Distributed Ensembles for 3D Human Pose Estimation
Project members:
- Hampus Gummesson Svensson, Chalmers University of Technology
- Xixi Liu, Chalmers University of Technology
- Yaroslava Lochman, Chalmers University of Technology
- Erik Wallin, Chalmers University of Technology
Introduction
Our task is to perform 3D human pose estimation in video, where the objective is to predict 3D positions of keypoints from 2D positions in video sequences. Specifically, temporal information including 27 frames is used to make predicitons. To acquire more accurate predicitons, we employ a distributed ensembles of temporal convolutional networks. The temporal convolutional network developed by Pavllo, Dario, et al. [2] is employed. This is done in a setting where both labelled and unlabelled data is available.
Distributed Ensembled Models
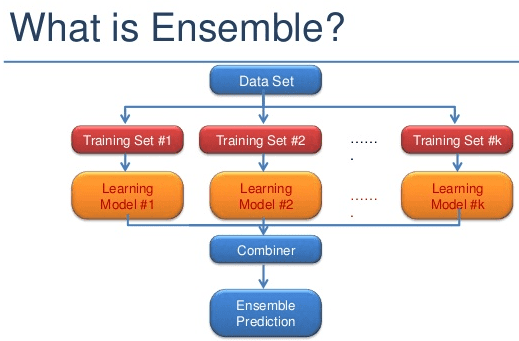
Ensembled models refer to training several models independently. During inference, predictions from each model (also called memeber) are aggregated to make the final pediction. They are often used to estimate uncertainty in deep neural networks [1]. In particular, it is used for the estimation of predictive uncertainty including model and data uncertainty. Model uncertainty occurs due to the non-optimal training procedure or insufficient model structure and is reducible. Data uncertainty happens due to the variablity of the real world or the inherent error in measurement systems. It is irreducible. Moreover, ensembled models are also competitive to improve the test accuracy. In this project, we conduct a distributed version of ensembled models to decrease the test error.
In general, there are two types of distributed training including data parallelism and model parallelism.
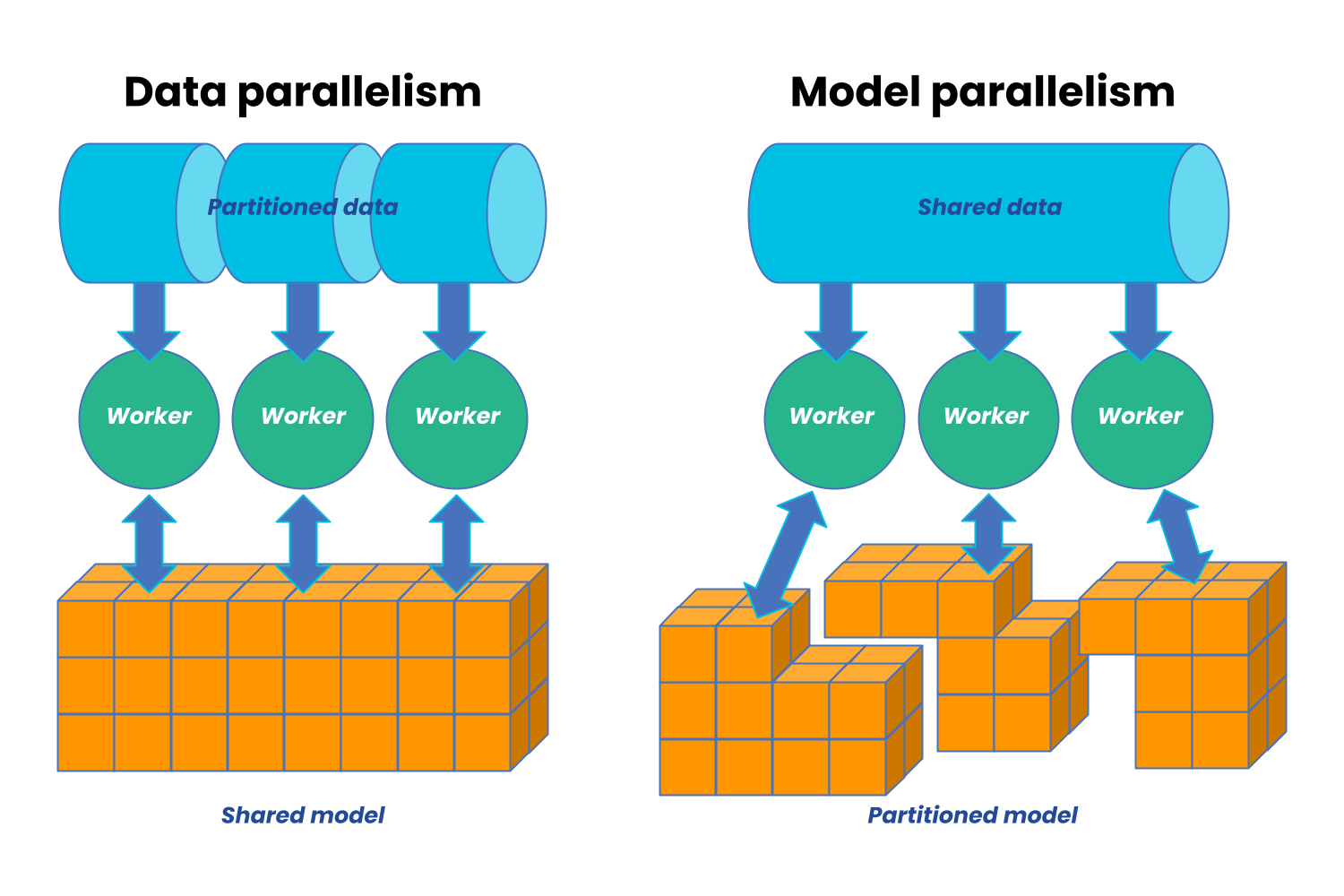
In our project, we utilize both data parallesim and model parallelism. Teachnically, each memeber/model is distributed and further trained on different worker nodes. Because we use the mean of predicitons of each member, the same test dataset is sent to each worker node and make infererence after training. Furthermore, under the assumption that a huge dataset is availble, the whole training dataset is stored in dirver node and each memeber has access to a subset of traning dataset. Specifically, a constant size of susbset training data is pre-dedefined depending on the the memory space of worker node.
Semi-supervised learning
Anotating data is not only costly but time-consumping, implying that the amount of labeled data is limited in many practical applications. Given a dataset consisting of both unlabeled and labeled instances, semi-supervised learning aims to use both the labeled data and unlabeled data to improve the model performance, compared to just using labeled instances. Specifically, the models is first trained by labebled data. Then the trained model is further utilized to predict pseudo-labels for the unlabeled data, which is incoporated into the training data for further training.
