main method as follows:
object Main {
def main(args: Array[String]): Unit =
println("Hello, Scala developer!")
}
defined object Main
What I try not do while learning a new language?
- I don't immediately try to ask questions like: how can I do this particular variation of some small thing I just learned so I can use patterns I am used to from another language I am hooked-on right now?
- first go through the detailed Scala Tour on your own and then through the 50 odd lessons in the Scala Book
- then return to 1. and ask detailed cross-language comparison questions by diving deep as needed with the source and scala docs as needed (google or duck-duck-go search!).
Scala Crash Course Continued
Recall!
Scala Resources
You will not be learning scala systematically and thoroughly in this course. You will learn to use Scala by doing various Spark jobs.
If you are interested in learning scala properly, then there are various resources, including:
- scala-lang.org is the core Scala resource. Bookmark the following three links:
- tour-of-scala - Bite-sized introductions to core language features.
- we will go through the tour in a hurry now as some Scala familiarity is needed immediately.
- scala-book - An online book introducing the main language features
- you are expected to use this resource to figure out Scala as needed.
- scala-cheatsheet - A handy cheatsheet covering the basics of Scala syntax.
- visual-scala-reference - This guide collects some of the most common functions of the Scala Programming Language and explain them conceptual and graphically in a simple way.
- tour-of-scala - Bite-sized introductions to core language features.
- Online Resources, including:
- Books
The main sources for the following content are (you are encouraged to read them for more background):
Let's continue getting our hands dirty in Scala
We will go through the remaining programming concepts and tasks by building on https://docs.scala-lang.org/tour/basics.html.
- Scala Types
- Expressions and Printing
- Naming and Assignments
- Functions and Methods in Scala
- Classes and Case Classes
- Methods and Tab-completion
- Objects and Traits
- Collections in Scala and Type Hierarchy
- Functional Programming and MapReduce
- Lazy Evaluations and Recursions
Remark: You need to take a computer science course (from CourseEra, for example) to properly learn Scala. Here, we will learn to use Scala by example to accomplish our data science tasks at hand. You can learn more Scala as needed from various sources pointed out above in Scala Resources.
Scala Type Hierarchy
In Scala, all values have a type, including numerical values and functions. The diagram below illustrates a subset of the type hierarchy.
For now, notice some common types we will be usinf including Int, String, Double, Unit, Boolean, List, etc.
Let us take a closer look at Scala Type Hierarchy now here:
Scala Collections
Familiarize yourself with the main Scala collections classes here:
List
Lists are one of the most basic data structures.
There are several other Scala collections and we will introduce them as needed. The other most common ones are Vector, Array and Seq and the ArrayBuffer.
For details on list see: - https://docs.scala-lang.org/overviews/scala-book/list-class.html
// <Ctrl+Enter> to declare (an immutable) val lst as List of Int's 1,2,3
val lst = List(1, 2, 3)
lst: List[Int] = List(1, 2, 3)
Vectors
The Vector class is an indexed, immutable sequence. The “indexed” part of the description means that you can access Vector elements very rapidly by their index value, such as accessing listOfPeople(999999).
In general, except for the difference that Vector is indexed and List is not, the two classes work the same, so we’ll run through these examples quickly.
For details see: - https://docs.scala-lang.org/overviews/scala-book/vector-class.html
val vec = Vector(1,2,3)
vec: scala.collection.immutable.Vector[Int] = Vector(1, 2, 3)
vec(0) // access first element with index 0
res0: Int = 1
Arrays, Sequences and Tuples
See https://www.scala-lang.org/api/current/scala/collection/index.html for docs.
val arr = Array(1,2,3) // <Shift-Enter> to declare an Array
arr: Array[Int] = Array(1, 2, 3)
val seq = Seq(1,2,3) // <Shift-Enter> to declare a Seq
seq: Seq[Int] = List(1, 2, 3)
A tuple is a neat class that gives you a simple way to store heterogeneous (different) items in the same container. We will use tuples for key-value pairs in Spark.
See https://docs.scala-lang.org/overviews/scala-book/tuples.html
val myTuple = ('a',1) // a 2-tuple
myTuple: (Char, Int) = (a,1)
myTuple._1 // accessing the first element of the tuple. NOTE index starts at 1 not 0 for tuples
res1: Char = a
myTuple._2 // accessing the second element of the tuple
res2: Int = 1
Functional Programming and MapReduce
"Functional programming is a style of programming that emphasizes writing applications using only pure functions and immutable values. As Alvin Alexander wrote in Functional Programming, Simplified, rather than using that description, it can be helpful to say that functional programmers have an extremely strong desire to see their code as math — to see the combination of their functions as a series of algebraic equations. In that regard, you could say that functional programmers like to think of themselves as mathematicians. That’s the driving desire that leads them to use only pure functions and immutable values, because that’s what you use in algebra and other forms of math."
See https://docs.scala-lang.org/overviews/scala-book/functional-programming.html for short lessons in functional programming.
We will apply functions for processing elements of a scala collection to quickly demonstrate functional programming.
Five ways of adding 1
The first four use anonymous functions and the last one uses a named method.
- explicit version:
(x: Int) => x + 1
- type-inferred more intuitive version:
x => x + 1
- placeholder syntax (each argument must be used exactly once):
_ + 1
- type-inferred more intuitive version with code-block for larger function body:
x => {
// body is a block of code
val integerToAdd = 1
x + integerToAdd
}
- as methods using
def:
def addOne(x: Int): Int = x + 1
Now, let's do some functional programming over scala collection (List) using some of their methods: map, filter and reduce. In the end we will write our first mapReduce program!
For more details see:
map
See: https://superruzafa.github.io/visual-scala-reference/map/
trait Collection[A] {
def map[B](f: (A) => B): Collection[B]
}
map creates a collection using as elements the results obtained from applying the function f to each element of this collection.

// <Shift+Enter> to map each value x of lst with x+10 to return a new List(11, 12, 13)
lst.map(x => x + 10)
res3: List[Int] = List(11, 12, 13)
// <Shift+Enter> for the same as above using place-holder syntax
lst.map( _ + 10)
res4: List[Int] = List(11, 12, 13)
filter
See: https://superruzafa.github.io/visual-scala-reference/filter/
trait Collection[A] {
def filter(p: (A) => Boolean): Collection[A]
}
filter creates a collection with those elements that satisfy the predicate p and discarding the rest.

// <Shift+Enter> to return a new List(1, 3) after filtering x's from lst if (x % 2 == 1) is true
lst.filter(x => (x % 2 == 1) )
res5: List[Int] = List(1, 3)
// <Shift+Enter> for the same as above using place-holder syntax
lst.filter( _ % 2 == 1 )
res6: List[Int] = List(1, 3)
reduce
See: https://superruzafa.github.io/visual-scala-reference/reduce/
trait Collection[A] {
def reduce(op: (A, A) => A): A
}
reduce applies the binary operator op to pairs of elements in this collection until the final result is calculated.

// <Shift+Enter> to use reduce to add elements of lst two at a time to return Int 6
lst.reduce( (x, y) => x + y )
res7: Int = 6
// <Ctrl+Enter> for the same as above but using place-holder syntax
lst.reduce( _ + _ )
res8: Int = 6
Let's combine map and reduce programs above to find the sum of after 10 has been added to every element of the original List lst as follows:
lst.map(x => x+10)
.reduce((x,y) => x+y) // <Ctrl-Enter> to get Int 36 = sum(1+10,2+10,3+10)
res9: Int = 36
Exercise in Functional Programming
You should spend an hour or so going through the Functional Programming Section of the Scala Book:
Scala lets you write code in an object-oriented programming (OOP) style, a functional programming (FP) style, and even in a hybrid style, using both approaches in combination. This book assumes that you’re coming to Scala from an OOP language like Java, C++, or C#, so outside of covering Scala classes, there aren’t any special sections about OOP in this book. But because the FP style is still relatively new to many developers, we’ll provide a brief introduction to Scala’s support for FP in the next several lessons.
Functional programming is a style of programming that emphasizes writing applications using only pure functions and immutable values. As Alvin Alexander wrote in Functional Programming, Simplified, rather than using that description, it can be helpful to say that functional programmers have an extremely strong desire to see their code as math — to see the combination of their functions as a series of algebraic equations. In that regard, you could say that functional programmers like to think of themselves as mathematicians. That’s the driving desire that leads them to use only pure functions and immutable values, because that’s what you use in algebra and other forms of math.
Functional programming is a large topic, and there’s no simple way to condense the entire topic into this little book, but in the following lessons we’ll give you a taste of FP, and show some of the tools Scala provides for developers to write functional code.
There are lots of methods in Scala Collections. And much more in this scalable language. See for example http://docs.scala-lang.org/cheatsheets/index.html.
Lazy Evaluation
Another powerful programming concept we will need is lazy evaluation -- a form of delayed evaluation. So the value of an expression that is lazily evaluated is only available when it is actually needed.
This is to be contrasted with eager evaluation that we have seen so far -- an expression is immediately evaluated.
val eagerImmutableInt = 1 // eagerly evaluated as 1
eagerImmutableInt: Int = 1
var eagerMutableInt = 2 // eagerly evaluated as 2
eagerMutableInt: Int = 2
Let's demonstrate lazy evaluation using a getTime method and the keyword lazy.
import java.util.Calendar
import java.util.Calendar
lazy val lazyImmutableTime = Calendar.getInstance.getTime // lazily defined and not evaluated immediately
lazyImmutableTime: java.util.Date = <lazy>
val eagerImmutableTime = Calendar.getInstance.getTime // egaerly evaluated immediately
eagerImmutableTime: java.util.Date = Tue Sep 27 09:49:49 UTC 2022
println(lazyImmutableTime) // evaluated when actully needed by println
Tue Sep 27 09:49:49 UTC 2022
println(eagerImmutableTime) // prints what was already evaluated eagerly
Tue Sep 27 09:49:49 UTC 2022
def lazyDefinedInt = 5 // you can also use method to lazily define
lazyDefinedInt: Int
lazyDefinedInt // only evaluated now
res12: Int = 5
See https://www.scala-exercises.org/scalatutorial/lazyevaluation for more details including the following example with StringBuilder.
val builder = new StringBuilder //built-in
builder: StringBuilder =
builder.result()
res13: String = ""
val x = { builder += 'x'; 1 } // eagerly evaluates x as 1 after appending 'x' to builder. NOTE: ';' is used to separate multiple expressions on the same line
x: Int = 1
builder.result()
res14: String = x
x
res15: Int = 1
builder.result() // calling x again should not append x again to builder
res16: String = x
lazy val y = { builder += 'y'; 2 } // lazily evaluate y later when it is called
y: Int = <lazy>
builder.result() // builder should remain unchanged
res17: String = x
def z = { builder += 'z'; 3 } // lazily evaluate z later when the method is called
z: Int
builder.result() // builder should remain unchanged
res18: String = x
What should builder.result() be after the following arithmetic expression involving x,y and z is evaluated?
z + y + x + z + y + x
res19: Int = 12
Lazy Evaluation Exercise - You try Now!
Understand why the output above is what it is!
- Why is
zdifferent in its appearance in the finalbuilderstring when compared toxandyas we evaluated?
z + y + x + z + y + x
// putting it all together
val builder = new StringBuilder
val x = { builder += 'x'; 1 }
lazy val y = { builder += 'y'; 2 }
def z = { builder += 'z'; 3 }
// comment next line after different summands to understand difference between val, lazy val and def
z + y + x + z + y + x
builder.result()
builder: StringBuilder = xzyz
x: Int = 1
y: Int = <lazy>
z: Int
res20: String = xzyz
Why Lazy?
Imagine a more complex expression involving the evaluation of millions of values. Lazy evaluation will allow us to actually compute with big data when it may become impossible to hold all the values in memory. This is exactly what Apache Spark does as we will see.
Recursions
Recursion is a powerful framework when a function calls another function, including itself, until some terminal condition is reached.
Here we want to distinguish between two ways of implementing a recursion using a simple example of factorial.
Recall that for any natural number \(n\), its factorial is denoted and defined as follows:
\[ n! := n \times (n-1) \times (n-2) \times \cdots \times 2 \times 1 \]
which has the following recursive expression:
\[ n! = n*(n-1)! , , \qquad 0! = 1 \]
Let us implement it using two approaches: a naive approach that can run out of memory and another tail-recursive approach that uses constant memory. Read https://www.scala-exercises.org/scalatutorial/tailrecursion for details.
def factorialNaive(n: Int): Int =
if (n == 0) 1 else n * factorialNaive(n - 1)
factorialNaive: (n: Int)Int
factorialNaive(4)
res21: Int = 24
When factorialNaive(4) was evaluated above the following steps were actually done:
factorial(4)
if (4 == 0) 1 else 4 * factorial(4 - 1)
4 * factorial(3)
4 * (3 * factorial(2))
4 * (3 * (2 * factorial(1)))
4 * (3 * (2 * (1 * factorial(0)))
4 * (3 * (2 * (1 * 1)))
24
Notice how we add one more element to our expression at each recursive call. Our expressions becomes bigger and bigger until we end by reducing it to the final value. So the final expression given by a directed acyclic graph (DAG) of the pairwise multiplications given by the right-branching binary tree, whose leaves are input integers and internal nodes are the bianry * operator, can get very large when the input n is large.
Tail recursion is a sophisticated way of implementing certain recursions so that memory requirements can be kept constant, as opposed to naive recursions.
That difference in the rewriting rules actually translates directly to a difference in the actual execution on a computer. In fact, it turns out that if you have a recursive function that calls itself as its last action, then you can reuse the stack frame of that function. This is called tail recursion.
And by applying that trick, a tail recursive function can execute in constant stack space, so it's really just another formulation of an iterative process. We could say a tail recursive function is the functional form of a loop, and it executes just as efficiently as a loop.
Implementation of tail recursion in the Exercise below uses Scala annotation, which is a way to associate meta-information with definitions. In our case, the annotation @tailrec ensures that a method is indeed tail-recursive. See the last link to understand how memory requirements can be kept constant in tail recursions.
We mainly want you to know that tail recursions are an important functional programming concept.
Tail Recursion Exercise - You Try Now
- Uncomment the next three cells
- Replace
???in the next cell with the correct values to make this a tail recursion for factorial.
/*
import scala.annotation.tailrec
// replace ??? with the right values to make this a tail recursion for factorial
def factorialTail(n: Int): Int = {
@tailrec
def iter(x: Int, result: Int): Int =
if ( x == ???) result
else iter(x - 1, result * x)
iter( n, ??? )
}
*/
//factorialTail(3) //shouldBe 6
//factorialTail(4) //shouldBe 24
Functional Programming is a vast subject and we are merely covering the fewest core ideas to get started with Apache Spark asap.
We will return to more concepts as we need them in the sequel.
Introduction to Spark
Spark Essentials: RDDs, Transformations and Actions
- This introductory notebook describes how to get started running Spark (Scala) code in Notebooks.
- Working with Spark's Resilient Distributed Datasets (RDDs)
- creating RDDs
- performing basic transformations on RDDs
- performing basic actions on RDDs
RECOLLECT from 001_WhySpark notebook that Spark does fault-tolerant, distributed, in-memory computing
THEORY CAVEAT This module is focused on getting you to quickly write Spark programs with a high-level appreciation of the underlying concepts.
In the last module, we will spend more time on analyzing the core algorithms in parallel and distributed setting of a typical Spark cluster today -- where several multi-core parallel computers (Spark workers) are networked together to provide a fault-tolerant distributed computing platform.
Spark Cluster Overview:
Driver Program, Cluster Manager and Worker Nodes
The driver does the following:
- connects to a cluster manager to allocate resources across applications
- acquire executors on cluster nodes
- executor processs run compute tasks and cache data in memory or disk on a worker node
- sends application (user program built on Spark) to the executors
- sends tasks for the executors to run
- task is a unit of work that will be sent to one executor

See http://spark.apache.org/docs/latest/cluster-overview.html for an overview of the spark cluster.
The Abstraction of Resilient Distributed Dataset (RDD)
RDD is a fault-tolerant collection of elements that can be operated on in parallel.
Key Points to Note
- Resilient distributed datasets (RDDs) are the primary abstraction in Spark.
- RDDs are immutable once created:
- can transform it.
- can perform actions on it.
- but cannot change an RDD once you construct it.
- Spark tracks each RDD's lineage information or recipe to enable its efficient recomputation if a machine fails.
- RDDs enable operations on collections of elements in parallel.
- We can construct RDDs by:
- parallelizing Scala collections such as lists or arrays
- by transforming an existing RDD,
- from files in distributed file systems such as (HDFS, S3, etc.).
- We can specify the number of partitions for an RDD
- The more partitions in an RDD, the more opportunities for parallelism
- There are two types of operations you can perform on an RDD:
- transformations (are lazily evaluated)
- map
- flatMap
- filter
- distinct
- ...
- actions (actual evaluation happens)
- count
- reduce
- take
- collect
- takeOrdered
- ...
- transformations (are lazily evaluated)
- Spark transformations enable us to create new RDDs from an existing RDD.
- RDD transformations are lazy evaluations (results are not computed right away)
- Spark remembers the set of transformations that are applied to a base data set (this is the lineage graph of RDD)
- The allows Spark to automatically recover RDDs from failures and slow workers.
- The lineage graph is a recipe for creating a result and it can be optimized before execution.
- A transformed RDD is executed only when an action runs on it.
- You can also persist, or cache, RDDs in memory or on disk (this speeds up iterative ML algorithms that transforms the initial RDD iteratively).
- Here is a great reference URL for programming guides for Spark that one should try to cover first
//This allows easy embedding of publicly available information into any other notebook
//Example usage:
// displayHTML(frameIt("https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation#Topics_in_LDA",250))
def frameIt( u:String, h:Int ) : String = {
"""<iframe
src=""""+ u+""""
width="95%" height="""" + h + """"
sandbox>
<p>
<a href="http://spark.apache.org/docs/latest/index.html">
Fallback link for browsers that, unlikely, don't support frames
</a>
</p>
</iframe>"""
}
displayHTML(frameIt("https://spark.apache.org/docs/latest/rdd-programming-guide.html",700))
Let's get our hands dirty in Spark!
DO NOW!
There is a peer-reviewed Assignment where you will dig deeper into Spark transformations and actions.
Let us look at the legend and overview of the visual RDD Api by doing the following first:
Running Spark
The variable sc allows you to access a Spark Context to run your Spark programs. Recall SparkContext is in the Driver Program.
**NOTE: Do not create the sc variable - it is already initialized for you in spark-shell REPL, that includes notebook environments like databricks, Jupyter, zeppelin, etc. **
We will do the following next:
- Create an RDD using
sc.parallelize
- Perform the
collectaction on the RDD and find the number of partitions it is made of usinggetNumPartitionsaction - Perform the
takeaction on the RDD - Transform the RDD by
mapto make another RDD - Transform the RDD by
filterto make another RDD - Perform the
reduceaction on the RDD - Transform the RDD by
flatMapto make another RDD - Create a Pair RDD
- Perform some transformations on a Pair RDD
- Where in the cluster is your computation running?
- Shipping Closures, Broadcast Variables and Accumulator Variables
- Spark Essentials: Summary
- HOMEWORK
- Importing Standard Scala and Java libraries
Entry Point
Now we are ready to start programming in Spark!
Our entry point for Spark applications is the class SparkSession. An instance of this object is already instantiated for us which can be easily demonstrated by running the next cell
We will need these docs!
- RDD Scala Docs
- Dataset Scala Docs
- https://spark.apache.org/docs/3.0.1/api/scala/index.html you can simply search for other Spark classes, methods, etc here
println(spark) // spark is already created for us in databricks or in spark-shell
org.apache.spark.sql.SparkSession@1b6fb477
NOTE that since Spark 2.0 SparkSession is a replacement for the other entry points: * SparkContext, available in our notebook as sc. * SQLContext, or more specifically its subclass HiveContext, available in our notebook as sqlContext.
println(sc)
println(sqlContext)
org.apache.spark.SparkContext@61cc1a6b
org.apache.spark.sql.hive.HiveContext@1da4f2b4
We will be using the pre-made SparkContext sc when learning about RDDs.
