mapPartitionsWithIndex
Return a new RDD by applying a function to each partition of this RDD, while tracking the index of the original partition.
Let us look at the legend and overview of the visual RDD Api.
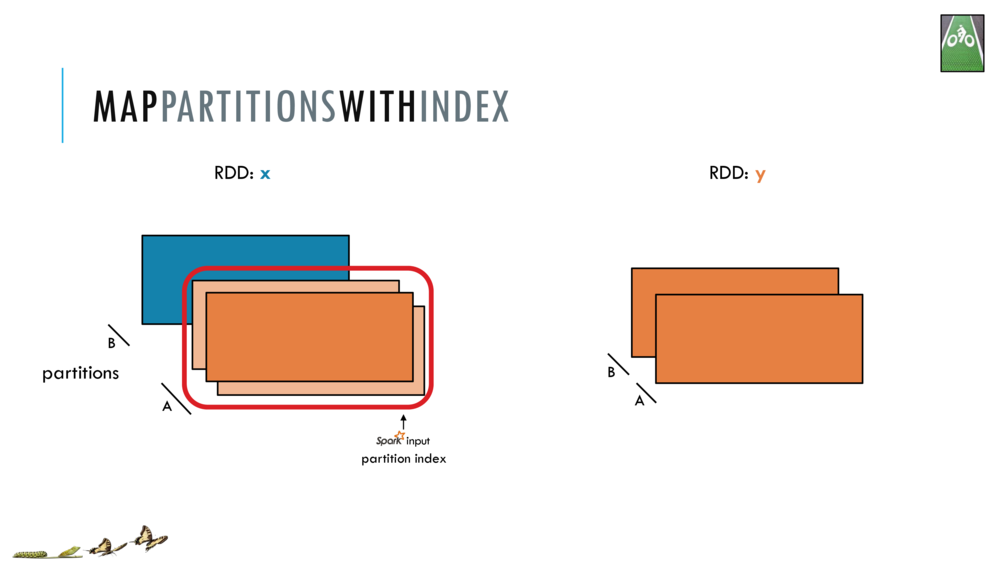

val x = sc. parallelize(Array(1,2,3), 2) // make an RDD with 2 partitions
x: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[289] at parallelize at <console>:34
def f(partitionIndex:Int, i:Iterator[Int]) = {
(partitionIndex, i.sum).productIterator
}
f: (partitionIndex: Int, i: Iterator[Int])Iterator[Any]
val y = x.mapPartitionsWithIndex(f)
y: org.apache.spark.rdd.RDD[Any] = MapPartitionsRDD[304] at mapPartitionsWithIndex at <console>:38
//glom() flattens elements on the same partition
val xout = x.glom().collect()
xout: Array[Array[Int]] = Array(Array(1), Array(2, 3))
val yout = y.glom().collect()
yout: Array[Array[Any]] = Array(Array(0, 1), Array(1, 5))