Introduction to Horovod
Horovod is a distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. Using Horovod allows us to make distributed deep learning fast and easy to use.
The Horovod goal is to make it easy to take a single-GPU training script and successfully scale it to train across many GPUs in parallel.
This pakage has two important aspects to take in to account. Firstly, we can make our projract or program to be runed in distrbuted manner by adding a minimum modification into the code. Secondly, this modifications can aid the program to be runed way faster because of using distributed resouces. Below is a chart representing the benchmark( we borrowed from link here) that was done on 128 servers with 4 Pascal GPUs each connected by RoCE-capable 25 Gbit/s network:

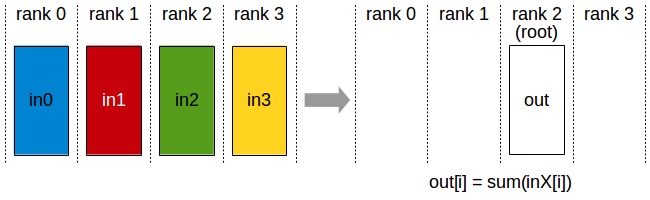
Horovd supports some of the collective operations in both (Message Passing Interface )MPI and (NVIDIA Collective Communications Library)NCCL. Indeed, Horovod core principles are based on MPI concepts such as size, rank, local rank, allreduce, allgather, broadcast, and alltoall. To better understand theses, consider the following example where training script on 4 servers, each having 4 GPUs. If we run one copy of the program per GPU:
-
Size would be the number of processes, in this case, 16.
-
Rank would be the unique process ID from 0 to 15 (size - 1).
-
Local rank would be the unique process ID within the server from 0 to 3.
Then, we have
- Allreduce : aggregates data among multiple processes and distributes results back to them. Allreduce is oftentimes used to average dense tensors.
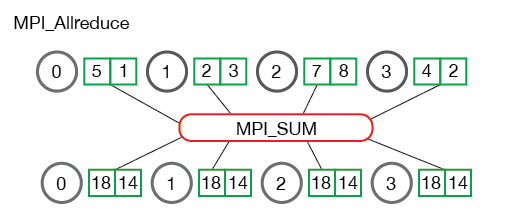
horovod.torch.allreduce(tensor, average=None, name=None, compression=<class 'horovod.torch.compression.NoneCompressor'>, op=None, prescale_factor=1.0, postscale_factor=1.0, process_set=<horovod.common.process_sets.ProcessSet object>)
A function that performs asynchronous in-place averaging or summation of the input tensor over all the Horovod processes.
The reduction operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Horovod processes for a given name. The reduction will not start until all processes are ready to send and receive the tensor.
- Allgather : gathers data from all processes on every process. Allgather is usually used to collect values of sparse tensors.
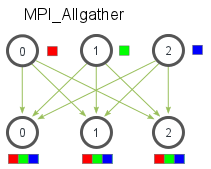
horovod.torch.allgather(tensor, name=None, process_set=<horovod.common.process_sets.ProcessSet object>)
A function that concatenates the input tensor with the same input tensor on all other Horovod processes. The input tensor is not modified.
The concatenation is done on the first dimension, so the corresponding input tensors on the different processes must have the same rank and shape, except for the first dimension, which is allowed to be different.
- Broadcast: broadcasts data from one process, identified by root rank, onto every other process.
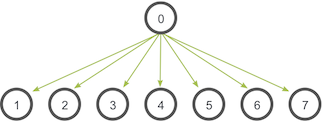
horovod.torch.broadcast(tensor, root_rank, name=None, process_set=<horovod.common.process_sets.ProcessSet object>)
A function that broadcasts the input tensor on root rank to the same input tensor on all other Horovod processes. The input tensor is not modified. The broadcast operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Horovod processes for a given name. The broadcast will not start until all processes are ready to send and receive the tensor.
- Reducescatter: aggregates data among multiple processes and scatters the data across them. Reducescatter is used to average dense tensors then split them across processes.