1. Create an RDD using sc.parallelize
First, let us create an RDD of three elements (of integer type Int) from a Scala Seq (or List or Array) with two partitions by using the parallelize method of the available Spark Context sc as follows:
val x = sc.parallelize(Array(1, 2, 3), 2) // <Ctrl+Enter> to evaluate this cell (using 2 partitions)
x: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at command-4088905069026221:1
//x. // place the cursor after 'x.' and hit Tab to see the methods available for the RDD x we created
2. Perform the collect action on the RDD and find the number of partitions in it using getNumPartitions action
No action has been taken by sc.parallelize above. To see what is "cooked" by the recipe for RDD x we need to take an action.
The simplest is the collect action which returns all of the elements of the RDD as an Array to the driver program and displays it.
So you have to make sure that all of that data will fit in the driver program if you call collect action!
Let us look at the collect action in detail and return here to try out the example codes.
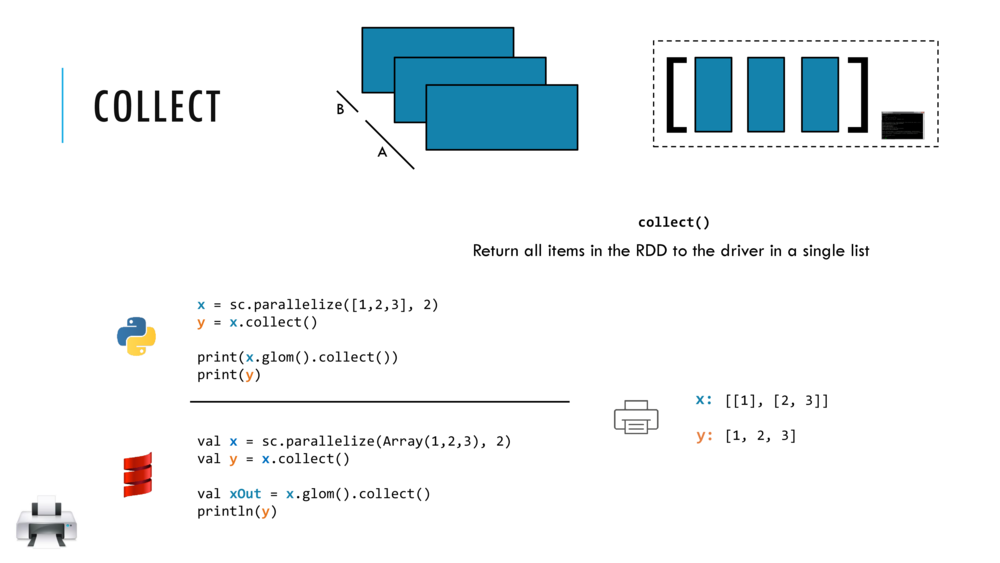
Let us perform a collect action on RDD x as follows:
x.collect() // <Ctrl+Enter> to collect (action) elements of rdd; should be (1, 2, 3)
res4: Array[Int] = Array(1, 2, 3)
CAUTION: collect can crash the driver when called upon an RDD with massively many elements.
So, it is better to use other diplaying actions like take or takeOrdered as follows:
Let us look at the getNumPartitions action in detail and return here to try out the example codes.
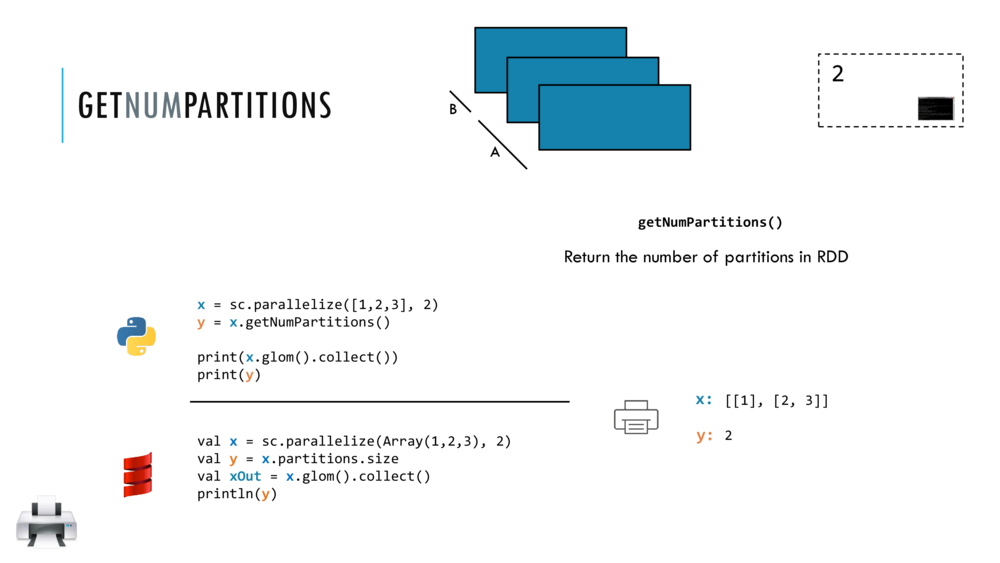
// <Ctrl+Enter> to evaluate this cell and find the number of partitions in RDD x
x.getNumPartitions
res5: Int = 2
We can see which elements of the RDD are in which parition by calling glom() before collect().
glom() flattens elements of the same partition into an Array.
x.glom().collect() // glom() flattens elements on the same partition
res6: Array[Array[Int]] = Array(Array(1), Array(2, 3))
val a = x.glom().collect()
a: Array[Array[Int]] = Array(Array(1), Array(2, 3))
Thus from the output above, Array[Array[Int]] = Array(Array(1), Array(2, 3)), we know that 1 is in one partition while 2 and 3 are in another partition.
You Try!
Crate an RDD x with three elements, 1,2,3, and this time do not specifiy the number of partitions. Then the default number of partitions will be used. Find out what this is for the cluster you are attached to.
The default number of partitions for an RDD depends on the cluster this notebook is attached to among others - see programming-guide.
val x = sc.parallelize(Seq(1, 2, 3)) // <Shift+Enter> to evaluate this cell (using default number of partitions)
x: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at command-4088905069026235:1
x.getNumPartitions // <Shift+Enter> to evaluate this cell
res7: Int = 2
x.glom().collect() // <Ctrl+Enter> to evaluate this cell
res8: Array[Array[Int]] = Array(Array(1), Array(2, 3))
3. Perform the take action on the RDD
The .take(n) action returns an array with the first n elements of the RDD.
x.take(2) // Ctrl+Enter to take two elements from the RDD x
res9: Array[Int] = Array(1, 2)
You Try!
Fill in the parenthes ( ) below in order to take just one element from RDD x.
//x.take(1) // uncomment by removing '//' before x in the cell and fill in the parenthesis to take just one element from RDD x and Cntrl+Enter
4. Transform the RDD by map to make another RDD
The map transformation returns a new RDD that's formed by passing each element of the source RDD through a function (closure). The closure is automatically passed on to the workers for evaluation (when an action is called later).
Let us look at the map transformation in detail and return here to try out the example codes.
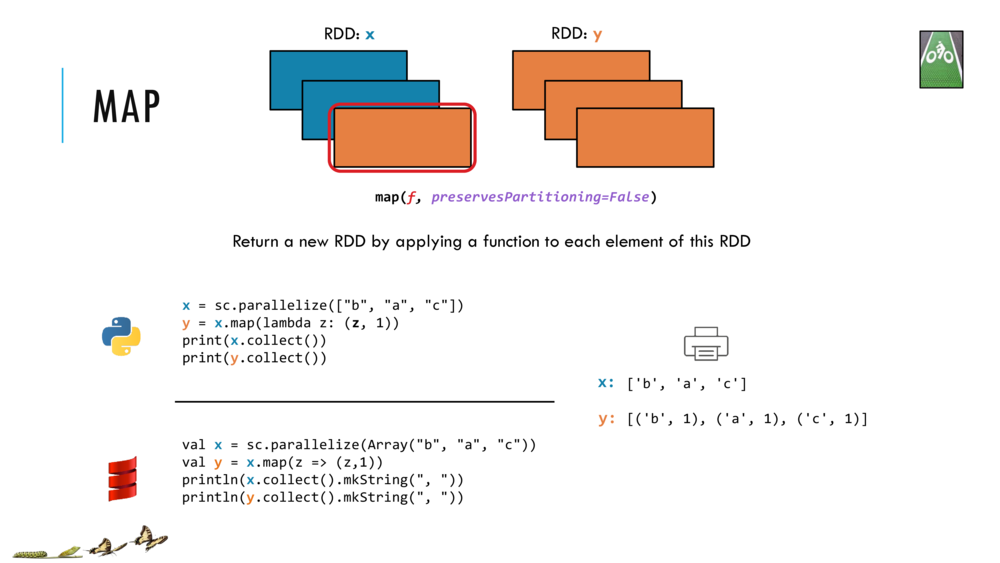
// Shift+Enter to make RDD x and RDD y that is mapped from x
val x = sc.parallelize(Array("b", "a", "c")) // make RDD x: [b, a, c]
val y = x.map(z => (z,1)) // map x into RDD y: [(b, 1), (a, 1), (c, 1)]
x: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[5] at parallelize at command-4088905069026244:2
y: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[6] at map at command-4088905069026244:3
// Cntrl+Enter to collect and print the two RDDs
println(x.collect().mkString(", "))
println(y.collect().mkString(", "))
b, a, c
(b,1), (a,1), (c,1)
5. Transform the RDD by filter to make another RDD
The filter transformation returns a new RDD that's formed by selecting those elements of the source RDD on which the function returns true.
Let us look at the filter transformation in detail and return here to try out the example codes.
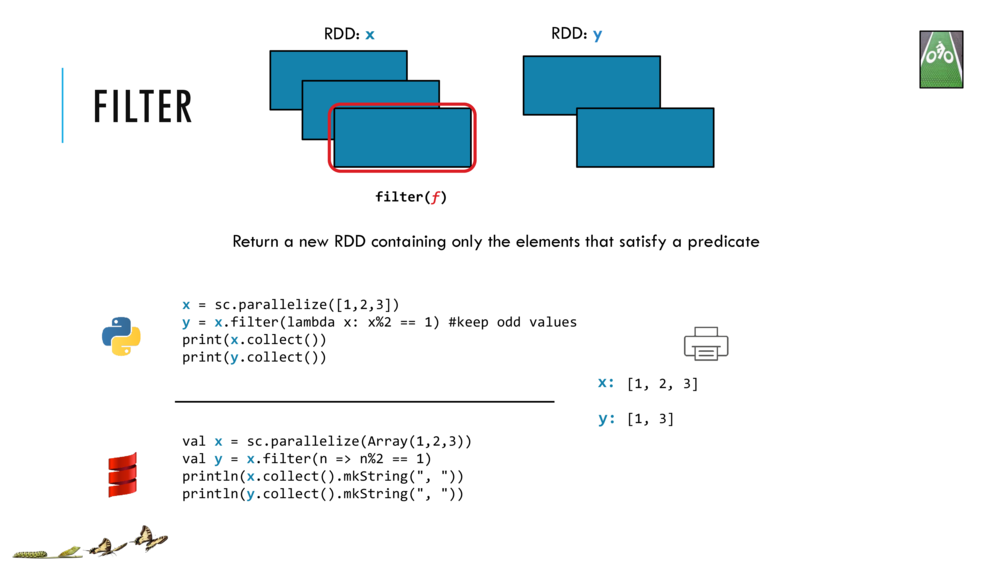
//Shift+Enter to make RDD x and filter it by (n => n%2 == 1) to make RDD y
val x = sc.parallelize(Array(1,2,3))
// the closure (n => n%2 == 1) in the filter will
// return True if element n in RDD x has remainder 1 when divided by 2 (i.e., if n is odd)
val y = x.filter(n => n%2 == 1)
x: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[7] at parallelize at command-4088905069026248:2
y: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[8] at filter at command-4088905069026248:5
// Cntrl+Enter to collect and print the two RDDs
println(x.collect().mkString(", "))
println(y.collect().mkString(", "))
//y.collect()
1, 2, 3
1, 3
6. Perform the reduce action on the RDD
Reduce aggregates a data set element using a function (closure). This function takes two arguments and returns one and can often be seen as a binary operator. This operator has to be commutative and associative so that it can be computed correctly in parallel (where we have little control over the order of the operations!).
Let us look at the reduce action in detail and return here to try out the example codes.
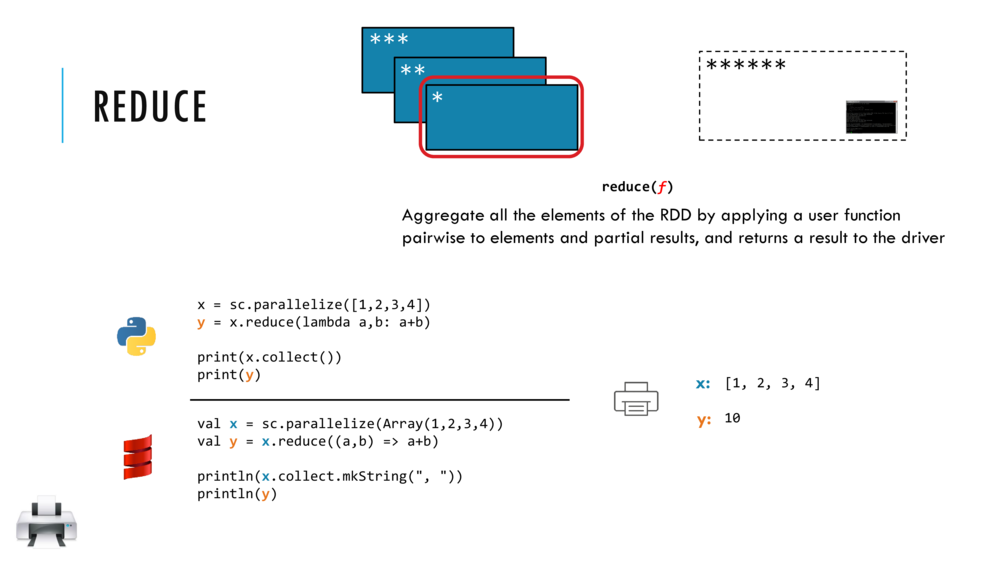
//Shift+Enter to make RDD x of inteegrs 1,2,3,4 and reduce it to sum
val x = sc.parallelize(Array(1,2,3,4))
val y = x.reduce((a,b) => a+b)
x: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at command-4088905069026252:2
y: Int = 10
//Cntrl+Enter to collect and print RDD x and the Int y, sum of x
println(x.collect.mkString(", "))
println(y)
1, 2, 3, 4
10
7. Transform an RDD by flatMap to make another RDD
flatMap is similar to map but each element from input RDD can be mapped to zero or more output elements. Therefore your function should return a sequential collection such as an Array rather than a single element as shown below.
Let us look at the flatMap transformation in detail and return here to try out the example codes.

//Shift+Enter to make RDD x and flatMap it into RDD by closure (n => Array(n, n*100, 42))
val x = sc.parallelize(Array(1,2,3))
val y = x.flatMap(n => Array(n, n*100, 42))
x: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at command-4088905069026256:2
y: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[11] at flatMap at command-4088905069026256:3
//Cntrl+Enter to collect and print RDDs x and y
println(x.collect().mkString(", "))
println(y.collect().mkString(", "))
sc.parallelize(Array(1,2,3)).map(n => Array(n,n*100,42)).collect()
1, 2, 3
1, 100, 42, 2, 200, 42, 3, 300, 42
res14: Array[Array[Int]] = Array(Array(1, 100, 42), Array(2, 200, 42), Array(3, 300, 42))
8. Create a Pair RDD
Let's next work with RDD of (key,value) pairs called a Pair RDD or Key-Value RDD.
// Cntrl+Enter to make RDD words and display it by collect
val words = sc.parallelize(Array("a", "b", "a", "a", "b", "b", "a", "a", "a", "b", "b"))
words.collect()
words: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[14] at parallelize at command-4088905069026259:2
res15: Array[String] = Array(a, b, a, a, b, b, a, a, a, b, b)
Let's make a Pair RDD called wordCountPairRDD that is made of (key,value) pairs with key=word and value=1 in order to encode each occurrence of each word in the RDD words, as follows:
// Cntrl+Enter to make and collect Pair RDD wordCountPairRDD
val wordCountPairRDD = words.map(s => (s, 1))
wordCountPairRDD.collect()
wordCountPairRDD: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[15] at map at command-4088905069026261:2
res16: Array[(String, Int)] = Array((a,1), (b,1), (a,1), (a,1), (b,1), (b,1), (a,1), (a,1), (a,1), (b,1), (b,1))
Wide Transformations and Shuffles
So far we have seen transformations that are narrow -- with no data transfer between partitions. Think of map.
ReduceByKey and GroupByKey are wide transformations as data has to be shuffled across the partitions in different executors -- this is generally very expensive operation.
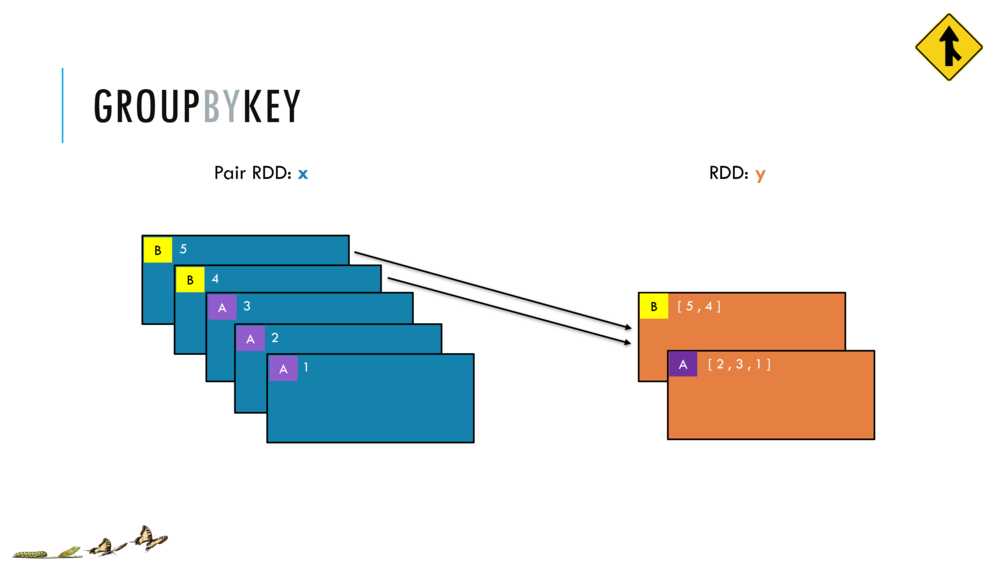
READ the Background about Shuffles in the programming guide below.
In Spark, data is generally not distributed across partitions to be in the necessary place for a specific operation. During computations, a single task will operate on a single partition - thus, to organize all the data for a single reduceByKey reduce task to execute, Spark needs to perform an all-to-all operation. It must read from all partitions to find all the values for all keys, and then bring together values across partitions to compute the final result for each key - this is called the shuffle
READ the Performance Impact about Shuffles in the programming guide below.
The Shuffle is an expensive operation since it involves disk I/O, data serialization, and network I/O. To organize data for the shuffle, Spark generates sets of tasks - map tasks to organize the data, and a set of reduce tasks to aggregate it. This nomenclature comes from MapReduce and does not directly relate to Spark’s map and reduce operations.
Internally, results from individual map tasks are kept in memory until they can’t fit. Then, these are sorted based on the target partition and written to a single file. On the reduce side, tasks read the relevant sorted blocks.
https://spark.apache.org/docs/latest/rdd-programming-guide.html#shuffle-operations
displayHTML(frameIt("https://spark.apache.org/docs/latest/rdd-programming-guide.html#shuffle-operations",500))
9. Perform some transformations on a Pair RDD
Let's next work with RDD of (key,value) pairs called a Pair RDD or Key-Value RDD.
