// Databricks notebook source exported at Sat, 25 Jun 2016 00:25:30 UTC
Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by  and
and

The html source url of this databricks notebook and its recorded Uji  :
:
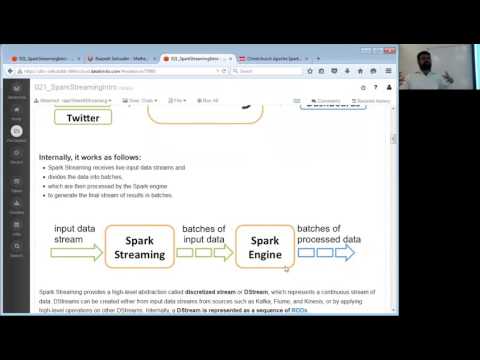
Twitter Hashtag Count
Using Twitter Streaming is a great way to learn Spark Streaming if you don’t have your streaming datasource and want a great rich input dataset to try Spark Streaming transformations on.
In this example, we show how to calculate the top hashtags seen in the last X window of time every Y time unit.
Extracting knowledge from tweets is “easy” using techniques shown here, but one has to take responsibility for the use of this knowledge and conform to the rules and policies linked below.
Remeber that the use of twitter itself comes with various strings attached. Read:
Crucially, the use of the content from twitter by you (as done in this worksheet) comes with some strings. Read:
import org.apache.spark._
import org.apache.spark.storage._
import org.apache.spark.streaming._
import org.apache.spark.streaming.twitter.TwitterUtils
import scala.math.Ordering
import twitter4j.auth.OAuthAuthorization
import twitter4j.conf.ConfigurationBuilder
Step 1: Enter your Twitter API Credentials.
- Go to https://apps.twitter.com and look up your Twitter API Credentials, or create an app to create them.
- Run this cell for the input cells to appear.
- Enter your credentials.
- Run the cell again to pick up your defaults.
The cell-below is hidden to not expose the Twitter API Credentials: consumerKey, consumerSecret, accessToken and accessTokenSecret.
System.setProperty("twitter4j.oauth.consumerKey", getArgument("1. Consumer Key (API Key)", ""))
System.setProperty("twitter4j.oauth.consumerSecret", getArgument("2. Consumer Secret (API Secret)", ""))
System.setProperty("twitter4j.oauth.accessToken", getArgument("3. Access Token", ""))
System.setProperty("twitter4j.oauth.accessTokenSecret", getArgument("4. Access Token Secret", ""))
If you see warnings then ignore for now: https://forums.databricks.com/questions/6941/change-in-getargument-for-notebook-input.html.
Step 2: Configure where to output the top hashtags and how often to compute them.
- Run this cell for the input cells to appear.
- Enter your credentials.
- Run the cell again to pick up your defaults.
val outputDirectory = getArgument("1. Output Directory", "/twitter")
val slideInterval = new Duration(getArgument("2. Recompute the top hashtags every N seconds", "1").toInt * 1000)
val windowLength = new Duration(getArgument("3. Compute the top hashtags for the last N seconds", "5").toInt * 1000)
val timeoutJobLength = getArgument("4. Wait this many seconds before stopping the streaming job", "100").toInt * 1000
Step 3: Run the Twitter Streaming job.
Clean up any old files.
dbutils.fs.rm(outputDirectory, true)
Create the function to that creates the Streaming Context and sets up the streaming job.
var newContextCreated = false
var num = 0
// This is a helper class used for
object SecondValueOrdering extends Ordering[(String, Int)] {
def compare(a: (String, Int), b: (String, Int)) = {
a._2 compare b._2
}
}
// This is the function that creates the SteamingContext and sets up the Spark Streaming job.
def creatingFunc(): StreamingContext = {
// Create a Spark Streaming Context.
val ssc = new StreamingContext(sc, slideInterval)
// Create a Twitter Stream for the input source.
val auth = Some(new OAuthAuthorization(new ConfigurationBuilder().build()))
val twitterStream = TwitterUtils.createStream(ssc, auth)
// Parse the tweets and gather the hashTags.
val hashTagStream = twitterStream.map(_.getText).flatMap(_.split(" ")).filter(_.startsWith("#"))
// Compute the counts of each hashtag by window.
// reduceByKey on a window of length windowLength
// Once this is computed, slide the window by slideInterval and calculate reduceByKey again for the second window
val windowedhashTagCountStream = hashTagStream.map((_, 1)).reduceByKeyAndWindow((x: Int, y: Int) => x + y, windowLength, slideInterval)
// For each window, calculate the top hashtags for that time period.
windowedhashTagCountStream.foreachRDD(hashTagCountRDD => {
val topEndpoints = hashTagCountRDD.top(10)(SecondValueOrdering)
dbutils.fs.put(s"${outputDirectory}/top_hashtags_${num}", topEndpoints.mkString("\n"), true)
println(s"------ TOP HASHTAGS For window ${num}")
println(topEndpoints.mkString("\n"))
num = num + 1
})
newContextCreated = true
ssc
}
Create the StreamingContext using getActiveOrCreate, as required when starting a streaming job in Databricks.
val ssc = StreamingContext.getActiveOrCreate(creatingFunc)
Start the Spark Streaming Context and return when the Streaming job exits or return with the specified timeout.
ssc.start()
ssc.awaitTerminationOrTimeout(timeoutJobLength)
ssc.stop(stopSparkContext = false)
Check out the Clusters ‘Streaming` UI as the job is running.
It should automatically stop the streaming job after timeoutJobLength.
If not, then stop any active Streaming Contexts, but don’t stop the spark contexts they are attached to using the following command.
StreamingContext.getActive.foreach { _.stop(stopSparkContext = false) }
Step 4: View the Results.
display(dbutils.fs.ls(outputDirectory))
There should be 100 intervals for each second and the top hashtage for each of them should be in the file top_hashtags_N for N in 0,1,2,…,99 and the top hashtags should be based on the past 5 seconds window.
dbutils.fs.head(s"${outputDirectory}/top_hashtags_11")
Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by
and