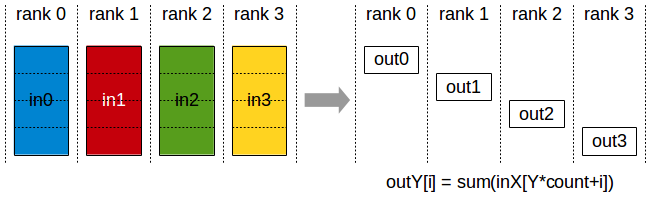
horovod.torch.reducescatter(tensor, name=None, compression=<class 'horovod.torch.compression.NoneCompressor'>, op=<MagicMock name='mock().horovod_reduce_op_average()' id='140066922214416'>, process_set=<horovod.common.process_sets.ProcessSet object>)
A function that performs reduction of the input tensor over all the Horovod processes, then scatters the results across all Horovod processes. The input tensor is not modified.
- Alltoall is an operation to exchange data between all processes. Alltoall may be useful to implement neural networks with advanced architectures that span multiple devices.
horovod.torch.alltoall(tensor, splits=None, name=None, process_set=<horovod.common.process_sets.ProcessSet object>)
A function that scatters slices of the input tensor to all other Horovod processes and returns a tensor of gathered slices from all other Horovod processes. The input tensor is not modified.
Other collective operators
Unfortuntaley, the other existing collective operations are not implemented in Horovod, e.g., Redcue or Ghather which are defined as follows
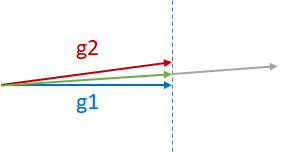
AdaSum The Adaptive Summation, or AdaSum, is an algorithm for improving distributed data parallel training of Deep Learning models. This improvement can be seen in many ways: reducing the number steps to reach the same accuracy and allowing scale to more training workers without penalizing learning rate and convergence stability. AdaSum can be used with Horovod and PyTorch/TensorFlow. To illustrate, suppose there are two almost-parallel gradients from two different GPUs, g1 and g2, and they need to be reduced as shown in the figure below. The two common practices for reductions are g1+g2, the gray vector, or (g1+g2)/2, the green vector. g1+g2 may cause divergence of the model since it is effectively moving in the direction of g1 or g2 by two times the magnitude of g1 or g2. Therefore, generally (g1+g2)/2 is safer and more desired. Note that (g1+g2)/2 penalizes both the components g1 and g2 equally.
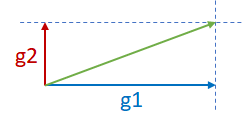
Now consider the two orthogonal gradients g1 and g2 in the figure below. Since g1 and g2 are in two different dimensions and independent of each other, g1+g2 may not cause divergence.
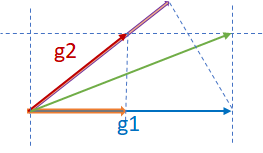
Finally, consider the third scenario where g1 and g2 are neither parallel nor orthogonal as shown in the figure below. In such a case, where taking the sum might cause a divergence, AdaSum controls the effect of the overall gradient update by subtracting half of g1’s projection on g2(pink vector) from g2, subtracting half of g2’s projection on g1 (orange vector) from g1, and summing the two components together.
In a communication system consists nodes having worker GPUs, the communication happens through the CPU because GPUs are not connected by a high speed interconnect like NVLink. In this cases, AdaSum through MPI can be used for both intra-node and inter-node communication.
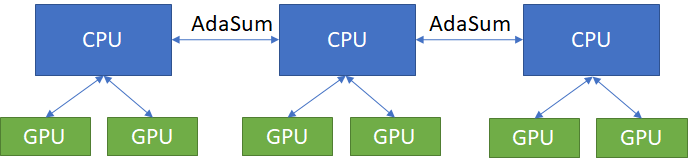
modification in code is as follows:
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum) optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters(), compression=compression, backward_passes_per_step = 5, op=hvd.AdaSum)