Login to databricks
We will use databricks community edition and later on the databricks project shard granted for this course under the databricks university alliance with cloud computing grants from databricks for waived DBU units and AWS.
Please go here for a relaxed and detailed-enough tour (later):
databricks community edition
- First obtain a free Obtain a databricks community edition account at:
- Let's get an overview of the databricks managed cloud for processing big data with Apache Spark

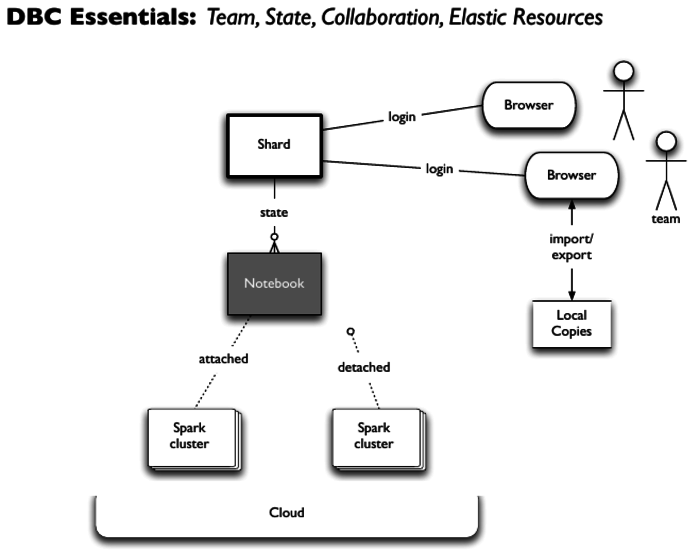
DBC Essentials: Team, State, Collaboration, Elastic Resources in one picture
You Should All Have databricks community edition account by now! and have successfully logged in to it.
Import Course Content Now!
Two Steps:
- Create a folder named
scalable-data-sciencein yourWorkspace(NO Typos due to hard-coding of paths in the sequel!)
- Import the following
.dbcarchives from the following URL intoWorkspace/scalable-data-sciencefolder you just created:- https://github.com/lamastex/scalable-data-science/raw/master/dbcArchives/2021/
- start with the first file for now and import more as needed:
Cloud-free Computing Environment
(Optional but strongly recommended)
Before we dive into Scala crash course in a notebook, let's take a look at TASK 2 of the first step in the instructions to set up a local and "cloud-free" computing environment, say on your laptop computer here:
This can be handy for prototyping quickly and may even be necessary due to sensitivity of data in certain projects that mandate the data to be confined to some on-premise cluster, etc.
NOTE: This can be done as an optional exercise as it heavily depends on your local computing environment and your software skills or willingness to acquire them.
CAVEAT: The docker-compose prepared for your local environment uses Spark 2.x instead of 3.x, but most of the contents here would run in either version of Spark. - Feel free to make PR with latest versions of Spark :)