Now some of the Key-Value transformations that we could perform include the following.
reduceByKeytransformation- which takes an RDD and returns a new RDD of key-value pairs, such that:
- the values for each key are aggregated using the given reduced function
- and the reduce function has to be of the type that takes two values and returns one value.
- which takes an RDD and returns a new RDD of key-value pairs, such that:
sortByKeytransformation- this returns a new RDD of key-value pairs that's sorted by keys in ascending order
groupByKeytransformation- this returns a new RDD consisting of key and iterable-valued pairs.
Let's see some concrete examples next.
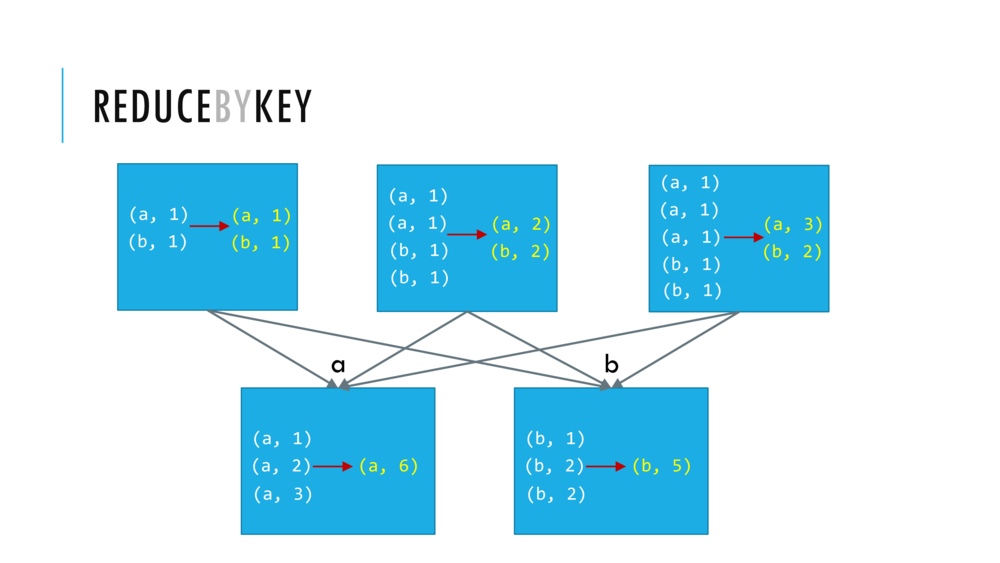
// Cntrl+Enter to reduceByKey and collect wordcounts RDD
//val wordcounts = wordCountPairRDD.reduceByKey( _ + _ )
val wordcounts = wordCountPairRDD.reduceByKey( (value1, value2) => value1 + value2 )
wordcounts.collect()
wordcounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[16] at reduceByKey at command-4088905069026268:3
res18: Array[(String, Int)] = Array((b,5), (a,6))
Now, let us do just the crucial steps and avoid collecting intermediate RDDs (something we should avoid for large datasets anyways, as they may not fit in the driver program).
//Cntrl+Enter to make words RDD and do the word count in two lines
val words = sc.parallelize(Array("a", "b", "a", "a", "b", "b", "a", "a", "a", "b", "b"))
val wordcounts = words
.map(s => (s, 1))
.reduceByKey(_ + _)
.collect()
words: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[17] at parallelize at command-4088905069026270:2
wordcounts: Array[(String, Int)] = Array((b,5), (a,6))
You Try!
You try evaluating sortByKey() which will make a new RDD that consists of the elements of the original pair RDD that are sorted by Keys.
// Shift+Enter and comprehend code
val words = sc.parallelize(Array("a", "b", "a", "a", "b", "b", "a", "a", "a", "b", "b"))
val wordCountPairRDD = words.map(s => (s, 1))
val wordCountPairRDDSortedByKey = wordCountPairRDD.sortByKey()
words: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[20] at parallelize at command-4088905069026272:2
wordCountPairRDD: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[21] at map at command-4088905069026272:3
wordCountPairRDDSortedByKey: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[24] at sortByKey at command-4088905069026272:4
wordCountPairRDD.collect() // Shift+Enter and comprehend code
res19: Array[(String, Int)] = Array((a,1), (b,1), (a,1), (a,1), (b,1), (b,1), (a,1), (a,1), (a,1), (b,1), (b,1))
wordCountPairRDDSortedByKey.collect() // Cntrl+Enter and comprehend code
res20: Array[(String, Int)] = Array((a,1), (a,1), (a,1), (a,1), (a,1), (a,1), (b,1), (b,1), (b,1), (b,1), (b,1))
The next key value transformation we will see is groupByKey
When we apply the groupByKey transformation to wordCountPairRDD we end up with a new RDD that contains two elements. The first element is the tuple b and an iterable CompactBuffer(1,1,1,1,1) obtained by grouping the value 1 for each of the five key value pairs (b,1). Similarly the second element is the key a and an iterable CompactBuffer(1,1,1,1,1,1) obtained by grouping the value 1 for each of the six key value pairs (a,1).
CAUTION: groupByKey can cause a large amount of data movement across the network. It also can create very large iterables at a worker. Imagine you have an RDD where you have 1 billion pairs that have the key a. All of the values will have to fit in a single worker if you use group by key. So instead of a group by key, consider using reduced by key.
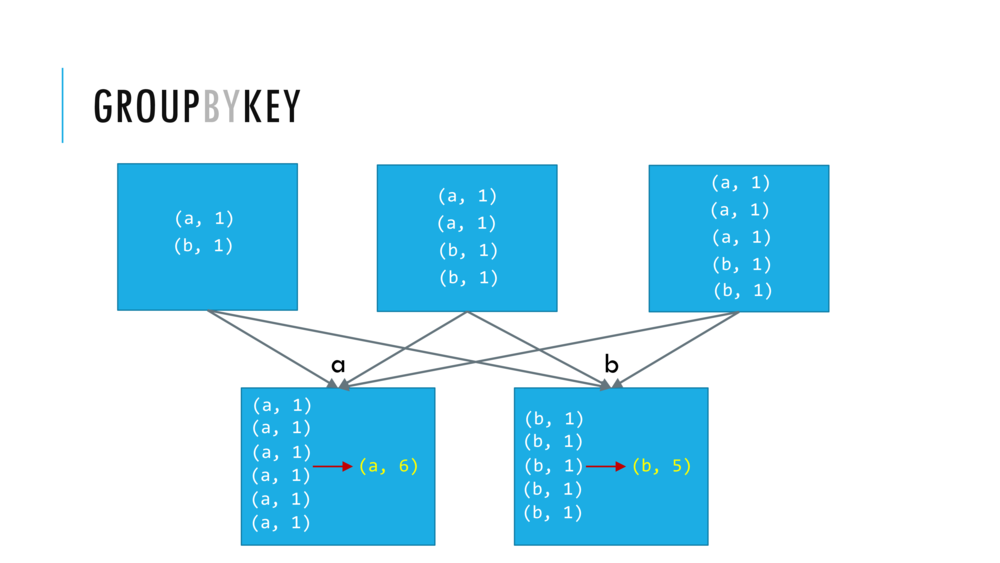
val wordCountPairRDDGroupByKey = wordCountPairRDD.groupByKey() // <Shift+Enter> CAUTION: this transformation can be very wide!
wordCountPairRDDGroupByKey: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[25] at groupByKey at command-4088905069026277:1
wordCountPairRDDGroupByKey.collect() // Cntrl+Enter
res21: Array[(String, Iterable[Int])] = Array((b,CompactBuffer(1, 1, 1, 1, 1)), (a,CompactBuffer(1, 1, 1, 1, 1, 1)))
10. Understanding Closures - Where in the cluster is your computation running?
One of the harder things about Spark is understanding the scope and life cycle of variables and methods when executing code across a cluster. RDD operations that modify variables outside of their scope can be a frequent source of confusion. In the example below we’ll look at code that uses
foreach()to increment a counter, but similar issues can occur for other operations as well.
https://spark.apache.org/docs/latest/rdd-programming-guide.html#understanding-closures-
displayHTML(frameIt("https://spark.apache.org/docs/latest/rdd-programming-guide.html#understanding-closures-",500))
val data = Array(1, 2, 3, 4, 5)
var counter = 0
var rdd = sc.parallelize(data)
// Wrong: Don't do this!!
rdd.foreach(x => counter += x)
println("Counter value: " + counter)
Counter value: 0
data: Array[Int] = Array(1, 2, 3, 4, 5)
counter: Int = 0
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[26] at parallelize at command-4088905069026281:3
From RDD programming guide:
The behavior of the above code is undefined, and may not work as intended. To execute jobs, Spark breaks up the processing of RDD operations into tasks, each of which is executed by an executor. Prior to execution, Spark computes the task’s closure. The closure is those variables and methods which must be visible for the executor to perform its computations on the RDD (in this case foreach()). This closure is serialized and sent to each executor.
The variables within the closure sent to each executor are now copies and thus, when counter is referenced within the foreach function, it’s no longer the counter on the driver node. There is still a counter in the memory of the driver node but this is no longer visible to the executors! The executors only see the copy from the serialized closure. Thus, the final value of counter will still be zero since all operations on counter were referencing the value within the serialized closure.
11. Shipping Closures, Broadcast Variables and Accumulator Variables
Closures, Broadcast and Accumulator Variables
Spark automatically creates closures
- for functions that run on RDDs at workers,
- and for any global variables that are used by those workers
- one closure per worker is sent with every task
- and there's no communication between workers
- closures are one way from the driver to the worker
- any changes that you make to the global variables at the workers
- are not sent to the driver or
- are not sent to other workers.
The problem we have is that these closures
- are automatically created are sent or re-sent with every job
- with a large global variable it gets inefficient to send/resend lots of data to each worker
- we cannot communicate that back to the driver
To do this, Spark provides shared variables in two different types.
- broadcast variables
- lets us to efficiently send large read-only values to all of the workers
- these are saved at the workers for use in one or more Spark operations.
- accumulator variables
- These allow us to aggregate values from workers back to the driver.
- only the driver can access the value of the accumulator
- for the tasks, the accumulators are basically write-only
Accumulators
Accumulators are variables that are only “added” to through an associative and commutative operation and can therefore be efficiently supported in parallel. They can be used to implement counters (as in MapReduce) or sums. Spark natively supports accumulators of numeric types, and programmers can add support for new types.
Read: https://spark.apache.org/docs/latest/rdd-programming-guide.html#accumulators.
displayHTML(frameIt("https://spark.apache.org/docs/latest/rdd-programming-guide.html#accumulators",500))
A numeric accumulator can be created by calling SparkContext.longAccumulator() or SparkContext.doubleAccumulator() to accumulate values of type Long or Double, respectively. Tasks running on a cluster can then add to it using the add method. However, they cannot read its value. Only the driver program can read the accumulator’s value, using its value method.
The code below shows an accumulator being used to add up the elements of an array:
val accum = sc.longAccumulator("My Accumulator")
accum: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 1236, name: Some(My Accumulator), value: 0)
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
accum.value
res26: Long = 10
spark.range(1, 100000).foreach(x => accum.add(x)) // bigger example
accum.value
res28: Long = 4999950010
Broadcast Variables
From https://spark.apache.org/docs/latest/rdd-programming-guide.html#broadcast-variables:
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used, for example, to give every node a copy of a large input dataset in an efficient manner. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost.
Spark actions are executed through a set of stages, separated by distributed “shuffle” operations. Spark automatically broadcasts the common data needed by tasks within each stage. The data broadcasted this way is cached in serialized form and deserialized before running each task. This means that explicitly creating broadcast variables is only useful when tasks across multiple stages need the same data or when caching the data in deserialized form is important.
Broadcast variables are created from a variable v by calling SparkContext.broadcast(v). The broadcast variable is a wrapper around v, and its value can be accessed by calling the value method. The code below shows this in action.
displayHTML(frameIt("https://spark.apache.org/docs/latest/rdd-programming-guide.html#broadcast-variables",500))
val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(30)
broadcastVar.value
res30: Array[Int] = Array(1, 2, 3)
broadcastVar.value(0)
res31: Int = 1
val rdd = sc.parallelize(1 to 10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[34] at parallelize at command-4088905069026297:1
rdd.collect
res32: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
rdd.map(x => x%3).collect
res33: Array[Int] = Array(1, 2, 0, 1, 2, 0, 1, 2, 0, 1)
rdd.map(x => x+broadcastVar.value(x%3)).collect
res34: Array[Int] = Array(3, 5, 4, 6, 8, 7, 9, 11, 10, 12)
After the broadcast variable is created, it should be used instead of the value v in any functions run on the cluster so that v is not shipped to the nodes more than once. In addition, the object v should not be modified after it is broadcast in order to ensure that all nodes get the same value of the broadcast variable (e.g. if the variable is shipped to a new node later).
To release the resources that the broadcast variable copied onto executors, call .unpersist(). If the broadcast is used again afterwards, it will be re-broadcast. To permanently release all resources used by the broadcast variable, call .destroy(). The broadcast variable can’t be used after that. Note that these methods do not block by default. To block until resources are freed, specify blocking=true when calling them.
broadcastVar.unpersist()
A more interesting example of broadcast variable
Let us broadcast maps and use them to lookup the values at each executor. This example is taken from: - https://sparkbyexamples.com/spark/spark-broadcast-variables/
val states = Map(("NY","New York"),("CA","California"),("FL","Florida"))
val countries = Map(("USA","United States of America"),("IN","India"))
val broadcastStates = spark.sparkContext.broadcast(states) // same as sc.broadcast
val broadcastCountries = spark.sparkContext.broadcast(countries)
val data = Seq(("James","Smith","USA","CA"),
("Michael","Rose","USA","NY"),
("Robert","Williams","USA","CA"),
("Maria","Jones","USA","FL"))
val rdd = spark.sparkContext.parallelize(data) // spark.sparkContext is the same as sc.parallelize in spark-shell/notebook
val rdd2 = rdd.map(f => {
val country = f._3
val state = f._4
val fullCountry = broadcastCountries.value.get(country).get
val fullState = broadcastStates.value.get(state).get
(f._1,f._2,fullCountry,fullState)
})
states: scala.collection.immutable.Map[String,String] = Map(NY -> New York, CA -> California, FL -> Florida)
countries: scala.collection.immutable.Map[String,String] = Map(USA -> United States of America, IN -> India)
broadcastStates: org.apache.spark.broadcast.Broadcast[scala.collection.immutable.Map[String,String]] = Broadcast(34)
broadcastCountries: org.apache.spark.broadcast.Broadcast[scala.collection.immutable.Map[String,String]] = Broadcast(35)
data: Seq[(String, String, String, String)] = List((James,Smith,USA,CA), (Michael,Rose,USA,NY), (Robert,Williams,USA,CA), (Maria,Jones,USA,FL))
rdd: org.apache.spark.rdd.RDD[(String, String, String, String)] = ParallelCollectionRDD[37] at parallelize at command-4088905069026304:12
rdd2: org.apache.spark.rdd.RDD[(String, String, String, String)] = MapPartitionsRDD[38] at map at command-4088905069026304:14
println(rdd2.collect().mkString("\n"))
(James,Smith,United States of America,California)
(Michael,Rose,United States of America,New York)
(Robert,Williams,United States of America,California)
(Maria,Jones,United States of America,Florida)
13. HOMEWORK
See the notebook in this folder named 005_RDDsTransformationsActionsHOMEWORK. This notebook will give you more examples of the operations above as well as others we will be using later, including:
- Perform the
takeOrderedaction on the RDD - Transform the RDD by
distinctto make another RDD and - Doing a bunch of transformations to our RDD and performing an action in a single cell.
14. Importing Standard Scala and Java libraries
- For other libraries that are not available by default, you can upload other libraries to the Workspace.
- Refer to the Libraries guide for more details.
import scala.math._
val x = min(1, 10)
import scala.math._
x: Int = 1
import java.util.HashMap
val map = new HashMap[String, Int]()
map.put("a", 1)
map.put("b", 2)
map.put("c", 3)
map.put("d", 4)
map.put("e", 5)
import java.util.HashMap
map: java.util.HashMap[String,Int] = {a=1, b=2, c=3, d=4, e=5}
res37: Int = 0
To read at ease more methodically go through Chapter 12. Resilient Distributed Datasets (RDDs) of Spark: The Definitive Guide:
- https://learning.oreilly.com/library/view/spark-the-definitive/9781491912201/ch12.html
Note, you may need access via your library.
HOMEWORK on RDD Transformations and Actions
Just go through the notebook and familiarize yourself with these transformations and actions. This will help you do the autograded Assignment.
- Perform the
takeOrderedaction on the RDD
To illustrate take and takeOrdered actions, let's create a bigger RDD named rdd0_1000000 that is made up of a million integers from 0 to 1000000.
We will sc.parallelize the Seq Scala collection by using its .range(startInteger,stopInteger) method.
val rdd0_1000000 = sc.parallelize(Seq.range(0, 1000000)) // <Shift+Enter> to create an RDD of million integers: 0,1,2,...,10^6
rdd0_1000000: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[39] at parallelize at command-4088905069025406:1
rdd0_1000000.take(5) // <Ctrl+Enter> gives the first 5 elements of the RDD, (0, 1, 2, 3, 4)
res0: Array[Int] = Array(0, 1, 2, 3, 4)
takeordered(n) returns n elements ordered in ascending order (by default) or as specified by the optional key function, as shown below.
rdd0_1000000.takeOrdered(5) // <Shift+Enter> is same as rdd0_1000000.take(5)
res1: Array[Int] = Array(0, 1, 2, 3, 4)
rdd0_1000000.takeOrdered(5)(Ordering[Int].reverse) // <Ctrl+Enter> to get the last 5 elements of the RDD 999999, 999998, ..., 999995
res2: Array[Int] = Array(999999, 999998, 999997, 999996, 999995)
// HOMEWORK: edit the numbers below to get the last 20 elements of an RDD made of a sequence of integers from 669966 to 969696
sc.parallelize(Seq.range(0, 10)).takeOrdered(5)(Ordering[Int].reverse) // <Ctrl+Enter> evaluate this cell after editing it for the right answer
res3: Array[Int] = Array(9, 8, 7, 6, 5)
- More examples of
map
val rdd = sc.parallelize(Seq(1, 2, 3, 4)) // <Shift+Enter> to evaluate this cell (using default number of partitions)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[41] at parallelize at command-4088905069025413:1
rdd.map( x => x*2) // <Ctrl+Enter> to transform rdd by map that doubles each element
res4: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[42] at map at command-4088905069025414:1
To see what's in the transformed RDD, let's perform the actions of count and collect on the rdd.map( x => x*2), the transformation of rdd by the map given by the closure x => x*2.
rdd.map( x => x*2).count() // <Shift+Enter> to perform count (action) the element of the RDD = 4
res5: Long = 4
rdd.map( x => x*2).collect() // <Shift+Enter> to perform collect (action) to show 2, 4, 6, 8
res6: Array[Int] = Array(2, 4, 6, 8)
// HOMEWORK: uncomment the last line in this cell and modify the '<Fill-In-Here>' in the code below to collect and display the square (x*x) of each element of the RDD
// the answer should be Array[Int] = Array(1, 4, 9, 16) Press <Cntrl+Enter> to evaluate the cell after modifying '???'
//sc.parallelize(Seq(1, 2, 3, 4)).map( x => <Fill-In-Here> ).collect()
- More examples of
filter
Let's declare another val RDD named rddFiltered by transforming our first RDD named rdd via the filter transformation x%2==0 (of being even).
