Overview of a 360-in-525 Minutes Course Set in Data Sciences, Spring 2018
For PhD Students at Uppsala University and Researchers who want to upskill for Data Industry
There will be several full-day workshop-style courses (360 minutes-long, with the usual three 15-minutes-long breaks before and after the 75-minutes-long lunch break in the 525 minutes from 0815 to 1700 hours CET) worth 1hp to 3hp credits each. This is partly supported by the Centre for Interdisciplinary Mathematics jointly with the Department of Mathematics in Spring 2018 and taught by domain experts in Digital Sociology, Geospatial Analytics, Population Genetics and Mathematical Statistics.
Master students at Uppsala University must contact their study councellor in order to see if it is possible to take the course as a “Selected Topics Course” in their Department.
If you are working in industry and want to upskill in data science then you can take the courses (free of cost) and receive a certificate from the Department of Mathematics upon successful completion.
This course set is coordinated by Dr. Raazesh Sainudiin, a Researcher in Applied Mathematics and Statistics at the Department of Mathematics, Uppsala University and a Data Science Consultant at Combient AB in Stockholm.
If you are a PhD or MSc student at Uppsala University or a researcher who wants to upskill for the data industry and interested in registering for appropriate subsets of the course set then please email details/questions/etc to the course set coordinator with subject line 360-in-525.
Feel free to take any subset of modules if you can satisfy the prerequisite modules. Physical presence is mandatory for the credits in all of these modules.
POA
See our Plan of Action (POA) for the course set including timings and order of topics as they fall in place.
What is expected in a 1hp Course at Uppsala University?
Learning concepts in depth and familiarizing one self with new syntax requires completion of watching/reading assignments and completion of homework exercises. At Uppsala University, 1hp is about 25 hours of work and there is plenty of time, outside the 6-8 hours of face-to-face lab/lecture meetings, for deepening one’s understanding.
360-in-525-1: Introduction to Apache Spark for Data Scientists
This is a one-full-day workshop (1 hp) on April 20 2018 on Apache Spark, one of the most widely used open-source and commercially friendly software for analysing big data in industry and academia. A crash course in Scala, the language of Apache Spark, will be followed by introduction to resilient distributed datasets (RDDs), their transformations and actions, Spark DataSets and DataFrames, SparkSQL. We will have brief teasers on ML Pipelines, Streaming and GraphX as they will be covered in-depth in the sequel modules.
360-in-525-2: Social Media and Big Data
This is a two-full-days workshop (2 hp) on April 26-27 2018. Prerequisites: 360-in-525-1 or Introduction to data Science (the Fall 2017 UU inter-faculty course). The first day will be an introduction to the domain by Professor Simon Lindgren, a digital sociologist from Umea and the second day will build towards making one’s own twitter experimental designs in real-time.
This module will introduce you to topic modeling and other simple pipelines in natural language processing.
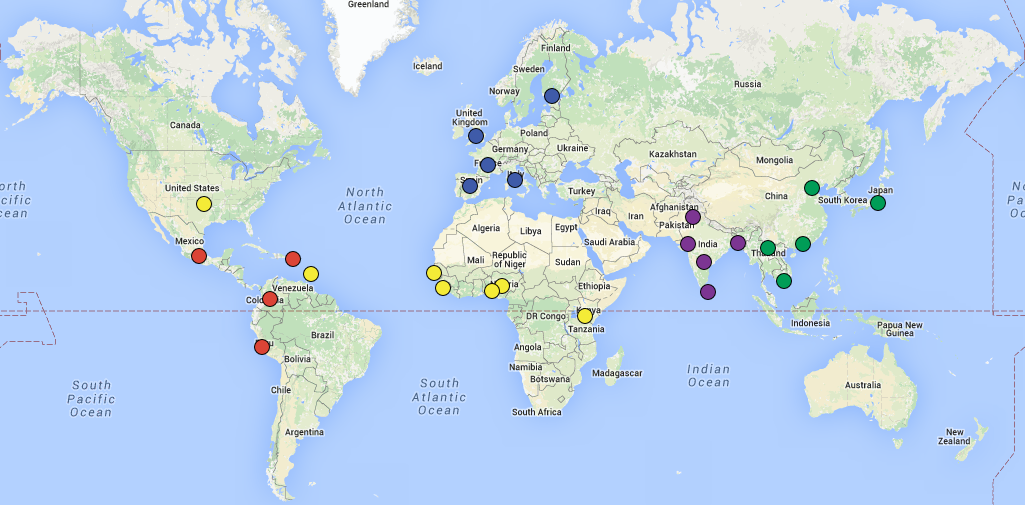
The course will give you the basic skills needed to go further and investigate the influence, if any, of micro propaganda machines (as shown below) or other similar opinion engineering operations, for instance.
