Why Apache Spark?
- Apache Spark: A Unified Engine for Big Data Processing By Matei Zaharia, Reynold S. Xin, Patrick Wendell, Tathagata Das, Michael Armbrust, Ankur Dave, Xiangrui Meng, Josh Rosen, Shivaram Venkataraman, Michael J. Franklin, Ali Ghodsi, Joseph Gonzalez, Scott Shenker, Ion Stoica Communications of the ACM, Vol. 59 No. 11, Pages 56-65 10.1145/2934664

Right-click the above image-link, open in a new tab and watch the video (4 minutes) or read about it in the Communications of the ACM in the frame below or from the link above.
**Key Insights from Apache Spark: A Unified Engine for Big Data Processing **
- A simple programming model can capture streaming, batch, and interactive workloads and enable new applications that combine them.
- Apache Spark applications range from finance to scientific data processing and combine libraries for SQL, machine learning, and graphs.
- In six years, Apache Spark has grown to 1,000 contributors and thousands of deployments.

Spark 3.0 is the latest version now (20200918) and it should be seen as the latest step in the evolution of tools in the big data ecosystem as summarized in https://towardsdatascience.com/what-is-big-data-understanding-the-history-32078f3b53ce:
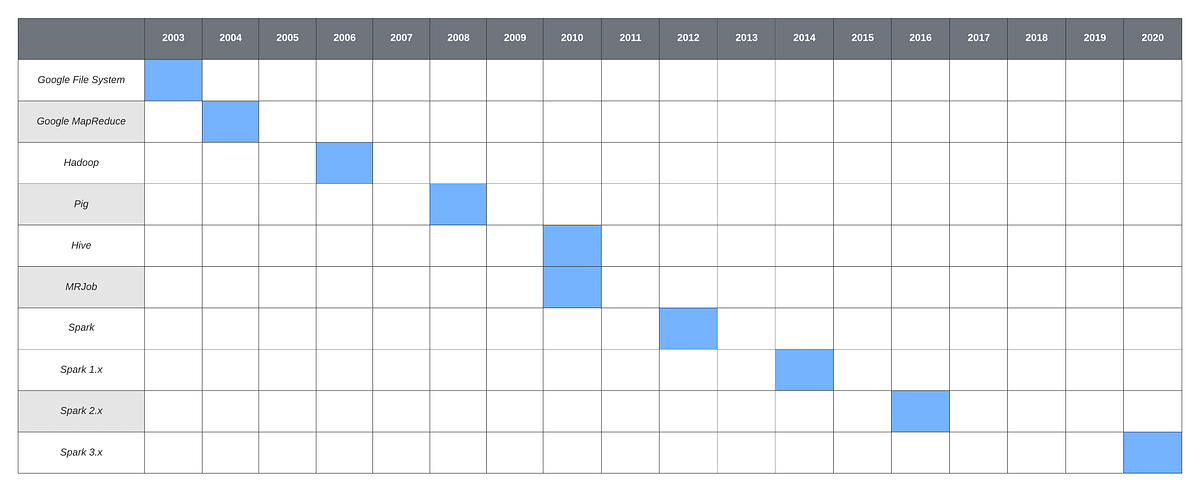
Alternatives to Apache Spark
There are several alternatives to Apache Spark, but none of them have the penetration and community of Spark as of 2021.
For real-time streaming operations Apache Flink is competitive. See Apache Flink vs Spark – Will one overtake the other? for a July 2021 comparison. Most scalable data science and engineering problems faced by several major industries in Sweden today are routinely solved using tools in the ecosystem around Apache Spark. Therefore, we will focus on Apache Spark here which still holds the world record for 10TB or 10,000 GB sort by Alibaba cloud in 06/17/2020.
The big data problem
Hardware, distributing work, handling failed and slow machines
Let us recall and appreciate the following:
- The Big Data Problem
- Many routine problems today involve dealing with "big data", operationally, this is a dataset that is larger than a few TBs and thus won't fit into a single commodity computer like a powerful desktop or laptop computer.