This filter transformation based on the closure x => x%2==0 will return true if the element, modulo two, equals zero. The closure is automatically passed on to the workers for evaluation (when an action is called later). So this will take our RDD of (1,2,3,4) and return RDD of (2, 4).
val rddFiltered = rdd.filter( x => x%2==0 ) // <Ctrl+Enter> to declare rddFiltered from transforming rdd
rddFiltered: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[45] at filter at command-4088905069025420:1
rddFiltered.collect() // <Ctrl+Enter> to collect (action) elements of rddFiltered; should be (2, 4)
res8: Array[Int] = Array(2, 4)
- More examples of
reduce
val rdd = sc.parallelize(Array(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[46] at parallelize at command-4088905069025423:1
rdd.reduce( (x,y)=>x+y ) // <Shift+Enter> to do reduce (action) to sum and return Int = 15
res9: Int = 15
rdd.reduce( _ + _ ) // <Shift+Enter> to do same sum as above and return Int = 15 (undescore syntax)
res10: Int = 15
rdd.reduce( (x,y)=>x*y ) // <Shift+Enter> to do reduce (action) to multiply and return Int = 120
res11: Int = 120
val rdd0_1000000 = sc.parallelize(Seq.range(0, 1000000)) // <Shift+Enter> to create an RDD of million integers: 0,1,2,...,10^6
rdd0_1000000: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[47] at parallelize at command-4088905069025427:1
rdd0_1000000.reduce( (x,y)=>x+y ) // <Ctrl+Enter> to do reduce (action) to sum and return Int 1783293664
res12: Int = 1783293664
// the following correctly returns Int = 0 although for wrong reason
// we have flowed out of Int's numeric limits!!! (but got lucky with 0*x=0 for any Int x)
// <Shift+Enter> to do reduce (action) to multiply and return Int = 0
rdd0_1000000.reduce( (x,y)=>x*y )
res13: Int = 0
// <Ctrl+Enter> to do reduce (action) to multiply 1*2*...*9*10 and return correct answer Int = 3628800
sc.parallelize(Seq.range(1, 11)).reduce( (x,y)=>x*y )
res14: Int = 3628800
CAUTION: Know the limits of your numeric types!
The minimum and maximum value of Int and Long types are as follows:
(Int.MinValue , Int.MaxValue)
res15: (Int, Int) = (-2147483648,2147483647)
(Long.MinValue, Long.MaxValue)
res16: (Long, Long) = (-9223372036854775808,9223372036854775807)
// <Ctrl+Enter> to do reduce (action) to multiply 1*2*...*20 and return wrong answer as Int = -2102132736
// we have overflowed out of Int's in a circle back to negative Ints!!! (rigorous distributed numerics, anyone?)
sc.parallelize(Seq.range(1, 21)).reduce( (x,y)=>x*y )
res17: Int = -2102132736
//<Ctrl+Enter> we can accomplish the multiplication using Long Integer types
// by adding 'L' ro integer values, Scala infers that it is type Long
sc.parallelize(Seq.range(1L, 21L)).reduce( (x,y)=>x*y )
res18: Long = 2432902008176640000
As the following products over Long Integers indicate, they are limited too!
// <Shift+Enter> for wrong answer Long = -8718968878589280256 (due to Long's numeric limits)
sc.parallelize(Seq.range(1L, 61L)).reduce( (x,y)=>x*y )
res19: Long = -8718968878589280256
// <Cntrl+Enter> for wrong answer Long = 0 (due to Long's numeric limits)
sc.parallelize(Seq.range(1L, 100L)).reduce( (x,y)=>x*y )
res20: Long = 0
- Let us do a bunch of transformations to our RDD and perform an action
- start from a Scala
Seq, sc.parallelizethe list to create an RDD,filterthat RDD, creating a new filtered RDD,- do a
maptransformation that maps that RDD to a new mapped RDD, - and finally, perform a
reduceaction to sum the elements in the RDD.
This last reduce action causes the parallelize, the filter, and the map transformations to actually be executed, and return a result back to the driver machine.
sc.parallelize(Seq(1, 2, 3, 4)) // <Ctrl+Enter> will return Array(4, 8)
.filter(x => x%2==0) // (2, 4) is the filtered RDD
.map(x => x*2) // (4, 8) is the mapped RDD
.reduce(_+_) // 4+8=12 is the final result from reduce
res21: Int = 12
- Transform the RDD by
distinctto make another RDD
Let's declare another RDD named rdd2 that has some repeated elements to apply the distinct transformation to it. That would give us a new RDD that only contains the distinct elements of the input RDD.
val rdd2 = sc.parallelize(Seq(4, 1, 3, 2, 2, 2, 3, 4)) // <Ctrl+Enter> to declare rdd2
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[56] at parallelize at command-4088905069025443:1
Let's apply the distinct transformation to rdd2 and have it return a new RDD named rdd2Distinct that contains the distinct elements of the source RDD rdd2.
val rdd2Distinct = rdd2.distinct() // <Ctrl+Enter> transformation: distinct gives distinct elements of rdd2
rdd2Distinct: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[59] at distinct at command-4088905069025445:1
rdd2Distinct.collect() // <Ctrl+Enter> to collect (action) as Array(4, 2, 1, 3)
res22: Array[Int] = Array(4, 2, 1, 3)
- more flatMap
val rdd = sc. parallelize(Array(1,2,3)) // <Shift+Enter> to create an RDD of three Int elements 1,2,3
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[60] at parallelize at command-4088905069025448:1
Let us pass the rdd above to a map with a closure that will take in each element x and return Array(x, x+5). So each element of the mapped RDD named rddOfArrays is an Array[Int], an array of integers.
// <Shift+Enter> to make RDD of Arrays, i.e., RDD[Array[int]]
val rddOfArrays = rdd.map( x => Array(x, x+5) )
rddOfArrays: org.apache.spark.rdd.RDD[Array[Int]] = MapPartitionsRDD[61] at map at command-4088905069025450:2
rddOfArrays.collect() // <Ctrl+Enter> to see it is RDD[Array[int]] = (Array(1, 6), Array(2, 7), Array(3, 8))
res23: Array[Array[Int]] = Array(Array(1, 6), Array(2, 7), Array(3, 8))
Now let's observer what happens when we use flatMap to transform the same rdd and create another RDD called rddfM.
Interestingly, flatMap flattens our rdd by taking each Array (or sequence in general) and truning it into individual elements.
Thus, we end up with the RDD rddfM consisting of the elements (1, 6, 2, 7, 3, 8) as shown from the output of rddfM.collect below.
val rddfM = rdd.flatMap(x => Array(x, x+5)) // <Shift+Enter> to flatMap the rdd using closure (x => Array(x, x+5))
rddfM: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[62] at flatMap at command-4088905069025453:1
rddfM.collect // <Ctrl+Enter> to collect rddfM = (1, 6, 2, 7, 3, 8)
res24: Array[Int] = Array(1, 6, 2, 7, 3, 8)
Word Count on US State of the Union (SoU) Addresses
- Word Count in big data is the equivalent of
Hello Worldin programming - We count the number of occurences of each word in the first and last (2016) SoU addresses.
You should have loaded data by now, i.e., run all cells in the Notebook 002_02_dbcCEdataLoader.
An interesting analysis of the textual content of the State of the Union (SoU) addresses by all US presidents was done in:

Fig. 5. A river network captures the flow across history of US political discourse, as perceived by contemporaries. Time moves along the x axis. Clusters on semantic networks of 300 most frequent terms for each of 10 historical periods are displayed as vertical bars. Relations between clusters of adjacent periods are indexed by gray flows, whose density reflects their degree of connection. Streams that connect at any point in history may be considered to be part of the same system, indicated with a single color.
Let us investigate this dataset ourselves!
- We first get the source text data by scraping and parsing from http://stateoftheunion.onetwothree.net/texts/index.html as explained in scraping and parsing SoU addresses.
- All of the SOU addresses from the founding of the United States until 2017 has been scraped into a single file.
- This data is already made available in our distributed file system.
- We only do the simplest word count with this data in this notebook and will do more sophisticated analyses in the sequel (including topic modeling, etc).
Key Data Management Concepts
The Structure Spectrum
Let's peruse through the following blog from IBM to get an idea of structured, unstructured and semi-structured data:
In this notebook we will be working with unstructured or schema-never data (plain text files).
Later on we will be working with structured or tabular data as well as semi-structured data.
DBFS and dbutils - where is this dataset in our distributed file system inside databricks?
- Since we are on the databricks cloud, it has a file system called DBFS
- DBFS is similar to HDFS, the Hadoop distributed file system
- dbutils allows us to interact with dbfs.
- The 'display' command displays the list of files in a given directory in the file system.
Note: If you are on zeppelin or a non-databricks environment then use hdfs or drop into shell via %sh to ls the files in the local file system.
ls /datasets/sds
| path | name | size | modificationTime |
|---|---|---|---|
| dbfs:/datasets/sds/Rdatasets/ | Rdatasets/ | 0.0 | 1.66429635041e12 |
| dbfs:/datasets/sds/cs100/ | cs100/ | 0.0 | 1.66429635041e12 |
| dbfs:/datasets/sds/flights/ | flights/ | 0.0 | 1.66429635041e12 |
| dbfs:/datasets/sds/mnist-digits/ | mnist-digits/ | 0.0 | 1.66429635041e12 |
| dbfs:/datasets/sds/people/ | people/ | 0.0 | 1.66429635041e12 |
| dbfs:/datasets/sds/people.json/ | people.json/ | 0.0 | 1.66429635041e12 |
| dbfs:/datasets/sds/power-plant/ | power-plant/ | 0.0 | 1.66429635041e12 |
| dbfs:/datasets/sds/social_media_usage.csv/ | social_media_usage.csv/ | 0.0 | 1.66429635041e12 |
| dbfs:/datasets/sds/songs/ | songs/ | 0.0 | 1.66429635041e12 |
| dbfs:/datasets/sds/souall.txt.gz | souall.txt.gz | 3576868.0 | 1.664296002e12 |
| dbfs:/datasets/sds/spark-examples/ | spark-examples/ | 0.0 | 1.66429635041e12 |
| dbfs:/datasets/sds/weather/ | weather/ | 0.0 | 1.66429635041e12 |
| dbfs:/datasets/sds/wikipedia-datasets/ | wikipedia-datasets/ | 0.0 | 1.66429635041e12 |
Read the file into Spark Context as an RDD of Strings
- The
textFilemethod on the availableSparkContextsccan read the gnu-zip compressed text file/datasets/sds/souall.txt.gzinto Spark and create an RDD of Strings- but this is done lazily until an action is taken on the RDD
sou!
- but this is done lazily until an action is taken on the RDD
val sou = sc.textFile("/datasets/sds/souall.txt.gz") // Cntrl+Enter to read the gzipped textfile as RDD[String]
sou: org.apache.spark.rdd.RDD[String] = /datasets/sds/souall.txt.gz MapPartitionsRDD[3] at textFile at command-2942007275186754:1
sou.take(5) // Cntrl+Enter to read the first 5 lines of the gzipped textfile as RDD[String]
res2: Array[String] = Array("George Washington ", "", "January 8, 1790 ", "Fellow-Citizens of the Senate and House of Representatives: ", "I embrace with great satisfaction the opportunity which now presents itself of congratulating you on the present favorable prospects of our public affairs. The recent accession of the important state of North Carolina to the Constitution of the United States (of which official information has been received), the rising credit and respectability of our country, the general and increasing good will toward the government of the Union, and the concord, peace, and plenty with which we are blessed are circumstances auspicious in an eminent degree to our national prosperity. ")
Perform some actions on the RDD
- Each String in the RDD
sourepresents one line of data from the file and can be made to perform one of the following actions:- count the number of elements in the RDD
sou(i.e., the number of lines in the text file/datasets/sds/souall.txt.gz) usingsou.count - display the contents of the RDD using
take - do not use
collectas it will bring all the lines to the Driver, which could crash the Driver if the RDD is very large.
- count the number of elements in the RDD
sou.count // <Shift+Enter> to get the number of elements or number of lines ending in line breaks '\n' in sou
res3: Long = 22258
sou.take(30) // <Shift+Enter> to display the first 30 elements of RDD, including the beginning of the second SOU by George Washington
res4: Array[String] = Array("George Washington ", "", "January 8, 1790 ", "Fellow-Citizens of the Senate and House of Representatives: ", "I embrace with great satisfaction the opportunity which now presents itself of congratulating you on the present favorable prospects of our public affairs. The recent accession of the important state of North Carolina to the Constitution of the United States (of which official information has been received), the rising credit and respectability of our country, the general and increasing good will toward the government of the Union, and the concord, peace, and plenty with which we are blessed are circumstances auspicious in an eminent degree to our national prosperity. ", "In resuming your consultations for the general good you can not but derive encouragement from the reflection that the measures of the last session have been as satisfactory to your constituents as the novelty and difficulty of the work allowed you to hope. Still further to realize their expectations and to secure the blessings which a gracious Providence has placed within our reach will in the course of the present important session call for the cool and deliberate exertion of your patriotism, firmness, and wisdom. ", "Among the many interesting objects which will engage your attention that of providing for the common defense will merit particular regard. To be prepared for war is one of the most effectual means of preserving peace. ", "A free people ought not only to be armed, but disciplined; to which end a uniform and well-digested plan is requisite; and their safety and interest require that they should promote such manufactories as tend to render them independent of others for essential, particularly military, supplies. ", "The proper establishment of the troops which may be deemed indispensable will be entitled to mature consideration. In the arrangements which may be made respecting it it will be of importance to conciliate the comfortable support of the officers and soldiers with a due regard to economy. ", "There was reason to hope that the pacific measures adopted with regard to certain hostile tribes of Indians would have relieved the inhabitants of our southern and western frontiers from their depredations, but you will perceive from the information contained in the papers which I shall direct to be laid before you (comprehending a communication from the Commonwealth of Virginia) that we ought to be prepared to afford protection to those parts of the Union, and, if necessary, to punish aggressors. ", "The interests of the United States require that our intercourse with other nations should be facilitated by such provisions as will enable me to fulfill my duty in that respect in the manner which circumstances may render most conducive to the public good, and to this end that the compensation to be made to the persons who may be employed should, according to the nature of their appointments, be defined by law, and a competent fund designated for defraying the expenses incident to the conduct of foreign affairs. ", "Various considerations also render it expedient that the terms on which foreigners may be admitted to the rights of citizens should be speedily ascertained by a uniform rule of naturalization. ", "Uniformity in the currency, weights, and measures of the United States is an object of great importance, and will, I am persuaded, be duly attended to. ", "The advancement of agriculture, commerce, and manufactures by all proper means will not, I trust, need recommendation; but I can not forbear intimating to you the expediency of giving effectual encouragement as well to the introduction of new and useful inventions from abroad as to the exertions of skill and genius in producing them at home, and of facilitating the intercourse between the distant parts of our country by a due attention to the post-office and post-roads. ", "Nor am I less persuaded that you will agree with me in opinion that there is nothing which can better deserve your patronage than the promotion of science and literature. Knowledge is in every country the surest basis of public happiness. In one in which the measures of government receive their impressions so immediately from the sense of the community as in ours it is proportionably essential. ", "To the security of a free constitution it contributes in various ways--by convincing those who are intrusted with the public administration that every valuable end of government is best answered by the enlightened confidence of the people, and by teaching the people themselves to know and to value their own rights; to discern and provide against invasions of them; to distinguish between oppression and the necessary exercise of lawful authority; between burthens proceeding from a disregard to their convenience and those resulting from the inevitable exigencies of society; to discriminate the spirit of liberty from that of licentiousness-- cherishing the first, avoiding the last--and uniting a speedy but temperate vigilance against encroachments, with an inviolable respect to the laws. ", "Whether this desirable object will be best promoted by affording aids to seminaries of learning already established, by the institution of a national university, or by any other expedients will be well worthy of a place in the deliberations of the legislature. ", "Gentlemen of the House of Representatives: ", "I saw with peculiar pleasure at the close of the last session the resolution entered into by you expressive of your opinion that an adequate provision for the support of the public credit is a matter of high importance to the national honor and prosperity. In this sentiment I entirely concur; and to a perfect confidence in your best endeavors to devise such a provision as will be truly with the end I add an equal reliance on the cheerful cooperation of the other branch of the legislature. ", "It would be superfluous to specify inducements to a measure in which the character and interests of the United States are so obviously so deeply concerned, and which has received so explicit a sanction from your declaration. ", "Gentlemen of the Senate and House of Representatives: ", "I have directed the proper officers to lay before you, respectively, such papers and estimates as regard the affairs particularly recommended to your consideration, and necessary to convey to you that information of the state of the Union which it is my duty to afford. ", The welfare of our country is the great object to which our cares and efforts ought to be directed, and I shall derive great satisfaction from a cooperation with you in the pleasing though arduous task of insuring to our fellow citizens the blessings which they have a right to expect from a free, efficient, and equal government., "", "George Washington ", "", "December 8, 1790 ", "Fellow-Citizens of the Senate and House of Representatives: ", "In meeting you again I feel much satisfaction in being able to repeat my congratulations on the favorable prospects which continue to distinguish our public affairs. The abundant fruits of another year have blessed our country with plenty and with the means of a flourishing commerce. ", "The progress of public credit is witnessed by a considerable rise of American stock abroad as well as at home, and the revenues allotted for this and other national purposes have been productive beyond the calculations by which they were regulated. This latter circumstance is the more pleasing, as it is not only a proof of the fertility of our resources, but as it assures us of a further increase of the national respectability and credit, and, let me add, as it bears an honorable testimony to the patriotism and integrity of the mercantile and marine part of our citizens. The punctuality of the former in discharging their engagements has been exemplary. ")
sou.take(5).foreach(println) // <Shift+Enter> to display the first 5 elements of RDD line by line
George Washington
January 8, 1790
Fellow-Citizens of the Senate and House of Representatives:
I embrace with great satisfaction the opportunity which now presents itself of congratulating you on the present favorable prospects of our public affairs. The recent accession of the important state of North Carolina to the Constitution of the United States (of which official information has been received), the rising credit and respectability of our country, the general and increasing good will toward the government of the Union, and the concord, peace, and plenty with which we are blessed are circumstances auspicious in an eminent degree to our national prosperity.
sou.zipWithIndex.count
res6: Long = 22258
SInce we have several SOU addresses we can use zipWithIndex and filter to extract the specific lines in a range of interest.