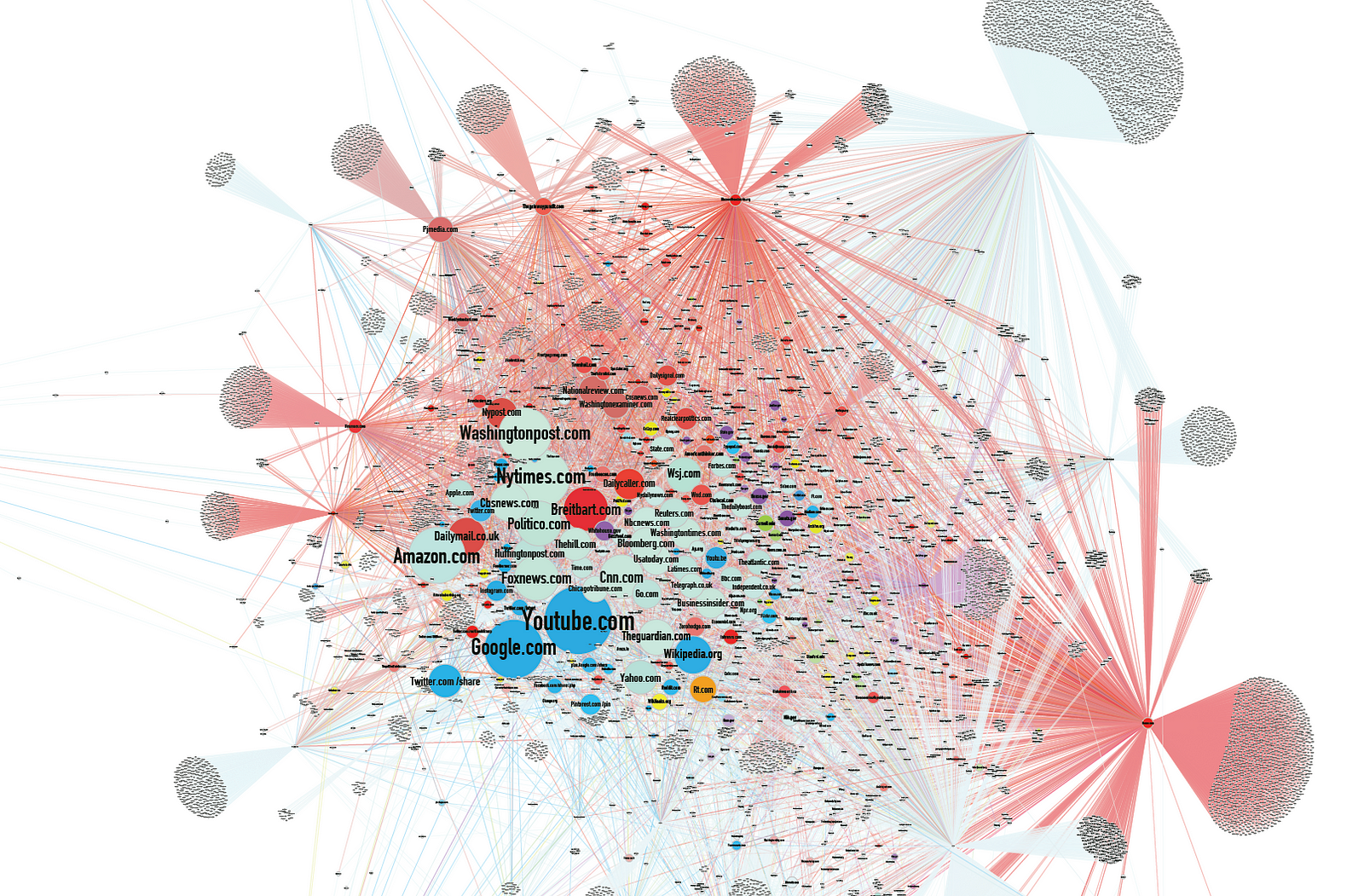
We will ingest global news streams from the gdelt project with embeddings and models to gain insights into current affairs (see below).