Semi-supervised learning with pseudolabels using an ensemble
One way to obtain pseudo-labels in semi-supervised learning is to use the prediction from an ensemble of supervised models. Specifically, each model is trained independetly on all or a part of the available labeled data. After training, each model makes predictions for the unlabeled instances. The predictions on each instance is then aggregated to provide so called pseudolabels that can be used for supervised training, either training a single model or again an ensemble of models to predict labels of unseen data. There are several ways to aggragate the predictions from each model. We use the mean of predictions from each model as the pseudo-label.
3D Human Pose Estimation
3D human pose estimation involves predicting 3D locations of keypoints,e.g., head, hands and elbows, given 2D locations of these keypoints. 2D locations can be given by a video sequence, while the 3D locations are often provided by a motion capture system. For instance, in the sequence below, we see 2D locations of keypoints to the left and the 3D pose to the right. Provided the 2D locations of keypoints to the left, the task is to predict the true 3D locations to the right, which then can provide the full 3D pose (as seen to the right). 
Summary
In this work, * we train a distributed ensemble for 3D human pose estimation in video, where the training data is split up into labeled and unlabeled data. The distributed ensemble is to compute pseudovalues of unlabeled data. We aggregate the prediction of each ensmeble to one single value, that is used for training on labeled and unlabeled data. We incrementally increase the amount of unlabeled data with pseudovalues that is used for training. We use the HumanEva-I dataset [3] for training and evaluation. The mean of predictions from each memeber is taken as the final prediciton. * Further, we conduct experiments and analyze
- how the performance of the distributed ensembled models varies with different number of members in terms of test error;
- how the performance of distributed ensembled mdoel varies while incorportaing the unlabelled data during the training stage.
Licensing
Parts of this code are taken from VideoPose3D repository.
Copyright (c) 2018-present, Facebook, Inc.
All rights reserved.
This source code is licensed under the license found in the
LICENSE file in the root directory of this source tree.
References
[1] Lakshminarayanan, Balaji, et al. " Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles." Neural Information Processing Systems. 2017.
[2] Pavllo, Dario, et al. "3d human pose estimation in video with temporal convolutions and semi-supervised training." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
[3] Sigal, Leonid, Alexandru O. Balan, and Michael J. Black. "Humaneva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion." International journal of computer vision 87.1 (2010): 4-27.