val souWithIndices = sou.zipWithIndex()
souWithIndices: org.apache.spark.rdd.RDD[(String, Long)] = ZippedWithIndexRDD[5] at zipWithIndex at command-69839727109967:1
souWithIndices.take(5) // <Cntrl+Enter> to display all the elements of RDD zipped with index starting from 0
res7: Array[(String, Long)] = Array(("George Washington ",0), ("",1), ("January 8, 1790 ",2), ("Fellow-Citizens of the Senate and House of Representatives: ",3), ("I embrace with great satisfaction the opportunity which now presents itself of congratulating you on the present favorable prospects of our public affairs. The recent accession of the important state of North Carolina to the Constitution of the United States (of which official information has been received), the rising credit and respectability of our country, the general and increasing good will toward the government of the Union, and the concord, peace, and plenty with which we are blessed are circumstances auspicious in an eminent degree to our national prosperity. ",4))
souWithIndices.map(lineWithIndex => lineWithIndex._1).take(5) // the first element via ._1 as String of each tuple... taking first 5
res8: Array[String] = Array("George Washington ", "", "January 8, 1790 ", "Fellow-Citizens of the Senate and House of Representatives: ", "I embrace with great satisfaction the opportunity which now presents itself of congratulating you on the present favorable prospects of our public affairs. The recent accession of the important state of North Carolina to the Constitution of the United States (of which official information has been received), the rising credit and respectability of our country, the general and increasing good will toward the government of the Union, and the concord, peace, and plenty with which we are blessed are circumstances auspicious in an eminent degree to our national prosperity. ")
souWithIndices.map(lineWithIndex => lineWithIndex._2).take(5) // the second element via ._2 as Long of each tuple... taking first 5
res9: Array[Long] = Array(0, 1, 2, 3, 4)
souWithIndices.filter(lineWithIndex => 1 <= lineWithIndex._2 && lineWithIndex._2 <= 3).collect // collecting lines 1-3
res10: Array[(String, Long)] = Array(("",1), ("January 8, 1790 ",2), ("Fellow-Citizens of the Senate and House of Representatives: ",3))
// the last 148 lines are from the 2017 SOU by Donald J. Trump
souWithIndices.filter(lineWithIndex => 22258-148 < lineWithIndex._2 && lineWithIndex._2 <= 22258).collect
res11: Array[(String, Long)] = Array(("Donald J. Trump ",22111), ("",22112), ("February 28, 2017 ",22113), ("Thank you very much. Mr. Speaker, Mr. Vice President, members of Congress, the first lady of the United States ... ",22114), ("... and citizens of America, tonight, as we mark the conclusion of our celebration of Black History Month, we are reminded of our nation's path toward civil rights and the work that still remains to be done. ",22115), ("Recent threats ... ",22116), ("Recent threats targeting Jewish community centers and vandalism of Jewish cemeteries, as well as last week's shooting in Kansas City, remind us that while we may be a nation divided on policies, we are a country that stands united in condemning hate and evil in all of its very ugly forms. ",22117), ("Each American generation passes the torch of truth, liberty and justice, in an unbroken chain all the way down to the present. That torch is now in our hands. And we will use it to light up the world. ",22118), ("I am here tonight to deliver a message of unity and strength, and it is a message deeply delivered from my heart. A new chapter ... ",22119), ("... of American greatness is now beginning. A new national pride is sweeping across our nation. And a new surge of optimism is placing impossible dreams firmly within our grasp. What we are witnessing today is the renewal of the American spirit. Our allies will find that America is once again ready to lead. ",22120), ("All the nations of the world friend or foe will find that America is strong, America is proud, and America is free. In nine years, the United States will celebrate the 250th anniversary of our founding, 250 years since the day we declared our independence. It will be one of the great milestones in the history of the world. ",22121), ("But what will America look like as we reach our 250th year? What kind of country will we leave for our children? I will not allow the mistakes of recent decades past to define the course of our future. ",22122), ("For too long, we've watched our middle class shrink as we've exported our jobs and wealth to foreign countries. We've financed and built one global project after another, but ignored the fates of our children in the inner cities of Chicago, Baltimore, Detroit and so many other places throughout our land. ",22123), ("We've defended the borders of other nations while leaving our own borders wide open for anyone to cross, and for drugs to pour in at a now unprecedented rate. And we've spent trillions and trillions of dollars overseas, while our infrastructure at home has so badly crumbled. ",22124), ("Then, in 2016, the earth shifted beneath our feet. The rebellion started as a quiet protest, spoken by families of all colors and creeds, families who just wanted a fair shot for their children, and a fair hearing for their concerns. ",22125), ("But then the quiet voices became a loud chorus, as thousands of citizens now spoke out together, from cities small and large, all across our country. ",22126), ("Finally, the chorus became an earthquake, and the people turned out by the tens of millions, and they were all united by one very simple, but crucial demand, that America must put its own citizens first, because only then can we truly make America great again. ",22127), ("Dying industries will come roaring back to life. Heroic veterans will get the care they so desperately need. Our military will be given the resources its brave warriors so richly deserve. ",22128), ("Crumbling infrastructure will be replaced with new roads, bridges, tunnels, airports and railways, gleaming across our very, very beautiful land. Our terrible drug epidemic will slow down and ultimately stop. And our neglected inner cities will see a rebirth of hope, safety and opportunity. ",22129), ("Above all else, we will keep our promises to the American people. ",22130), ("Thank you. It's been a little over a month since my inauguration, and I want to take this moment to update the nation on the progress I've made in keeping those promises. Since my election, Ford, Fiat-Chrysler, General Motors, Sprint, Softbank, Lockheed, Intel, Walmart and many others have announced that they will invest billions and billions of dollars in the United States and will create tens of thousands of new American jobs. ",22131), ("The stock market has gained almost $3 trillion in value since the election on Nov. 8, a record. We've saved taxpayers hundreds of millions of dollars by bringing down the price of fantastic and it is a fantastic new F-35 jet fighter, and we'll be saving billions more on contracts all across our government. ",22132), ("We have placed a hiring freeze on nonmilitary and nonessential federal workers. ",22133), ("We have begun to drain the swamp of government corruption by imposing a five-year ban on lobbying by executive branch officials and a lifetime ban ... ",22134), ("Thank you. Thank you. And a lifetime ban on becoming lobbyists for a foreign government. We have undertaken a historic effort to massively reduce job-crushing regulations, creating a deregulation task force inside of every government agency ... ",22135), ("... and we're imposing a new rule which mandates that for every one new regulation, two old regulations must be eliminated. ",22136), ("We're going to stop the regulations that threaten the future and livelihood of our great coal miners. ",22137), ("We have cleared the way for the construction of the Keystone and Dakota Access Pipelines ... ",22138), ("... thereby creating tens of thousands of jobs. And I've issued a new directive that new American pipelines be made with American steel. ",22139), ("We have withdrawn the United States from the job-killing Trans-Pacific Partnership. ",22140), ("And with the help of Prime Minister Justin Trudeau, we have formed a council with our neighbors in Canada to help ensure that women entrepreneurs have access to the networks, markets and capital they need to start a business and live out their financial dreams. ",22141), ("To protect our citizens, I have directed the Department of Justice to form a task force on reducing violent crime. I have further ordered the Departments of Homeland Security and Justice, along with the Department of State and the director of national intelligence, to coordinate an aggressive strategy to dismantle the criminal cartels that have spread all across our nation. ",22142), ("We will stop the drugs from pouring into our country and poisoning our youth, and we will expand treatment for those who have become so badly addicted. ",22143), ("At the same time, my administration has answered the pleas of the American people for immigration enforcement and border security. ",22144), ("By finally enforcing our immigration laws, we will raise wages, help the unemployed, save billions and billions of dollars, and make our communities safer for everyone. ",22145), ("We want all Americans to succeed, but that can't happen in an environment of lawless chaos. ",22146), ("We must restore integrity and the rule of law at our borders. ",22147), ("For that reason, we will soon begin the construction of a great, great wall along our southern border. ",22148), ("As we speak tonight, we are removing gang members, drug dealers and criminals that threaten our communities and prey on our very innocent citizens. Bad ones are going out as I speak, and as I promised throughout the campaign. To any in Congress who do not believe we should enforce our laws, I would ask you this one question: What would you say to the American family that loses their jobs, their income or their loved one because America refused to uphold its laws and defend its borders? ",22149), ("Our obligation is to serve, protect and defend the citizens of the United States. We are also taking strong measures to protect our nation from radical Islamic terrorism. ",22150), ("According to data provided by the Department of Justice, the vast majority of individuals convicted of terrorism and terrorism-related offenses since 9/11 came here from outside of our country. We have seen the attacks at home, from Boston to San Bernardino to the Pentagon and, yes, even the World Trade Center. We have seen the attacks in France, in Belgium, in Germany and all over the world. ",22151), ("It is not compassionate, but reckless to allow uncontrolled entry from places where proper vetting cannot occur. ",22152), ("Those given the high honor of admission to the United States should support this country and love its people and its values. We cannot allow a beachhead of terrorism to form inside America, and we cannot allow our nation to become a sanctuary for extremists. ",22153), ("That is why my administration has been working on improved vetting procedures, and we will shortly take new steps to keep our nation safe, and to keep those out who will do us harm. ",22154), ("As promised, I directed the Department of Defense to develop a plan to demolish and destroy ISIS, a network of lawless savages that have slaughtered Muslims and Christians, and men, women and children of all faiths and all beliefs. We will work with our allies, including our friends and allies in the Muslim world, to extinguish this vile enemy from our planet. ",22155), ("I have also imposed new sanctions on entities and individuals who support Iran's ballistic missile program, and reaffirmed our unbreakable alliance with the state of Israel. ",22156), ("Finally, I have kept my promise to appoint a justice to the United States Supreme Court, from my list of 20 judges, who will defend our Constitution. ",22157), ("I am greatly honored to have Maureen Scalia with us in the gallery tonight. ",22158), ("Thank you, Maureen. Her late, great husband, Antonin Scalia, will forever be a symbol of American justice. ",22159), ("To fill his seat, we have chosen Judge Neil Gorsuch, a man of incredible skill and deep devotion to the law. He was confirmed unanimously by the Court of Appeals, and I am asking the Senate to swiftly approve his nomination. ",22160), ("Tonight, as I outline the next steps we must take as a country, we must honestly acknowledge the circumstances we inherited. Ninety-four million Americans are out of the labor force. Over 43 million people are now living in poverty. And over 43 million Americans are on food stamps. ",22161), ("More than one in five people in their prime working years are not working. We have the worst financial recovery in 65 years. In the last eight years, the past administration has put on more new debt than nearly all of the other presidents combined. ",22162), ("We've lost more than one-fourth of our manufacturing jobs since Nafta was approved, and we've lost 60,000 factories since China joined the World Trade Organization in 2001. Our trade deficit in goods with the world last year was nearly $800 billion. And overseas, we have inherited a series of tragic foreign policy disasters. ",22163), ("Solving these and so many other pressing problems will require us to work past the differences of party. It will require us to tap into the American spirit that has overcome every challenge throughout our long and storied history. But to accomplish our goals at home and abroad, we must restart the engine of the American economy, making it easier for companies to do business in the United States and much, much harder for companies to leave our country. ",22164), ("Right now, American companies are taxed at one of the highest rates anywhere in the world. My economic team is developing historic tax reform that will reduce the tax rate on our companies so they can compete and thrive anywhere and with anyone. ",22165), ("It will be a big, big cut. ",22166), ("At the same time, we will provide massive tax relief for the middle class. We must create a level playing field for American companies and our workers have to do it. ",22167), ("Currently, when we ship products out of America, many other countries make us pay very high tariffs and taxes, but when foreign companies ship their products into America, we charge them nothing or almost nothing. ",22168), ("I just met with officials and workers from a great American company, Harley-Davidson. In fact, they proudly displayed five of their magnificent motorcycles, made in the U.S.A., on the front lawn of the White House. ",22169), ("And they wanted me to ride one, and I said, "No, thank you." ",22170), ("At our meeting, I asked them, "How are you doing? How is business?" They said that it's good. I asked them further, "How are you doing with other countries, mainly international sales?" ",22171), ("They told me without even complaining, because they have been so mistreated for so long that they've become used to it that it's very hard to do business with other countries, because they tax our goods at such a high rate. They said that in the case of another country, they taxed their motorcycles at 100 percent. ",22172), ("They weren't even asking for a change. But I am. I believe ... ",22173), ("I believe strongly in free trade, but it also has to be fair trade. It's been a long time since we had fair trade. ",22174), ("The first Republican president, Abraham Lincoln, warned that "the abandonment of the protective policy by the American government will produce want and ruin among our people." ",22175), ("Lincoln was right, and it's time we heeded his advice and his words. ",22176), ("I am not going to let America and its great companies and workers be taken advantage of us any longer. They have taken advantage of our country no longer. ",22177), ("I am going to bring back millions of jobs. Protecting our workers also means reforming our system of legal immigration. ",22178), ("The current, outdated system depresses wages for our poorest workers and puts great pressure on taxpayers. Nations around the world, like Canada, Australia and many others, have a merit-based immigration system. ",22179), ("It's a basic principle that those seeking to enter a country ought to be able to support themselves financially. Yet in America we do not enforce this rule, straining the very public resources that our poorest citizens rely upon. ",22180), ("According to the National Academy of Sciences, our current immigration system costs American taxpayers many billions of dollars a year. Switching away from this current system of lower-skilled immigration, and instead adopting a merit-based system, we will have so many more benefits. It will save countless dollars, raise workers' wages and help struggling families, including immigrant families, enter the middle class. And they will do it quickly, and they will be very, very happy, indeed. ",22181), ("I believe that real and positive immigration reform is possible, as long as we focus on the following goals: to improve jobs and wages for Americans, to strengthen our nation's security and to restore respect for our laws. ",22182), ("If we are guided by the well-being of American citizens, then I believe Republicans and Democrats can work together to achieve an outcome that has eluded our country for decades. ",22183), ("Another Republican president, Dwight D. Eisenhower, initiated the last truly great national infrastructure program: the building of the interstate highway system. The time has come for a new program of national rebuilding. ",22184), ("America has spent approximately $6 trillion in the Middle East, all the while our infrastructure at home is crumbling. ",22185), ("With the $6 trillion, we could have rebuilt our country twice, and maybe even three times, if we had people who had the ability to negotiate. ",22186), ("To launch our national rebuilding, I will be asking Congress to approve legislation that produces a $1 trillion investment in infrastructure of the United States, financed through both public and private capital, creating millions of new jobs. ",22187), ("This effort will be guided by two core principles: Buy American and hire American. ",22188), ("Tonight, I am also calling on this Congress to repeal and replace Obamacare ... ",22189), ("... with reforms that expand choice, increase access, lower costs and at the same time provide better health care. ",22190), ("Mandating every American to buy government-approved health insurance was never the right solution for our country. ",22191), ("The way to make health insurance available to everyone is to lower the cost of health insurance, and that is what we are going to do. ",22192), ("Obamacare premiums nationwide have increased by double and triple digits. As an example, Arizona went up 116 percent last year alone. Gov. Matt Bevin of Kentucky just said Obamacare is failing in his state, the state of Kentucky, and it's unsustainable and collapsing. ",22193), ("One third of the counties have only one insurer, and they're losing them fast, they are losing them so fast. They're leaving. And many Americans have no choice at all. There's no choice left. ",22194), ("Remember when you were told that you could keep your doctor and keep your plan? We now know that all of those promises have been totally broken. Obamacare is collapsing, and we must act decisively to protect all Americans. ",22195), ("Action is not a choice; it is a necessity. So I am calling on all Democrats and Republicans in Congress to work with us to save Americans from this imploding Obamacare disaster. ",22196), ("Here are the principles that should guide Congress as we move to create a better health care system for all Americans. ",22197), ("First, we should ensure that Americans with pre-existing conditions have access to coverage and that we have a stable transition for Americans currently enrolled in the health care exchanges. ",22198), ("Secondly, we should help Americans purchase their own coverage, through the use of tax credits and expanded health savings accounts, but it must be the plan they want, not the plan forced on them by our government. ",22199), ("Thirdly, we should give our state governors the resources and flexibility they need with Medicaid to make sure no one is left out. ",22200), ("Fourth, we should implement legal reforms that protect patients and doctors from unnecessary costs that drive up the price of insurance and work to bring down the artificially high price of drugs and bring them down immediately. ",22201), ("And finally, the time has come to give Americans the freedom to purchase health insurance across state lines ... ",22202), ("... which will create a truly competitive national marketplace that will bring costs way down and provide far better care. So important. ",22203), ("Everything that is broken in our country can be fixed. Every problem can be solved. And every hurting family can find healing and hope. Our citizens deserve this, and so much more, so why not join forces and finally get the job done and get it done right? ",22204), ("On this and so many other things, Democrats and Republicans should get together and unite for the good of our country and for the good of the American people. ",22205), ("My administration wants to work with members of both parties to make child care accessible and affordable, to help ensure new parents that they have paid family leave ... ",22206), ("... to invest in women's health, and to promote clean air and clean water, and to rebuild our military and our infrastructure. ",22207), ("True love for our people requires us to find common ground, to advance the common good, and to cooperate on behalf of every American child who deserves a much brighter future. ",22208), ("An incredible young woman is with us this evening who should serve as an inspiration to us all. Today is Rare Disease Day, and joining us in the gallery is a rare disease survivor, Megan Crowley. Megan ... ",22209), ("Megan was diagnosed with Pompe disease, a rare and serious illness, when she was 15 months old. She was not expected to live past 5. On receiving this news, Megan's dad, John, fought with everything he had to save the life of his precious child. He founded a company to look for a cure and helped develop the drug that saved Megan's life. Today she is 20 years old and a sophomore at Notre Dame. ",22210), ("Megan's story is about the unbounded power of a father's love for a daughter. But our slow and burdensome approval process at the Food and Drug Administration keeps too many advances, like the one that saved Megan's life, from reaching those in need. ",22211), ("If we slash the restraints, not just at the F.D.A. but across our government, then we will be blessed with far more miracles just like Megan. ",22212), ("In fact, our children will grow up in a nation of miracles. But to achieve this future, we must enrich the mind and the souls of every American child. Education is the civil rights issue of our time. ",22213), ("I am calling upon members of both parties to pass an education bill that funds school choice for disadvantaged youth, including millions of African-American and Latino children. ",22214), ("These families should be free to choose the public, private, charter, magnet, religious or home school that is right for them. ",22215), ("Joining us tonight in the gallery is a remarkable woman, Denisha Merriweather. As a young girl, Denisha struggled in school and failed third grade twice. But then she was able to enroll in a private center for learning great learning center with the help of a tax credit and a scholarship program. Today, she is the first in her family to graduate, not just from high school, but from college. Later this year, she will get her master's degree in social work. We want all children to be able to break the cycle of poverty just like Denisha. ",22216), ("But to break the cycle of poverty, we must also break the cycle of violence. The murder rate in 2015 experienced its largest single-year increase in nearly half a century. In Chicago, more than 4,000 people were shot last year alone, and the murder rate so far this year has been even higher. This is not acceptable in our society. ",22217), ("Every American child should be able to grow up in a safe community, to attend a great school and to have access to a high-paying job. ",22218), ("But to create this future, we must work with not against not against the men and women of law enforcement. ",22219), ("We must build bridges of cooperation and trust, not drive the wedge of disunity and it's really, it's what it is, division. It's pure, unadulterated division. We have to unify. Police and sheriffs are members of our community. They're friends and neighbors, they're mothers and fathers, sons and daughters, and they leave behind loved ones every day who worry about whether or not they'll come home safe and sound. We must support the incredible men and women of law enforcement. ",22220), ("And we must support the victims of crime. I have ordered the Department of Homeland Security to create an office to serve American victims. The office is called Voice, Victims of Immigration Crime Engagement. ",22221), ("We are providing a voice to those who have been ignored by our media and silenced by special interests. Joining us ... ",22222), ("Joining us in the audience tonight are four very brave Americans whose government failed them. Their names are Jamiel Shaw, Susan Oliver, Jenna Oliver and Jessica Davis. Jamiel's 17-year-old son was viciously murdered by an illegal immigrant gang member who had just been released from prison. Jamiel Shaw Jr. was an incredible young man with unlimited potential who was getting ready to go to college, where he would have excelled as a great college quarterback. ",22223), ("But he never got the chance. His father, who is in the audience tonight, has become a very good friend of mine. Jamiel, thank you. Thank you. ",22224), ("Also with us are Susan Oliver and Jessica Davis. Their husbands Deputy Sheriff Danny Oliver and Detective Michael Davis were slain in the line of duty in California. They were pillars of their community. These brave men were viciously gunned down by an illegal immigrant with a criminal record and two prior deportations. Should have never been in our country. ",22225), ("Sitting with Susan is her daughter, Jenna. Jenna, I want you to know that your father was a hero and that tonight you have the love of an entire country supporting you and praying for you. ",22226), ("To Jamiel, Jenna, Susan and Jessica, I want you to know that we will never stop fighting for justice. Your loved ones will never, ever be forgotten. We will always honor their memory. ",22227), ("Finally, to keep America safe, we must provide the men and women of the United States military with the tools they need to prevent war if they must they have to fight and they only have to win. ",22228), ("I am sending Congress a budget that rebuilds the military, eliminates the defense sequester... ",22229), ("... and calls for one of the largest increases in national defense spending in American history. ",22230), ("My budget will also increase funding for our veterans. Our veterans have delivered for this nation, and now we must deliver for them. ",22231), ("The challenges we face as a nation are great. But our people are even greater. And none are greater or braver than those who fight for America in uniform. ",22232), ("We are blessed to be joined tonight by Carryn Owens, the widow of U.S. Navy special operator, Senior Chief William "Ryan" Owens. Ryan died as he lived, a warrior and a hero, battling against terrorism and securing our nation. ",22233), ("I just spoke to our great General [Jim] Mattis just now who reconfirmed that, and I quote, "Ryan was a part of a highly successful raid that generated large amounts of vital intelligence that will lead to many more victories in the future against our enemy." ",22234), ("Ryan's legacy is etched into eternity. Thank you. ",22235), ("And Ryan is looking down right now. You know that. And he's very happy, because I think he just broke a record. ",22236), ("For as the Bible teaches us, there is no greater act of love than to lay down one's life for one's friends. Ryan laid down his life for his friends, for his country and for our freedom. And we will never forget Ryan. ",22237), ("To those allies who wonder what kind of a friend America will be, look no further than the heroes who wear our uniform. Our foreign policy calls for a direct, robust and meaningful engagement with the world. It is American leadership based on vital security interests that we share with our allies all across the globe. ",22238), ("We strongly support NATO, an alliance forged through the bonds of two world wars, that dethroned fascism ... ",22239), ("... and a Cold War and defeated communism. ",22240), ("But our partners must meet their financial obligations. And now, based on our very strong and frank discussions, they are beginning to do just that. In fact, I can tell you the money is pouring in. Very nice. ",22241), ("We expect our partners, whether in NATO, in the Middle East or in the Pacific, to take a direct and meaningful role in both strategic and military operations, and pay their fair share of the cost have to do that. ",22242), ("We will respect historic institutions, but we will respect the foreign rights of all nations. And they have to respect our rights as a nation, also. ",22243), ("Free nations are the best vehicle for expressing the will of the people, and America respects the right of all nations to chart their own path. My job is not to represent the world. My job is to represent the United States of America. ",22244), ("But we know that America is better off when there is less conflict, not more. We must learn from the mistakes of the past. We have seen the war and the destruction that have ravaged and raged throughout the world. All across the world. ",22245), ("The only long-term solution for these humanitarian disasters, in many cases, is to create the conditions where displaced persons can safely return home and begin the long, long process of rebuilding. ",22246), ("America is willing to find new friends, and to forge new partnerships, where shared interests align. We want harmony and stability, not war and conflict. We want peace, wherever peace can be found. America is friends today with former enemies. Some of our closest allies, decades ago, fought on the opposite side of these terrible, terrible wars. This history should give us all faith in the possibilities for a better world. ",22247), ("Hopefully, the 250th year for America will see a world that is more peaceful, more just, and more free. ",22248), ("On our 100th anniversary in 1876, citizens from across our nation came to Philadelphia to celebrate America's centennial. At that celebration, the country's builders and artists and inventors showed off their wonderful creations. Alexander Graham Bell displayed his telephone for the first time. Remington unveiled the first typewriter. An early attempt was made at electric light. Thomas Edison showed an automatic telegraph and an electric pen. Imagine the wonders our country could know in America's 250th year. ",22249), ("Think of the marvels we could achieve if we simply set free the dreams of our people. Cures to the illnesses that have always plagued us are not too much to hope. American footprints on distant worlds are not too big a dream. Millions lifted from welfare to work is not too much to expect. And streets where mothers are safe from fear schools where children learn in peace, and jobs where Americans prosper and grow are not too much to ask. ",22250), ("When we have all of this, we will have made America greater than ever before, for all Americans. This is our vision. This is our mission. But we can only get there together. We are one people, with one destiny. ",22251), ("We all bleed the same blood. We all salute the same great American flag. And we are all made by the same God. ",22252), ("When we fulfill this vision, when we celebrate our 250 years of glorious freedom, we will look back on tonight as when this new chapter of American greatness began. The time for small thinking is over. The time for trivial fights is behind us. We just need the courage to share the dreams that fill our hearts, the bravery to express the hopes that stir our souls, and the confidence to turn those hopes and those dreams into action. ",22253), ("From now on, America will be empowered by our aspirations, not burdened by our fears, inspired by the future, not bound by failures of the past, and guided by a vision, not blinded by our doubts. ",22254), ("I am asking all citizens to embrace this renewal of the American spirit. I am asking all members of Congress to join me in dreaming big and bold and daring things for our country. I am asking everyone watching tonight to seize this moment. Believe in yourselves. Believe in your future. And believe, once more, in America. ",22255), (Thank you, God bless you, and God bless the United States.,22256), ("",22257))
Cache the RDD in (distributed) memory to avoid recreating it for each action
- Above, every time we took an action on the same RDD, the RDD was reconstructed from the textfile.