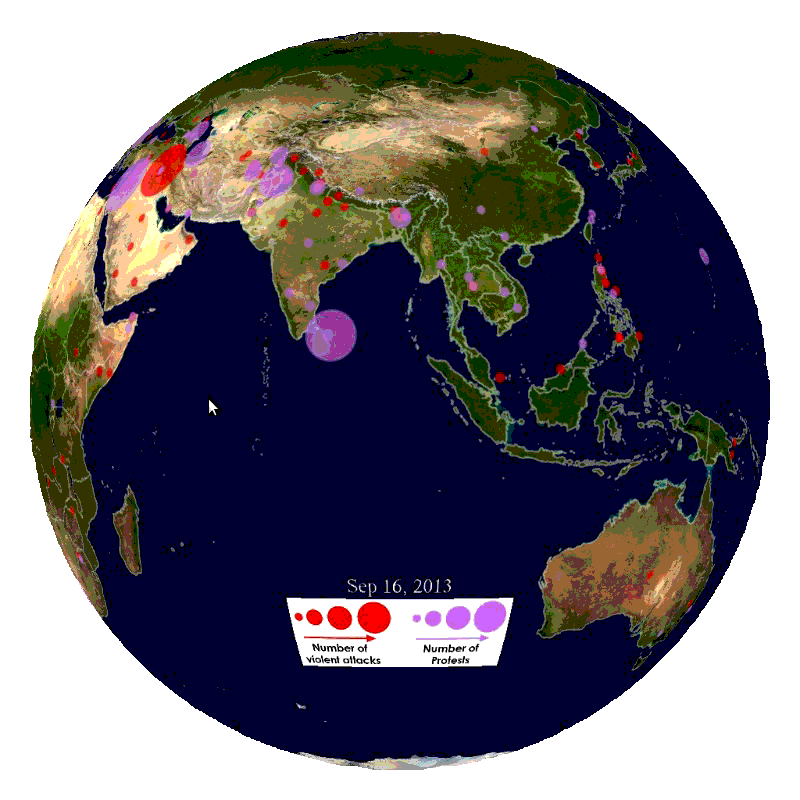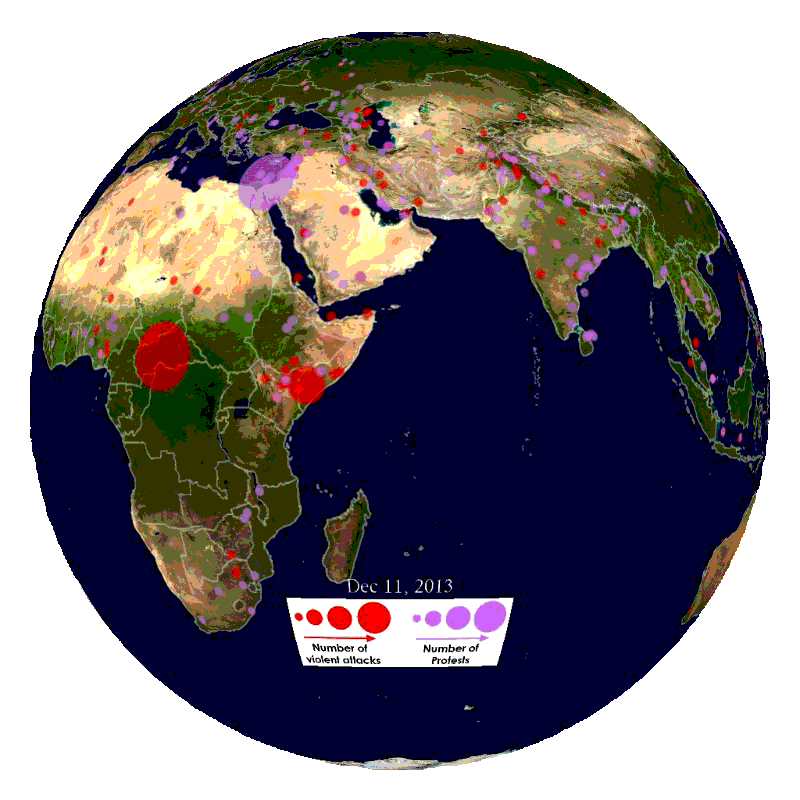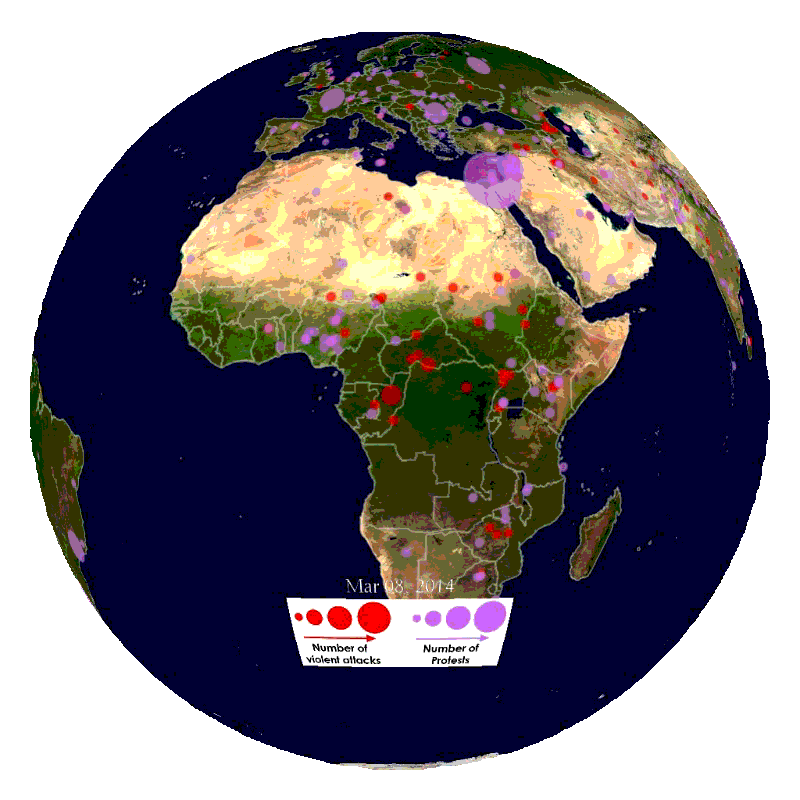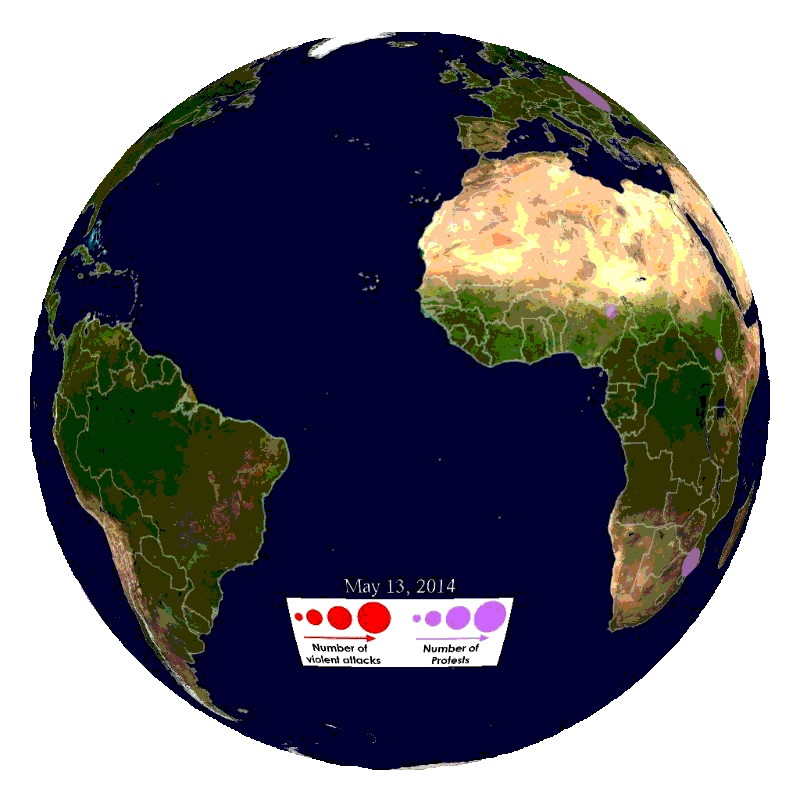
360-in-525-3: Geospatial Analytics and Big Data
This is a two-full-days workshop (2 hp) on May 3-4 2018. Prerequisites: 360-in-525-1 or Introduction to data Science. The first day will be done by domain experts from Uppsala University’s Department of Social and Economic Geography in order to introduce the basic problems and datasets of the field with hands-on lab tutorials in non-distributed geospatial analytics. The second day will be on distributed geospatial analytics over real datasets that can be scaled to petabytes (syllabus is jointly designed with experts in London’s big data industry). Topics include efficient distributed spatial joins, ingestion and representations of Open Street Maps that are conducive to pregel-style distributed vertex programs, SparkSQL and Spark Machine Learning pipelines with spatiotemporal GPS trajectories of multiple individuals.