- Hardware for Big Data
- The best single commodity computer can not handle big data as it has limited hard-disk and memory
- Thus, we need to break the data up into lots of commodity computers that are networked together via cables to communicate instructions and data between them - this can be thought of as a cloud
- How to distribute work across a cluster of commodity machines?
- We need a software-level framework for this.
- How to deal with failures or slow machines?
- We also need a software-level framework for this.
Key Papers
-
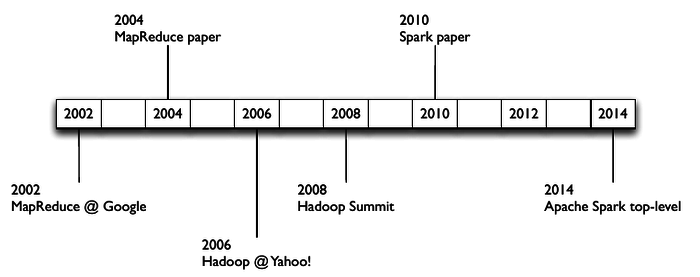
Key Historical Milestones
- 1956-1979: Stanford, MIT, CMU, and other universities develop set/list operations in LISP, Prolog, and other languages for parallel processing
- 2004: READ: Google's MapReduce: Simplified Data Processing on Large Clusters, by Jeffrey Dean and Sanjay Ghemawat
- 2006: Yahoo!'s Apache Hadoop, originating from the Yahoo!’s Nutch Project, Doug Cutting - wikipedia
- 2009: Cloud computing with Amazon Web Services Elastic MapReduce, a Hadoop version modified for Amazon Elastic Cloud Computing (EC2) and Amazon Simple Storage System (S3), including support for Apache Hive and Pig.
- 2010: READ: The Hadoop Distributed File System, by Konstantin Shvachko, Hairong Kuang, Sanjay Radia, and Robert Chansler. IEEE MSST
-
Apache Spark Core Papers
- 2012: READ: Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing, Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker and Ion Stoica. NSDI
- 2016: Apache Spark: A Unified Engine for Big Data Processing By Matei Zaharia, Reynold S. Xin, Patrick Wendell, Tathagata Das, Michael Armbrust, Ankur Dave, Xiangrui Meng, Josh Rosen, Shivaram Venkataraman, Michael J. Franklin, Ali Ghodsi, Joseph Gonzalez, Scott Shenker, Ion Stoica , Communications of the ACM, Vol. 59 No. 11, Pages 56-65, 10.1145/2934664
-
A lot has happened since 2014 to improve efficiency of Spark and embed more into the big data ecosystem
-
More research papers on Spark are available from here:
MapReduce and Apache Spark.
MapReduce as we will see shortly in action is a framework for distributed fault-tolerant computing over a fault-tolerant distributed file-system, such as Google File System or open-source Hadoop for storage.
- Unfortunately, Map Reduce is bounded by Disk I/O and can be slow
- especially when doing a sequence of MapReduce operations requirinr multiple Disk I/O operations
- Apache Spark can use Memory instead of Disk to speed-up MapReduce Operations
- Spark Versus MapReduce - the speed-up is orders of magnitude faster
- SUMMARY
- Spark uses memory instead of disk alone and is thus fater than Hadoop MapReduce
- Spark's resilience abstraction is by RDD (resilient distributed dataset)
- RDDs can be recovered upon failures from their lineage graphs, the recipes to make them starting from raw data
- Spark supports a lot more than MapReduce, including streaming, interactive in-memory querying, etc.
- Spark demonstrated an unprecedented sort of 1 petabyte (1,000 terabytes) worth of data in 234 minutes running on 190 Amazon EC2 instances (in 2015).
- Spark expertise corresponds to the highest Median Salary in the US (~ 150K)
Next let us get everyone to login to databricks (or another Spark platform) to get our hands dirty with some Spark code!