- Spark's advantage compared to Hadoop MapReduce is the ability to cache or store the RDD in distributed memory across the nodes.
- Let's use
.cache()after creating an RDD so that it is in memory after the first action (and thus avoid reconstruction for subsequent actions).- count the number of elements in the RDD
sou(i.e., the number of lines in the text file/datasets/sds/souall.txt.gz) usingsou.count() - display the contents of the RDD using
takeorcollect.
- count the number of elements in the RDD
// Shift+Enter to read in the textfile as RDD[String] and cache it in distributed memory
val sou = sc.textFile("/datasets/sds/souall.txt.gz") // Cntrl+Enter to read the gzipped textfile as RDD[String]
sou.cache() // cache the RDD in memory
sou: org.apache.spark.rdd.RDD[String] = /datasets/sds/souall.txt.gz MapPartitionsRDD[11] at textFile at command-4088905069026019:2
res12: sou.type = /datasets/sds/souall.txt.gz MapPartitionsRDD[11] at textFile at command-4088905069026019:2
sou.count() // Shift+Enter during this count action the RDD is constructed from texfile and cached
res13: Long = 22258
sou.count() // Shift+Enter during this count action the cached RDD is used (notice less time taken by the same command)
res14: Long = 22258
Now, let's go to SparkUI and verify that this RDD is actually cached. The details would look something akin to the following.
| ID | RD | RDD Name | Storage Level | Cached Partitions | Fract | Fraction Cached | Si | Size in Memory | Size on Disk | |
|---|---|---|---|---|---|---|
| xxx |/d | /datasets/sds/souall.txt.gz | Memory Deserialized 1x Replicated | | 1| 10 | 100% | 20. | 20.1 MiB | | 0.0 B | |
sou.take(5) // <Cntrl+Enter> to display the first 5 elements of the cached RDD
res15: Array[String] = Array("George Washington ", "", "January 8, 1790 ", "Fellow-Citizens of the Senate and House of Representatives: ", "I embrace with great satisfaction the opportunity which now presents itself of congratulating you on the present favorable prospects of our public affairs. The recent accession of the important state of North Carolina to the Constitution of the United States (of which official information has been received), the rising credit and respectability of our country, the general and increasing good will toward the government of the Union, and the concord, peace, and plenty with which we are blessed are circumstances auspicious in an eminent degree to our national prosperity. ")
sou.getStorageLevel
res16: org.apache.spark.storage.StorageLevel = StorageLevel(memory, deserialized, 1 replicas)
Question
- what happens when we call the following now?
val souWithIndices = sou.zipWithIndex()
souWithIndices: org.apache.spark.rdd.RDD[(String, Long)] = ZippedWithIndexRDD[12] at zipWithIndex at command-69839727109975:1
Let's quickly go back to SparkUI's Storage and see what is cached now.
souWithIndices.getStorageLevel
res17: org.apache.spark.storage.StorageLevel = StorageLevel(1 replicas)
souWithIndices.count // let's call an action and look at the DAG Visualization of this job
res18: Long = 22258
What if we tried to cache souWithIndices?
souWithIndices.cache() // check SparkUI -> Storage
res19: souWithIndices.type = ZippedWithIndexRDD[12] at zipWithIndex at command-69839727109975:1
souWithIndices.count() // need to act once to actually cache it; check SparkUI -> Storage again
res20: Long = 22258
Now, you will notice that both RDDs are cached in memory now.
This is merely illustrative and makes little difference in this example. However, if you do a whole lot of transformations to an RDD and plan to use it in the immediate future then it may be worthwhile caching the intermediate RDD to save time. This is often done in iterative ML algorithms.
Lifecycle of a Spark Program - Summary
- create RDDs from:
- some external data source (such as a distributed file system)
- parallelized collection in your driver program
- lazily transform these RDDs into new RDDs
- cache some of those RDDs for future reuse
- you perform actions to execute parallel computation to produce results
Transform lines to words
- We need to loop through each line and split the line into words
- For now, let us split using whitespace
- More sophisticated regular expressions can be used to split the line (as we will see soon)
sou
.flatMap(line => line.split(" "))
.take(100)
res21: Array[String] = Array(George, Washington, "", January, 8,, 1790, Fellow-Citizens, of, the, Senate, and, House, of, Representatives:, I, embrace, with, great, satisfaction, the, opportunity, which, now, presents, itself, of, congratulating, you, on, the, present, favorable, prospects, of, our, public, affairs., The, recent, accession, of, the, important, state, of, North, Carolina, to, the, Constitution, of, the, United, States, (of, which, official, information, has, been, received),, the, rising, credit, and, respectability, of, our, country,, the, general, and, increasing, good, will, toward, the, government, of, the, Union,, and, the, concord,, peace,, and, plenty, with, which, we, are, blessed, are, circumstances, auspicious, in, an, eminent, degree, to)
Naive word count
At a first glace, to do a word count of George Washingtons SoU address, we are templed to do the following:
- just break each line by the whitespace character " " and find the words using a
flatMap - then do the
mapwith the closureword => (word, 1)to initialize eachwordwith a integer count of1- ie., transform each word to a (key, value) pair or
Tuplesuch as(word, 1)
- ie., transform each word to a (key, value) pair or
- then count all values with the same key (
wordis the Key in our case) by doing areduceByKey(_+_)
- and finally
collect()to display the results.
sou
.flatMap( line => line.split(" ") )
.map( word => (word, 1) )
.reduceByKey(_+_)
.collect()
res22: Array[(String, Int)] = Array((rebuttal.,1), (supplied.,5), (delinquents.,1), (undecaying,1), (successions,1), (Victims',1), (meets,,2), (42,427,1), (tough,44), (briefly,,2), (hemisphere.",1), (chart.,1), (fairness,,12), ($47,673,756,1), (TAX,5), ("quarantined".,1), (execute,52), (relieves,4), (afterward,1), (fight;,2), (entitlements,1), (Enjoying,,1), (unfelt,2), (requested--and,1), (8,,31), (insurrection,72), (homeland;,1), (Employees,1), (Biddle,,1), (bankruptcies,4), (178,1), (cynics,,1), (demands--problems,1), (underscored,2), (savages,,6), (Exactly,5), (47,650.00,1), (dangers,122), (pacified,1), (prohibited.,3), (disposed.,1), (Chihuahua,,1), (constant,,4), (Commerce,107), ($15,739,871,1), (edible,1), (instantaneous,1), (Level,1), ($6,879,300.93.,1), (cottons,1), (consist,,1), (unacceptable,5), (me.",2), (goods.,17), (used,,18), (Juarez,,3), (Stockton,1), (tyrant,,1), (Convention--this,1), (regulator,4), ($30-billion,1), (Pago-Pago,1), (problems.,50), (matron,2), (defiance,36), (ceased.,8), (viewed,24), (trade",1), (deservedly,2), (unforeseen,19), (ravages.,1), (1961--from,1), (1932,8), (Hills,5), (tradition--American,1), (Abusing,1), (Andrade,1), ($700,000,000,2), (Reward,1), (Clay,,2), (week--28,1), (set-tier,,1), (Congressmen.,1), (325,000.,1), (dollar's,4), (Congo's,1), ($458,544,233.03,,1), (policing.,3), (1835-36,1), (animating,3), (cities,162), (alternative,60), (strut,1), (demoralization.,3), (commodities--changes,1), (consent,,19), (workplace.,4), (comprehensiveness.,1), (renders,,2), (reiterating,1), (Accomplishing,1), (sequence,2), (panels;,1), (visible,,1), (logically,8), (Conflicts,2), ($33,784,417.95.,1), (slackness,1), (right,992), (belated,1), (insurer,1), (Saxe-Coburg,,1), (well-regulated,4), (polluters,4), (12,000,000,5), (breakwaters,1), (uninjured,1), (sham,1), (Bosphorus,2), (motor-car,1), (perpetuation,,1), (bite,,1), (degrades,1), (constructing,23), (reductions,,3), (photograph,2), (SOUTH,2), (Improved,1), (hydrogen-powered,1), (spelled,3), (impute,3), (Knowledge,3), (advance.,13), (incomparable,1), (seeing,28), ($88,922.10.,1), (Undistributed,1), (1998,4), (Palmer's,1), (organization.,27), (strangely,2), (east,39), (Mustering-out,1), (accede,,1), (anti-terrorism,1), (lines,238), (Regency.,1), (to-day;,3), (fails,19), (attributing,1), (morality.,1), (POLLUTION,1), (unimpaired,15), (Services,,2), (reestablished;,1), (veto.,9), (vessels.",1), (volcanic,1), (Truman's,1), ($10,000,000;,2), (Laws,8), (Hezbollah,,2), (tired,,1), (align,1), (archipelago,7), (beloved,34), (How,62), ((say,1), (deadweight,1), (ask--is,1), (praised,,1), (Y.--are,1), (marred,5), (11907,,1), (calamitously.,1), (affairs),,1), ($529,692,460.50.,1), (inviting,24), (small-arms,1), (hour,49), (twentieth,8), (peace--including,2), (mortal,6), (1,492,907.41,1), (conquest;,1), (sires,1), (instituted.,6), ($404,878.53,,1), (disturbed.",1), (obedience,,1), (devices,11), (Castro.,1), (anachronistic,1), (firm.,1), (Tanner,2), (modus,12), (entrance,,1), (interested?,1), (civilian,,1), (sober,,1), (interfere,60), (million.,27), (surprised,6), (nowadays,1), (cultivated.,1), (hit.,2), (murdering,4), (learnt,2), (exhausting,8), (1,154,471,762,1), (discernible,1), (excitement,,11), (devalued,,1), (strives,2), (probation.,2), (request,118), (systematically,15), (living.,32), (de-Baathification,1), (literally,,1), (roaming,1), (abstract,16), (benefactions,3), ("commitments",1), (easy.",1), ($11,000,000;,1), (154,745,782,1), (overland,,1), (Fascist,3), (gratify,5), (22,083,1), (defer,,1), (Asia;,2), (wrapped,1), (enemy.",2), (Jamestown,,2), (geographically,,1), (laboratories,7), (26,487,795.67,1), (basin.,1), (support:,1), (warms,1), (adjournment,,2), (to-day's,1), (Atlantic;,1), (Jack,,1), ($1,095,440.33,1), (wide-sweeping,1), (namely,,19), (1846.,6), (Regents,1), (Fifth,3), (waters;,2), (heightened,7), (10,240,2), (offending,10), (DISCOUNT,1), (perpetuates,1), (brotherly,3), (rations,6), (cards,4), (insurgents.,9), (arrived,55), (impromptu,1), ($2,684,220.89,,1), (soldiery,,4), (demoralization,,1), (AGRICULTURE,14), (Italian,25), (1896--more,1), (trusts.,6), (self-defeating.,1), (legally.,1), (protection.,53), (Sacramento,3), (floor,14), (order--for,1), (fourth-class,11), ($165,000,000,1), (talent,,2), (column.,1), (Coast,36), (funded,37), ($2,481,000,1), (1,464;,1), (liberated,19), (Martens,,1), (canal.,15), (renown,2), (USES,1), (throng,1), (cherish,,3), (capacities,,4), (dislike,4), (birds,6), (placing,50), (extinguishment,,2), (WOMEN,2), (people--calling,1), (Former,2), (education--at,1), (enactments,27), ("hereafter,1), (Go,4), (grew,,2), (Mount,8), (customers,10), (factor,65), (cuts,87), (turnabout,,1), (Secretly,1), (peace--making,1), ($40,000,000,6), ($27,036,389.41.,1), (equally.,2), (sue,1), (pathos,1), (deplores,1), (stabilize,15), (commerce--it,1), (asthma,,1), (mark.,2), (1823,,3), (cell.,3), (Ecuador,16), (exult,1), (robber,1), (Adversity,1), (grown,,3), (Except,6), ($100,000,000,,2), (liberalize,3), (outstripped,1), (stationary,,2), (doorways--on,1), (concern;,1), (Carolina),1), (affirmative,,2), (Lisa,1), (offer--$1.25,1), (Servia,4), (rabble-rousing,1), (commented,5), ($92,546,999;,1), (1930's--at,1), (160,000,1), ($74,065,896.99,,1), (outworn,,1), (Holland.,4), (prescriptions.,1), ($104,000,000.,1), (10?,1), (park--it's,1), (consulates,8), (inequities--then,1), (accommodations,,1), (California,,40), (untold,8), (might,,19), (prayer,13), (crises.,6), ($192,000,000,,1), (sell;,1), (wing,2), (Kyi,1), (marching,,1), (melted,1), (.outside,1), (2nd,,3), (happy,161), (converting,12), (procurement.,1), (sooner.,1), (reductions,76), (what.,1), (likened,1), (types--the,1), (agencies;,4), (inordinate,5), (712.,1), (unofficial,7), (plane.,1), (appurtenances,2), (surplus--until,1), (neglected;,1), (defined,40), (horrors,15), (country.",8), (journeyed,1), (unchallenged,2), (assuredly,12), (loyal.,1), (North-West,1), (broadcast,,1), (valor,11), ($134,178,756.96,,1), (ocean-going,2), (2001.,8), (war--in,1), (Augustine.,1), (saps,2), (consultation,,3), (forgotten;,1), (statesmen.,1), (sexual,3), (Nation--if,1), (Kosovo,,1), (weeks.,5), (wide;,1), (aggressor,,2), (Rensselaer,,1), (block,10), (unconsciously,,1), (potholes.",1), (scales,5), (Creation,1), (enormous.,1), (urgency.,4), (owners;,2), (resource"--of,1), ($2,000,000,000,1), (Allen,5), (discreditable.,1), (networks,,4), (Versailles,1), (products;,1), (Endive.,1), (tends,40), ($160,000,000.,2), (masons,,1), (entrepreneurs.,2), (below,,3), (manager,2), (to,59686), (sewer,1), (1811.,2), (sustains,6), (surely,83), (subsidies.,5), (towering,4), (reactions,1), (caution.,7), (Syria,4), (because:,1), (apples--and,1), (missionaries,,3), (Bosnia's,1), (Objections,1), (Contracts,6), (propagation,2), (quadrupled,2), ($720,039,039.79,1), (quasi-judicial,1), (wrought,,1), (BILATERAL,1), (1987,,1), (about--challenging,1), (run--free,1), (speeding,7), (fixity,3), (he,1068), (skins.,1), (democracies.",1), (embedded,1), (Emory,2), (mercantile,15), (responses,4), ($907,500,000.,1), (shortcomings,12), (subserviency,2), (families,,58), (woman.,2), (uniqueness,1), (rapidly,213), (protectorate,7), (selfishness,10), (release,59), (despair,,2), (formidable,,3), ($250,5), (1975,8), (men's,5), (qualified.,1), (dispositions,28), (mat,1), (M,2), (agriculture;,1), (projects--navigation,,1), (notes--a,2), (Blessed,3), (Monterey,2), (Shan-tung,,1), (occupants,5), (crests,1), ($6,285,294.55,1), (practices;,2), (situations--the,1), (widowers,1), ((5),6), (toils,6), ($42,818,000.,1), (facie,2), (experimenting,1), (murdered,9), (News,,1), (aviation.,2), (construction,,51), (succumbing,1), (Brandeis,1), ($3,600,1), (ARMY,5), (comprehensive,188), (seek,,5), (indefinitely,14), (town,25), (person,136), (Rudy,1), (bankrupting,1), (Ukraine's,1), ($4.128,1), (Carefully,1), (Judeo-Christian,1), (effacement,1), (charities.,1), (tight-knit,5), ($36,394,976.92,1), (Prompt,6), (aliens,34), (manual.,1), (Thirty-eighth,2), (asserted,45), (children,394), (We,3437), (Democratic,,1), (crusiers,1), (guaranteed,34), (audit,,1), (Tejeda,,2), (ill,,6), ($52,964,887.36,1), (Governors,13), (Peiping,1), (Certainly,,1), (Proliferation,1), (associates.,5), (limiting,37), (shop-worn,1), (here--not,1), (customhouses,5), (intense,14), (florins,2), (Consumer,4), ($720,000,1), (vindicated,11), (threatened,122), (deputed,6), (contention,19), (confiscation,8), (rarely,,1), (thing--the,1), (seizures,,2), (centralization.,2), (accountable.",1), (Children.,1), (defaulting,2), (gallon.,2), (thanking,1), (compete.,6), ("give,3), (29th,,7), (questions:,2), (IMPACT,1), (worry.,2), (Exemptions,,1), (ultraconservatives,1), (disturbance.,8), (House--as,1), (brotherhood,,2), (engagement.,1), (chair.,1), (cherished,32), (progrowth,1), (TRIDENT,2), (homelands,1), (satisfactory.,35), (affecting,,1), (cited,3), (safely,,3), (undisputed,,1), (prejudices,,7), (hydroelectric,5), (Conger,2), (prop,3), (Representatives.,30), (resident,,1), (10,000,000,,1), (1849,12), (motivate,1), (proprietorship,1), (Polynesian,1), (doing,192), (buses,1), (wounded,,10), ($742,000,000,,1), (decision-making.,4), (vindicate,16), (Peninsula,5), ($28,1), (DC,,1), (unforeseeable,1), (foretell,5), (unadjudicated.,1), (1947,40), (valuesthat's,1), (Experiment,2), (sectarian,7), (outcry,2), (preposition,1), (Pvt.,1), (freight,,7), (attracted,18), (Elihu,2), (disclosed,23), (fine,,5), (abroad--to,1), (territory.",1), (vague,11), (Comonfort,3), (there,2024), (4.5,5), ($9,500,000,000.,1), (computations,1), (1967,2), (easy-going,,1), (disfranchisement,2), ($247,354,1), (municipal,73), (ethic,,1), (portion,,5), (seconds.,1), (retooled.,1), (O'Neill,3), (discusses,1), ($409,967,470,,1), (expenditure.,24), (objectionable.,2), (verifying,,1), (dedicated.,2), (kindest,6), (defrayed,10), (Welland,2), (1985.,7), (exchanged,47), (prejudices,15), (1813,2), (independence.,54), (navigation.,19), (mulberry,3), (propelled,1), (append,1), ($7,000,000,000,2), (detected,7), (Protestant,,2), (verified.,3), (lengthy,6), (laws--strengthening,1), (bestowal,5), (Convention,48), (income--that,1), (organs",1), (contributed,60), (opinion;,3), ($55,402,465.46.,2), (Hubert,2), ($3,473,922,055,,1), (leadership;,1), (speedier,2), (coins,,3), (purposes--the,1), (multitude,17), (unsoundness,1), (historian,,1), (hemisphere;,1), (crafty,1), (ores,,1), (rounds.,1), (probable,99), (revealed,16), (Connecting,2), (bribe-giver,,1), (reclamation,,2), (helpfulness,2), (Clean,5), (discriminating,,1), (tribute.,2), (credence,1), ($79,333,966.,1), (efficacious,,1), (stems,1), (definite.,2), (computation,1), (Producers,1), (Third.,11), (styling,1), ($23,747,864.66,,1), (contribution.,3), ((except,5), (parliamentary,6), (anyplace,1), (extraordinaries,1), (warmly,6), (rectification,2), (purification,2), (rule-making,1), (militia;,1), (inspire,34), (articles,226), (136,2), (monarchy,,1), (&,6), (transformations,1), (intimidation,,3), (Coinciding,1), (pay--so,1), (Justices,3), (whereby,,2), (Empire.,22), (resisted;,1), (betterments,2), (heavy.,2), (four-point,2), (compel,41), (allotting,2), (Low,,1), (Peace,55), (natural.,2), (charitable,14), (unscrupulously,1), (tree,3), (permits,31), (prohibited.",1), (archives,14), (annuities,,2), (fancied,,1), (animosities.,1), (subjection.,1), (respected,29), (Kickapoo,,1), (offensive,,8), (LAWS,4), (research,,32), (writer,1), (Forty-Five,1), (workload,2), (chances,19), (21,000,1), (preventable,9), (towards,47), (carefully-phased,1), (Contreras,1), (composite,1), (convey,12), (safety--these,,1), (exclusion.,2), (commander,,7), (24,557,409,1), (gelatine,1), (modicum,1), (plants,45), (defensible.,1), (Board;,1), ($8,967,609,1), (fetters.",1), (gunnery,3), (inward.,1), (five-sixths,1), (world?,2), (nation--an,1), (AMPHITHEATER,1), (entering.,1), (reaffirmations,1), (J.M.,1), (caps,2), (4o67,1), (restoration,,3), (launch,23), (brow.",1), (reminiscent,1), (originated.",1), (rents.,1), (navigate,3), ($110,000,000,1), (podium,,4), (1977:,1), (permissible,,1), (14,410,1), (penalizes,2), (couch,1), (ends:,2), (Optimistic,1), (slightest,51), (sped,1), (Republics.",1), (advance;,2), (rebuilds,1), (compelling,16), (militia,,28), (reconsideration.,2), (truly,92), (bestowed,36), (hastened,7), (locally,,1), (residence.,3), (hedge,1), (shortness,2), (promiscuous,1), (sum,,21), (Policy",1), (wool,,2), (harshest,1), (symbolically,1), ("accepted",1), (testament,2), (prepare,91), (undecided,3), (Pa.,,1), (Charlotte,,2), (admission,106), (confirms,9), (unseeing,1), (valuation,,6), (truthful,3), (self-examination,1), ($24,829,163.54,1), ($215,725,995,,1), (governments--it,1), (Danish,11), (772,700,000,1), (1956.,1), (splendidly,2), (firearms,2), (mobile,5), (loving,5), (Treasure,1), (ministrations,1), (outposts,3), (obligations.",1), (inspecting,,1), (Apprehending,,1), (expatriation,,8), (idealism,8), (accounts.,11), (confessions,3), (temples,1), (unmodified.,1), (expediency,,3), (Hill,2), (longevity,1), ($800,000,000,1), (philosophy,11), (instrumental.,1), (genuine.,1), (barred,,1), (today,189), (Hay-Pauncefote,1), (braking,1), (7,000,000.,1), (75,000.,1), (Liverpool,4), (Strategically,,1), (Tokugawa,,1), (autos,,1), (254,550.00,1), (money,611), ($1,431,565.78.,1), (chieftain,1), (But--I,1), (denatured,2), (mailing,2), (1,297.,1), (patriotic,115), (universal,85), (1954,,4), (rededicate,5), (utterance,1), (work--two,1), (myself,,14), (monarchy.,2), (uneasy,3), (online,2), (upper,16), (patrolling,3), (30,000,000,2), (disappeared.,3), (depredations,36), (oppressors,,1), (vigorously,43), (Sandinistas,5), ($27,4), (begging,1), (dreary,,1), (deeds,22), (examination,,18), (CONDITION,2), (rocket,4), ($71,226,846,,1), (subjects--there,1), (asked:,1), (appropriating,21), ("states,1), (0111,,1), (perspective,7), (wits,1), (deposit.,3), (them--we,1), (shooting,,1), (rub.,1), (badly.",1), (Leasing,2), (1767,1), (Leonard,3), (FBI,9), (154,747,1), (Hoods,1), (lofty,,1), (anti-recessionary,1), (problem;,1), (Massachusetts,11), (nicest,1), (1787.,3), (believe.,3), (OUR,19), (unify.,1), (graduation,21), (choices,,12), ("unconstitutional,",1), (opinions,,14), (materialistic,,1), (midshipman,2), (pictures,2), (Sackville,1), (best-prepared,2), (twenty.,1), (fields,,9), (expedients,16), (1923,,1), (complied,33), (astronomical,6), (seize.,1), (careful.,1), (secession;,1), (Majority,5), (matters.,10), (premises,16), (happy,,7), (handle,20), (strange,,2), (believed,,72), (sites,26), ("because,1), (incursion,,1), ("Her,1), (rabbits,,1), (fishermen.,2), (independent-treasury,1), (recognized,174), (sloops,6), (Pupils,1), (terrorism.,10), (flag,,30), (auxiliary.,1), (alliances,29), (80,500,000,1), (1,074,974.35,,1), (larger,239), ($18,000,000,,1), (Fewer,1), (incompleteness,1), (style,,2), (Yakutsk,1), (Arenas,1), (instructs,1), (test,,2), (blasting,1), (Durango,1), (stress,,1), (success.,91), (calm,,4), ($11,507,670.,1), (year--to,1), (long,918), (modified.,6), (happier?,1), (loading,1), (reduced--and,1), (predominate,1), (armistice.,1), (availing,7), (sailing,17), (at,6519))
Unfortunately, as you can see from the collect above:
- the words have punctuations at the end which means that the same words are being counted as different words. Eg: importance
- empty words are being counted
So we need a bit of regex'ing or regular-expression matching (all readily available from Scala via Java String types).
We will cover the three things we want to do with a simple example from Middle Earth!
- replace all multiple whitespace characters with one white space character " "
- replace all punction characters we specify within
[and]such as[,?.!:;]by the empty string""(i.e., remove these punctuation characters) - convert everything to lower-case.
val example = "Master, Master! It's me, Sméagol... mhrhm*%* But they took away our precious, they wronged us. Gollum will protect us..., Master, it's me Sméagol."
example: String = Master, Master! It's me, Sméagol... mhrhm*%* But they took away our precious, they wronged us. Gollum will protect us..., Master, it's me Sméagol.
example
.replaceAll("\\s+", " ") //replace multiple whitespace characters (including space, tab, new line, etc.) with one whitespace " "
.replaceAll("""([,?.!:;])""", "") // replace the following punctions characters: , ? . ! : ; . with the empty string ""
.toLowerCase() // converting to lower-case
res23: String = master master it's me sméagol mhrhm*%* but they took away our precious they wronged us gollum will protect us master it's me sméagol
More sophisticated word count
We are now ready to do a word count of George Washington's SoU on January 8th 1790 as follows:
val wordCount_sou =
sou.flatMap(line =>
line.replaceAll("\\s+", " ") //replace multiple whitespace characters (including space, tab, new line, etc.) with one whitespace " "
.replaceAll("""([,?.!:;])""", "") // replace the following punctions characters: , ? . ! : ; . with the empty string ""
.toLowerCase() // converting to lower-case
.split(" ")
).map(x => (x, 1))
.reduceByKey(_+_)
wordCount_sou.count // there are 34812 distinct words
wordCount_sou: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[19] at reduceByKey at command-4088905069026032:8
res24: Long = 34812
wordCount_sou.take(30) // some of the counts are
res25: Array[(String, Int)] = Array((reunion,9), ($654137907-89,1), (divisional,1), (devices--except,1), (successions,1), (undecaying,1), (instant--in,1), ($668000000,1), (subdivided,1), (b-1b,1), (american-british,1), (fuller,24), (leeway,1), (instrumentality,20), (tough,52), (countervail,3), (crying,12), (governments--or,1), (snatch,2), (breath,5), (boldest,1), (delusion,14), (execute,53), (relieves,4), (nonunion,2), (minorities,20), (afterward,2), (ignore,32), (entitlements,5), (eventuality,1))
val top10 = wordCount_sou.sortBy(_._2, false).take(10) // sorted by most frequent words limited to top 10
top10: Array[(String, Int)] = Array((the,150091), (of,97090), (and,60810), (to,60725), (in,38660), (a,27935), (that,21657), (for,19014), (be,18727), (our,17440))
souWithIndices
.filter(lineWithIndex => (22258-148 < lineWithIndex._2 && lineWithIndex._2 <= 22258) // line numbers for Donlad Trump's 2017 SOU
|| lineWithIndex._2 < 30 // line numbers for George Washington's first SoU
)
.map( lineWithIndex => lineWithIndex._1 )
.flatMap(line =>
line.replaceAll("\\s+", " ") //replace multiple whitespace characters (including space, tab, new line, etc.) with one whitespace " "
.replaceAll("""([,?.!:;])""", "") // replace the following punctions characters: , ? . ! : ; . with the empty string ""
.toLowerCase() // converting to lower-case
.split(" "))
.map(x => (x,1))
.reduceByKey(_+_)
.sortBy(_._2, false)
.collect()
res26: Array[(String, Int)] = Array((the,344), (and,260), (of,230), (to,211), (our,129), (a,121), (we,104), (in,103), (that,81), (is,71), (will,71), (for,66), (have,57), (i,52), (be,48), (with,47), (as,39), (by,39), (are,38), (from,35), (all,35), (you,35), (on,34), (american,33), (this,32), (they,32), (not,32), (but,30), (it,28), (america,27), (their,27), (country,26), (an,24), (us,22), (at,22), (which,22), (so,21), (new,20), (who,20), (great,20), (must,20), (one,18), (united,18), (world,17), (people,17), (has,17), (should,17), (was,16), (states,16), (very,16), (my,15), (am,15), (those,15), (americans,15), (more,15), (citizens,14), (just,14), (your,14), ("",14), (been,13), (them,13), (tonight,13), (now,13), (nation,13), (many,13), (national,13), (can,13), (other,12), (government,12), (every,12), (time,11), (his,11), (work,11), (across,10), (also,10), (thank,10), (year,10), (do,10), (public,10), (down,10), (it's,10), (its,9), (free,9), (much,9), (want,9), (health,9), (when,9), (home,9), (jobs,9), (than,9), (right,8), (immigration,8), (made,8), (good,8), (congress,8), (last,8), (out,8), (believe,8), (children,8), (or,8), (system,8), (first,8), (since,8), (state,8), (future,8), (support,8), (we've,8), (foreign,7), (he,7), (long,7), (need,7), (nations,7), (create,7), (companies,7), (know,7), (where,7), (were,7), (justice,7), (help,7), (years,7), (only,7), (what,7), (billions,6), (high,6), (if,6), (allies,6), (millions,6), (even,6), (may,6), (no,6), (trade,6), (workers,6), (care,6), (rights,6), (asking,6), (then,6), (get,6), (dollars,6), (too,6), (into,6), (never,6), (keep,6), (tax,6), (finally,6), (respect,6), (same,6), (security,6), (members,6), (life,6), (she,6), (friends,6), (infrastructure,6), (make,6), (me,6), (past,6), (administration,6), (better,6), (against,6), (military,6), (find,5), (community,5), (department,5), (further,5), (access,5), (had,5), (interests,5), (able,5), (school,5), (safe,5), (credit,5), (law,5), (peace,5), (there,5), (obamacare,5), (protect,5), (choice,5), (child,5), (history,5), (laws,5), (would,5), (men,5), (house,5), (up,5), (today,5), (like,5), (going,5), (middle,5), (families,5), (such,5), (fair,5), (plan,5), (because,5), (war,5), (measures,5), (over,5), (these,5), (rate,5), (women,5), (love,5), (insurance,5), (hope,5), (own,5), (provide,5), (dreams,5), (greater,4), (end,4), (megan,4), (proper,4), (megan's,4), (bring,4), (stop,4), (throughout,4), (big,4), (trillion,4), (well,4), (spirit,4), (affairs,4), (regard,4), (joining,4), (representatives,4), (countries,4), (ought,4), (wages,4), (increase,4), (while,4), (250th,4), (terrorism,4), (oliver,4), (means,4), (recent,4), (allow,4), (leave,4), (become,4), (family,4), (jenna,4), (truly,4), (said,4), (drug,4), (jamiel,4), (best,4), (way,4), (senate,4), (resources,4), (blessed,4), (look,4), (program,4), (incredible,4), (job,4), (general,4), (defense,4), (require,4), (both,4), (save,4), (two,4), (another,4), (uniform,4), (could,4), (come,4), (ryan,4), (directed,4), (costs,4), (together,4), (borders,4), (her,4), (rule,4), (susan,4), (take,4), (they're,4), (old,3), (republicans,3), (price,3), (veterans,3), (cities,3), (jessica,3), (defend,3), (everyone,3), (creating,3), (regulations,3), (celebrate,3), (taxpayers,3), (business,3), (president,3), (seen,3), (thousands,3), (victims,3), (immigrant,3), (tens,3), (serve,3), (ensure,3), (calling,3), (done,3), (importance,3), (confidence,3), (others,3), (nothing,3), (any,3), (task,3), (million,3), (circumstances,3), (duty,3), (day,3), (record,3), (render,3), (working,3), (back,3), (far,3), (grow,3), (disease,3), (drugs,3), (information,3), (direct,3), (poverty,3), (session,3), (common,3), (force,3), (financial,3), (democrats,3), (deserve,3), (learning,3), (private,3), (davis,3), (expect,3), (current,3), (constitution,3), (ones,3), (cycle,3), (including,3), (promises,3), (necessary,3), (object,3), (class,3), (give,3), (friend,3), (nearly,3), (here,3), (rebuilding,3), (present,3), (policy,3), (brave,3), (loved,3), (before,3), (vision,3), (gallery,3), (8,3), (break,3), (whether,3), (satisfaction,3), (freedom,3), (share,3), (cannot,3), (important,3), (saved,3), (through,3), (historic,3), (guided,3), (honor,3), (cooperation,3), (between,3), (strong,3), (enforcement,3), (center,3), (union,3), (again,3), (college,3), (according,3), (fact,3), (decades,3), (achieve,3), (denisha,3), (abroad,3), (terrible,3), (god,3), (ban,3), (crime,3), (rare,3), (young,3), (shot,2), (behind,2), (less,2), (part,2), (we're,2), (toward,2), (disasters,2), (small,2), (trillions,2), (torch,2), (vetting,2), (washington,2), (third,2), (inherited,2), (east,2), (meeting,2), (poorest,2), (enter,2), (integrity,2), (things,2), (lay,2), (came,2), (george,2), (twice,2), (largest,2), (left,2), (illegal,2), (civil,2), (souls,2), (buy,2), (spoke,2), (office,2), (equal,2), (greatness,2), (inside,2), (persuaded,2), (showed,2), (fight,2), (lawless,2), (let,2), (mr,2), (goods,2), (due,2), (jewish,2), (nato,2), (welfare,2), (themselves,2), (message,2), ("how,2), (essential,2), (happy,2), (communities,2), (off,2), (reason,2), (anniversary,2), (capital,2), (develop,2), (moment,2), (one's,2), (course,2), (within,2), (displayed,2), (ready,2), (bridges,2), (everything,2), (43,2), (embrace,2), (plenty,2), (add,2), (beginning,2), (threaten,2), (shaw,2), (consideration,2), (miracles,2), (parts,2), (given,2), (budget,2), (taxed,2), (branch,2), (form,2), (gentlemen,2), (leaving,2), (neighbors,2), (lincoln,2), (border,2), (spent,2), (mothers,2), (promised,2), (wanted,2), (reach,2), (strongly,2), (ignored,2), (joined,2), (upon,2), (think,2), (opportunity,2), (approve,2), (threats,2), (opinion,2), (doing,2), (250,2), (america's,2), (drive,2), (chicago,2), (former,2), (value,2), (canada,2), (delivered,2), (prepared,2), (almost,2), (celebration,2), (legal,2), (losing,2), (derive,2), (along,2), (immediately,2), (wars,2), (longer,2), (chapter,2), (slow,2), (lost,2), (learn,2), (crumbling,2), (badly,2), (kentucky,2), (man,2), (fantastic,2), (food,2), (invest,2), (intelligence,2), (attention,2), (based,2), (principles,2), (legislature,2), (large,2), (republican,2), (father,2), (lifetime,2), (goals,2), (told,2), (youth,2), (conflict,2), (month,2), (economy,2), (alone,2), (process,2), (most,2), (raise,2), (skill,2), (degree,2), (persons,2), (places,2), (motorcycles,2), (intercourse,2), (broken,2), (answered,2), (encouragement,2), (election,2), (percent,2), (represent,2), (asked,2), (effectual,2), (begin,2), (meaningful,2), (society,2), (i've,2), (fought,2), (provision,2), (electric,2), (laid,2), (currently,2), (commerce,2), (quiet,2), (scalia,2), (afford,2), (audience,2), (hopes,2), (chorus,2), ($6,2), (lead,2), (collapsing,2), (solution,2), (prime,2), (land,2), (engagement,2), (voice,2), (products,2), (clean,2), (distinguish,2), (about,2), (favorable,2), (distant,2), (ask,2), (live,2), (shall,2), (special,2), (southern,2), (bless,2), (1790,2), (coverage,2), (pacific,2), (still,2), (once,2), (pleasing,2), (fill,2), (particularly,2), (advantage,2), (patriotism,2), (officers,2), (financed,2), (restore,2), (pouring,2), (expand,2), (promote,2), (overseas,2), (owens,2), (among,2), (speak,2), (various,2), (fast,2), (partners,2), (construction,2), (failed,2), (merit-based,2), (papers,2), (steps,2), (parties,2), (blessings,2), (pay,2), (pipelines,2), (fellow-citizens,2), (effort,2), (anyone,2), (fulfill,2), (deliver,2), (see,2), (ordered,2), (why,2), (renewal,2), (inner,2), (prosperity,2), (stock,2), (vital,2), (hero,2), (murder,2), (cost,2), (officials,2), (act,2), (maureen,2), (20,2), (attacks,2), (reform,2), (action,2), (trust,2), (reforms,2), (nation's,2), (ship,2), (gang,2), (taken,2), (join,2), (education,2), (viciously,2), (reduce,2), (deeply,2), (calls,2), (company,2), (ever,2), (division,2), (kind,2), (purchase,2), (light,2), (respectability,2), (anywhere,2), (criminal,2), (imposing,2), (individuals,2), (use,2), (safety,2), (conditions,2), (daughter,2), (five,2), (homeland,2), (alliance,2), (placed,2), (court,2), (put,2), (progress,2), (path,2), (woman,2), (mistakes,2), (enforce,2), (prospects,2), (liberty,2), (providing,2), (always,2), (lower,2), (became,2), (justin,1), (accession,1), (surge,1), (desirable,1), (secure,1), (dismantle,1), (germany,1), (federal,1), (unveiled,1), (weights,1), (looking,1), (inevitable,1), (supporting,1), (discriminate,1), (entry,1), (partnership,1), (bears,1), (well-being,1), (safely,1), (bad,1), (eight,1), (punish,1), (son,1), (swamp,1), (strength,1), (tragic,1), (chosen,1), (heroic,1), (official,1), (series,1), (received),1), (fourth,1), (lived,1), (increases,1), (satisfactory,1), (footprints,1), (sciences,1), (unnecessary,1), (found,1), (commonwealth,1), (totally,1), (builders,1), (latter,1), (savages,1), (shrink,1), (china,1), (discussions,1), (graduate,1), (uniting,1), (divided,1), (produces,1), (foe,1), (trans-pacific,1), (antonin,1), (giving,1), (project,1), (networks,1), (win,1), (names,1), (exigencies,1), (months,1), (keystone,1), (firmly,1), (weren't,1), (approval,1), (undertaken,1), (blood,1), (fighter,1), (went,1), (insurer,1), (post-roads,1), (pentagon,1), (field,1), (entirely,1), (truth,1), (husband,1), (refused,1), (lobbyists,1), (bravery,1), (genius,1), (legacy,1), (go,1), (harm,1), (agency,1), (repeal,1), (daring,1), (precious,1), (lines,1), (eliminates,1), (congratulating,1), (country's,1), (accounts,1), (vehicle,1), (endeavors,1), (richly,1), (exertions,1), (detroit,1), (outcome,1), (align,1), (released,1), (muslims,1), (efforts,1), (supplies,1), (unemployed,1), (confirmed,1), (senior,1), (city,1), (developing,