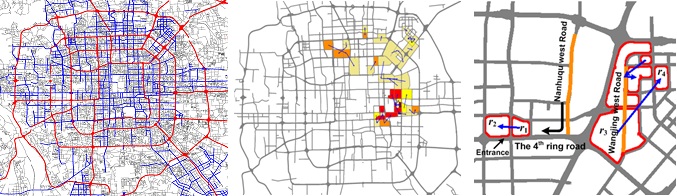
360-in-525-1,2,3 should prepare you for Microsoft Research’s urban computing and cross-domain data fusion
360-in-525-4: Mathematical, Statistical and Computational Foundations for Data Scientists
Three-full-day workshops (3 hp) on May 11, 18 and 25 2018. Prerequisites: current proficiency in high-school level mathematics (pre-calculus, geometry and algebra with some programming experience beyond Excel). Target Audience: any MSc or PhD student at UU who wants to understand the mathematical statistical foundations in the data scientist’s computational toolbox. The approach will use formal mathematical communication of concepts starting from sets and logic, but with concomitant development of computer programming skills to algorithmically construct and implement the concepts. Topics will include: Sets, Maps, Functions, Modular Arithmetic, Axiomatic Probability, Conditional probability, Pseudo-random constructive understanding of random variables and structures including graphs, Statistics, Likelihood Principle, Bayes Rule, Decisions (parametric and non-parametric) including tests and estimators, Markov chains and their pseudorandom constructions, etc. We will use SageMath locally and collaborate in COCALC during the lab/lectures (alternative options including Apache Zeppelin are being investigated to keep the local computing environment identical across the course set).
360-in-525-5: Population Genetics and Big Data
One-full-day workshops (1 hp) on May 31 2018. The first half will be on the basic theories in current population genetics and genomics. The second half will use ADAM and possibly Hail over Apache Spark. Prerequisites are 360-in-525-4 or equivalent and 360-in-525-1 or Introduction to data Science. We will focus on Extract-Load-Transform operations and subsequent analysis for the 1000 genomes project. It is possible to get 2hp by doing a supervised project.
360-in-525-0: Mathematical Statistical Learning Theory Series; An L1 View
Meeting time for this 1-day-workshop is on June 1 2018.
This course will introduce a PhD student in mathematics or mathematical statistics to one of the fundamental problems at the very core of various probabilistic theories of decision-making.
We will mainly focus on the relation between the combinatorial geometric complexity of the (sigma) algebras of a simple measurable space and the rates of convergence of empirical measures over them in one of the simplest posable decision problems – nonparametric density estimation of an unknown density f in L1 based on finitely many observations drawn independently from it, but without making any mathematical compromise whatsoever, and thereby giving the so-called universal performance guarantee .
This course was given in another form at CMAP, Ecole Polytechnique, Palaiseau, France for PhD students in mathematics there. Students in Geometry and Combinatorial probability as well as analysis may find this course insightful for their own research, as one of the basic theorems involves the combined use of several unique inequalities in a specific partial order of implications.
The emphasis will involve constructive mathematics and perhaps delve into tree arithmetics towards such decision with universal performance guarantees along with their combinatorial, algebraic and analytic properties if time permits. Unfortunately such guarantees are not available for big data sets and may be necessary for being able to impose legal requirements and standards on automated decision-making systems.
LOGISTICS
- There is no teaching assistants to help you in-place so please be patient.
- For all courses except 360-in-525-0, you are expected to bring a laptop that is not older than 3 years (in general) with wireless access (with at least 10 GB of free disk space, at least 4 GB of RAM with chrome or firefox browser; those of you who do not have UU wireless or eduroam will be given guest wifi identities).
- Please join Uppsala Big Data Meetup to receive communications on course logistics and partake in discussions.
- Sign-up for the free databricks community edition: https://community.cloud.databricks.com/login.html, our primary learning environment in the cloud.
- If you RSVP at the meetup page for the courses at least 3 days before the meeting then your morning and afternoon fika between the two 90-minutes-long sessions would have been ordered.
SUPPORT
This Uppsala Big Data Meetup totaling over 3600 minutes (especially for those from industry) is funded by:
- Department of Mathematics with partial support from Centre for Interdisciplinary Mathematics, Uppsala University,
- supported by databricks academic partnership and AWS Educate grant to uppsala University, and
- fika is generously sponsored by Combinet (https://combient.com/) for first 9 days and by SEB (https://seb.se/) for the last day.