1), (compensation,1), (adopted,1), (carolina,1), (declaration,1), (obviously,1), (worlds,1), (recommendation,1), (reminded,1), (enemies,1), (open,1), (ford,1), (defeated,1), (facilitated,1), (forged,1), (taking,1), (forgotten,1), (raid,1), (coordinate,1), (perceive,1), (marine,1), (hands,1), (choose,1), (struggled,1), (doubts,1), (father's,1), (attended,1), (rebirth,1), (judge,1), (formed,1), (bible,1), (globe,1), (belgium,1), (muslim,1), (watching,1), (flexibility,1), (john,1), (pressure,1), (sequester,1), (last--and,1), (ravaged,1), (little,1), (speedily,1), (inventors,1), (d,1), (pour,1), (deficit,1), (enemy,1), (jr,1), (african-american,1), (considerations,1), (entire,1), (2016,1), (creations,1), (tariffs,1), (institutions,1), (dakota,1), (salute,1), (markets,1), (jamiel's,1), (engagements,1), (forget,1), (earth,1), (placing,1), (unanimously,1), (extremists,1), (appoint,1), (level,1), (protective,1), (dream,1), (perfect,1), (social,1), (impressions,1), (j,1), (question,1), (produce,1), (forces,1), (quote,1), (he's,1), (circumstance,1), (sales",1), (conducive,1), (obligation,1), (say,1), (basis,1), (defended,1), (investment,1), (tools,1), (cures,1), (fellow,1), (job-crushing,1), (saw,1), (crucial,1), (consultations,1), (countless,1), (cherishing,1), (protecting,1), (water,1), (experienced,1), (navy,1), (religious,1), (manufacturing,1), (side,1), (survivor,1), (ground,1), (faith,1), (teaching,1), (worthy,1), (cleared,1), (they've,1), (france,1), (fda,1), (pleasure,1), (resuming,1), (stamps,1), (extinguish,1), (glorious,1), (nice,1), (operations,1), (optimism,1), (strategy,1), (proud,1), (abandonment,1), (defined,1), (inviolable,1), (philadelphia,1), (inspired,1), (fighting,1), (illnesses,1), (helped,1), (return,1), (burdened,1), (novelty,1), (advances,1), (replace,1), (reconfirmed,1), (girl,1), (later,1), (global,1), (data,1), (slain,1), (died,1), (sheriffs,1), (destruction,1), (1876,1), (rely,1), (expected,1), (100th,1), (easier,1), (council,1), (dethroned,1), (boston,1), (close,1), (manner,1), (rebellion,1), (role,1), (ago,1), (governors,1), (they'll,1), (affording,1), (adequate,1), (deep,1), (declared,1), (restart,1), (sanctions,1), (turned,1), (loud,1), (core,1), (debt,1), (list,1), (provisions,1), (kansas,1), (specify,1), (unadulterated,1), (credits,1), (uphold,1), (wonder,1), (call,1), (beliefs,1), (2017,1), (fund,1), (protection,1), (improve,1), (campaign,1), (unlimited,1), (restraints,1), (ways--by,1), (recommended,1), (mercantile,1), (thirdly,1), (double,1), (speedy,1), (wherever,1), (funding,1), (silenced,1), (2015,1), (hard,1), (vandalism,1), (introduction,1), (dealers,1), (thomas,1), (colors,1), (contained,1), (flag,1), (intel,1), (story,1), (terrorism-related,1), (murdered,1), (vice,1), (slash,1), (tap,1), (trudeau,1), (rebuilt,1), (january,1), (bold,1), (violence,1), (israel,1), (ability,1), (founded,1), (ballistic,1))
YouTry: HOMEWORK
- HOWEWORK WordCount 1:
sortBy - HOMEWORK WordCount 2:
dbutils.fs- for databricks environment only; won't work in zeppelin which may use hdfs or local file system or another
HOMEWORK WordCount 1. sortBy
Let's understand sortBy a bit more carefully.
val example = "Master, Master! It's me, Sméagol... mhrhm*%* But they took away our precious, they wronged us. Gollum will protect us..., Master, it's me Sméagol."
example: String = Master, Master! It's me, Sméagol... mhrhm*%* But they took away our precious, they wronged us. Gollum will protect us..., Master, it's me Sméagol.
val sou = sc.textFile("/datasets/sds/souall.txt.gz")
sou: org.apache.spark.rdd.RDD[String] = /datasets/sds/souall.txt.gz MapPartitionsRDD[32] at textFile at command-4088905069026050:1
val rddWords = sou
.flatMap(line =>
line.replaceAll("\\s+", " ") //replace multiple whitespace characters (including space, tab, new line, etc.) with one whitespace " "
.replaceAll("""([,?.!:;])""", "") // replace the following punctions characters: , ? . ! : ; . with the empty string ""
.toLowerCase() // converting to lower-case
.split(" ")) // split by single whitespace
rddWords: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[33] at flatMap at command-4088905069026051:2
rddWords.take(10)
res27: Array[String] = Array(george, washington, "", january, 8, 1790, fellow-citizens, of, the, senate)
val wordCounts = rddWords
.map(x => (x,1))
.reduceByKey(_+_)
wordCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[35] at reduceByKey at command-4088905069026053:3
val top10 = wordCounts.sortBy(_._2, false).take(10)
top10: Array[(String, Int)] = Array((the,150091), (of,97090), (and,60810), (to,60725), (in,38660), (a,27935), (that,21657), (for,19014), (be,18727), (our,17440))
Make your code easy to read for other developers ;) Use 'case classes' with well defined variable names that everyone can understand
val top10 = wordCounts.sortBy(
{
case (word, count) => count
}, false) // here false says the order is not ascending
.take(10)
top10: Array[(String, Int)] = Array((the,150091), (of,97090), (and,60810), (to,60725), (in,38660), (a,27935), (that,21657), (for,19014), (be,18727), (our,17440))
If you just want a total count of all words in the file
rddWords.count
res28: Long = 1778012
YoutTry: HOMEWORK WordCount 2: dbutils.fs
Have a brief look at what other commands dbutils.fs supports. We will introduce them as needed in databricks
- This is for databricks environment only;
dbutils.fswon't work in zeppelin which may use hdfs or local file system or another
dbutils.fs.help // some of these were used to ETL this data into /datasets/sds/sou
For more info about a method, use dbutils.fs.help("methodName").
In notebooks, you can also use the %fs shorthand to access DBFS. The %fs shorthand maps straightforwardly onto dbutils calls. For example, "%fs head --maxBytes=10000 /file/path" translates into "dbutils.fs.head("/file/path", maxBytes = 10000)".
mount
mount(source: String, mountPoint: String, encryptionType: String = "", owner: String = null, extraConfigs: Map = Map.empty[String, String]): boolean -> Mounts the given source directory into DBFS at the given mount pointmounts: Seq -> Displays information about what is mounted within DBFS
refreshMounts: boolean -> Forces all machines in this cluster to refresh their mount cache, ensuring they receive the most recent information
unmount(mountPoint: String): boolean -> Deletes a DBFS mount point
updateMount(source: String, mountPoint: String, encryptionType: String = "", owner: String = null, extraConfigs: Map = Map.empty[String, String]): boolean -> Similar to mount(), but updates an existing mount point (if present) instead of creating a new one
fsutils
cp(from: String, to: String, recurse: boolean = false): boolean -> Copies a file or directory, possibly across FileSystemshead(file: String, maxBytes: int = 65536): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8
ls(dir: String): Seq -> Lists the contents of a directory
mkdirs(dir: String): boolean -> Creates the given directory if it does not exist, also creating any necessary parent directories
mv(from: String, to: String, recurse: boolean = false): boolean -> Moves a file or directory, possibly across FileSystems
put(file: String, contents: String, overwrite: boolean = false): boolean -> Writes the given String out to a file, encoded in UTF-8
rm(dir: String, recurse: boolean = false): boolean -> Removes a file or directory
Feel free to explore syntax by writing your own codes in your notebooks.
Piped RDDs and More
This is a very useful but Advanced Topic.
This notebooks, demonstrates how you can go through Chapters of the recommended book Spark: The Definitive Guide and get your hands dirty with the codes in it to learn by coding, in addition to reading.
Here we will first take excerpts with minor modifications from the end of Chapter 12. Resilient Distributed Datasets (RDDs) of Spark: The Definitive Guide:
- https://learning.oreilly.com/library/view/spark-the-definitive/9781491912201/ch12.html
Next, we will do Bayesian AB Testing using PipedRDDs.
First, we create the toy RDDs as in The Definitive Guide:
From a Local Collection
To create an RDD from a collection, you will need to use the parallelize method on a SparkContext (within a SparkSession). This turns a single node collection into a parallel collection. When creating this parallel collection, you can also explicitly state the number of partitions into which you would like to distribute this array. In this case, we are creating two partitions:
val myCollection = "Spark The Definitive Guide : Big Data Processing Made Simple" .split(" ")
val words = spark.sparkContext.parallelize(myCollection, 2)
myCollection: Array[String] = Array(Spark, The, Definitive, Guide, :, Big, Data, Processing, Made, Simple)
words: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at command-4088905069025460:2
glom from The Definitive Guide
glomis an interesting function that takes every partition in your dataset and converts them to arrays. This can be useful if you’re going to collect the data to the driver and want to have an array for each partition. However, this can cause serious stability issues because if you have large partitions or a large number of partitions, it’s simple to crash the driver.
Let's use glom to see how our words are distributed among the two partitions we used explicitly.
words.glom.collect
res1: Array[Array[String]] = Array(Array(Spark, The, Definitive, Guide, :), Array(Big, Data, Processing, Made, Simple))
Checkpointing from The Definitive Guide
One feature not available in the DataFrame API is the concept of checkpointing. Checkpointing is the act of saving an RDD to disk so that future references to this RDD point to those intermediate partitions on disk rather than recomputing the RDD from its original source. This is similar to caching except that it’s not stored in memory, only disk. This can be helpful when performing iterative computation, similar to the use cases for caching:
Let's create a directory for checkpointing of RDDs in the sequel.
mkdirs /datasets/sds/ScaDaMaLe/checkpointing/
res2: Boolean = true
spark.sparkContext.setCheckpointDir("/datasets/sds/ScaDaMaLe/checkpointing")
words.checkpoint()
Now, when we reference this RDD, it will derive from the checkpoint instead of the source data. This can be a helpful optimization.
YouTry
Just some more words in haha_words with \n, the End-Of-Line (EOL) characters, in-place.
val haha_words = sc.parallelize(Seq("ha\nha", "he\nhe\nhe", "ho\nho\nho\nho"),3)
haha_words: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[2] at parallelize at command-4088905069025471:1
Let's use glom to see how our haha_words are distributed among the partitions
haha_words.glom.collect
res4: Array[Array[String]] =
Array(Array(ha
ha), Array(he
he
he), Array(ho
ho
ho
ho))
Pipe RDDs to System Commands
The pipe method is probably one of Spark’s more interesting methods. With pipe, you can return an RDD created by piping elements to a forked external process. The resulting RDD is computed by executing the given process once per partition. All elements of each input partition are written to a process’s stdin as lines of input separated by a newline. The resulting partition consists of the process’s stdout output, with each line of stdout resulting in one element of the output partition. A process is invoked even for empty partitions.
The print behavior can be customized by providing two functions.
We can use a simple example and pipe each partition to the command wc. Each row will be passed in as a new line, so if we perform a line count, we will get the number of lines, one per partition:
The following produces a PipedRDD:
val wc_l_PipedRDD = words.pipe("wc -l")
wc_l_PipedRDD: org.apache.spark.rdd.RDD[String] = PipedRDD[4] at pipe at command-4088905069025476:1
Now, we take an action via collect to bring the results to the Driver.
NOTE: Be careful what you collect! You can always write the output to parquet of binary files in dbfs:/// if the returned output is large.
wc_l_PipedRDD.collect
res5: Array[String] = Array(5, 5)
In this case, we got the number of lines returned by wc -l per partition.
YouTry
Try to make sense of the next few cells where we do NOT specifiy the number of partitions explicitly and let Spark decide on the number of partitions automatically.
val haha_words = sc.parallelize(Seq("ha\nha", "he\nhe\nhe", "ho\nho\nho\nho"),3)
haha_words.glom.collect
val wc_l_PipedRDD_haha_words = haha_words.pipe("wc -l")
wc_l_PipedRDD_haha_words.collect()
haha_words: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[5] at parallelize at command-4088905069025483:1
wc_l_PipedRDD_haha_words: org.apache.spark.rdd.RDD[String] = PipedRDD[7] at pipe at command-4088905069025483:3
res6: Array[String] = Array(2, 3, 4)
Do you understand why the above collect statement returns what it does?
val haha_words_again = sc.parallelize(Seq("ha\nha", "he\nhe\nhe", "ho\nho\nho\nho"))
haha_words_again.glom.collect
val wc_l_PipedRDD_haha_words_again = haha_words_again.pipe("wc -l")
wc_l_PipedRDD_haha_words_again.collect()
haha_words_again: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[8] at parallelize at command-4088905069025485:1
wc_l_PipedRDD_haha_words_again: org.apache.spark.rdd.RDD[String] = PipedRDD[10] at pipe at command-4088905069025485:3
res7: Array[String] = Array(2, 7)
Did you understand why some of the results are 0 in the last collect statement?
mapPartitions
The previous command revealed that Spark operates on a per-partition basis when it comes to actually executing code. You also might have noticed earlier that the return signature of a map function on an RDD is actually
MapPartitionsRDD.
Or ParallelCollectionRDD in our case.
This is because map is just a row-wise alias for
mapPartitions, which makes it possible for you to map an individual partition (represented as an iterator). That’s because physically on the cluster we operate on each partition individually (and not a specific row). A simple example creates the value “1” for every partition in our data, and the sum of the following expression will count the number of partitions we have:
words.mapPartitions(part => Iterator[Int](1)).sum() // 2.0
res8: Double = 2.0
Naturally, this means that we operate on a per-partition basis and therefore it allows us to perform an operation on that entire partition. This is valuable for performing something on an entire subdataset of your RDD. You can gather all values of a partition class or group into one partition and then operate on that entire group using arbitrary functions and controls. An example use case of this would be that you could pipe this through some custom machine learning algorithm and train an individual model for that company’s portion of the dataset. A Facebook engineer has an interesting demonstration of their particular implementation of the pipe operator with a similar use case demonstrated at Spark Summit East 2017.
Other functions similar to
mapPartitionsincludemapPartitionsWithIndex. With this you specify a function that accepts an index (within the partition) and an iterator that goes through all items within the partition. The partition index is the partition number in your RDD, which identifies where each record in our dataset sits (and potentially allows you to debug). You might use this to test whether your map functions are behaving correctly:
def indexedFunc(partitionIndex:Int, withinPartIterator: Iterator[String]) = { withinPartIterator.toList.map(
value => s"Partition: $partitionIndex => $value").iterator
}
indexedFunc: (partitionIndex: Int, withinPartIterator: Iterator[String])Iterator[String]
words.mapPartitionsWithIndex(indexedFunc).collect() // let's call our indexed function
res9: Array[String] = Array(Partition: 0 => Spark, Partition: 0 => The, Partition: 0 => Definitive, Partition: 0 => Guide, Partition: 0 => :, Partition: 1 => Big, Partition: 1 => Data, Partition: 1 => Processing, Partition: 1 => Made, Partition: 1 => Simple)
foreachPartition
Although
mapPartitionsneeds a return value to work properly, this next function does not.foreachPartitionsimply iterates over all the partitions of the data. The difference is that the function has no return value. This makes it great for doing something with each partition like writing it out to a database. In fact, this is how many data source connectors are written. You can create
your
own text file source if you want by specifying outputs to the temp directory with a random ID:
words.foreachPartition { iter =>
import java.io._
import scala.util.Random
val randomFileName = new Random().nextInt()
val pw = new PrintWriter(new File(s"/tmp/random-file-${randomFileName}.txt"))
while (iter.hasNext) {
pw.write(iter.next())
}
pw.close()
}
You’ll find these two files if you scan your /tmp directory.
You need to scan for the file across all the nodes. As the file may not be in the Driver node's /tmp/ directory but in those of the executors that hosted the partition.
pwd
Editors
Here is a list of the editors who have helped improve this book