Notebook description
Flashback and Familjeliv are two well-known swedish online forums. Flashback is one of Sweden's most visited websites and has discussions on a wide-range of topics. It is famous for emphasizing freedom of speech and the members citizen journalism on many topics. The online forum Familjeliv, on the other hand, focuses more on questions about pregnancy, children and parenthood (the translation is "Family Life"). Part of the forum is also for more general topics, and this part of Familjeliv is probably more famous than its other parts.
What we want to do in this notebook is analyze the language used in these two, quite different, online forums. An interesting approach we will try here is to do some topic modeling with Latent Dirichlet Allocation (LDA). We know that each discussion forum in our data has multiple subforums, so it would be interesting to see if LDA can accurately pick up these different subforums as different topics, or if it sees other patterns in the threads (the threads are what corresponds to documents in the LDA method). We will also mainly do this with forums that have a correspondence in both Flashback and Familjeliv. For instance, both have forums dedicated to questions regarding economy and also forums discussing topics close to sex and relationships.
This notebook is to a large extent adapted from notebook 034LDA20NewsGroupsSmall.
Downloading the data
Data comes from språkbanken, see notebook 00downloaddata.
/scalable-data-science/000_0-sds-3-x-projects/student-project-01_group-TheTwoCultures/00_download_data
// Here we just import methods from notebook 01_load_data, so we can load our data
%run /scalable-data-science/000_0-sds-3-x-projects/student-project-01_group-TheTwoCultures/01_load_data
LDA Methods
Below we put some of the LDA pipeline, working with MLlib, into a single function called get_lda.
import org.apache.spark.ml.feature.{RegexTokenizer, StopWordsRemover, CountVectorizer}
import org.apache.spark.mllib.clustering.{LDA, OnlineLDAOptimizer}
import org.apache.spark.ml.{Pipeline, PipelineModel, PipelineStage}
import org.apache.spark.sql.types.{ LongType }
import org.apache.spark.ml.linalg.Vector
def get_lda(df: org.apache.spark.sql.DataFrame, // Main function to do LDA
min_token: Int,
vocabSize: Int,
minDF: Int,
numTopics: Int,
maxIter: Int,
stopWords: Array[String]) = {
val corpus_df = df.select("w", "thread_id").withColumn("thread_id",col("thread_id").cast(LongType)) // From the whole dataframe we take out each thread
val tokenizer = new RegexTokenizer()
.setPattern("(?U)[\\W_]+") // break by white space character(s) - try to remove emails and other patterns
.setMinTokenLength(min_token) // Filter away tokens with length < min_token
.setInputCol("w") // name of the input column
.setOutputCol("tokens") // name of the output column
val remover = new StopWordsRemover()
.setStopWords(stopWords)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("filtered")
val tokenized_df = tokenizer.transform(corpus_df) // Removes uninteresting words from each thread
val filtered_df = remover.transform(tokenized_df).select("thread_id","filtered") // Chosing only the filtered threads
val vectorizer = new CountVectorizer() // Creates dictionary and counts the occurences of different words
.setInputCol(remover.getOutputCol)
.setOutputCol("features")
.setVocabSize(vocabSize) // Size of dictonary
.setMinDF(minDF)
.fit(filtered_df) // returns CountVectorizerModel
val lda = new LDA() // Creates LDA Model with some user defined choice of parameters
.setOptimizer(new OnlineLDAOptimizer().setMiniBatchFraction(0.8))
.setK(numTopics)
.setMaxIterations(maxIter)
.setDocConcentration(-1) // use default values
.setTopicConcentration(-1)
val countVectors = vectorizer.transform(filtered_df).select("thread_id", "features")
val lda_countVector = countVectors.map { case Row(id: Long, countVector: Vector) => (id, countVector) }
val lda_countVector_mllib = lda_countVector.map { case (id, vector) => (id, org.apache.spark.mllib.linalg.Vectors.fromML(vector)) }.rdd
val lda_model = lda.run(lda_countVector_mllib)
(lda_model, vectorizer)
}
import org.apache.spark.ml.feature.{RegexTokenizer, StopWordsRemover, CountVectorizer}
import org.apache.spark.mllib.clustering.{LDA, OnlineLDAOptimizer}
import org.apache.spark.ml.{Pipeline, PipelineModel, PipelineStage}
import org.apache.spark.sql.types.LongType
import org.apache.spark.ml.linalg.Vector
get_lda: (df: org.apache.spark.sql.DataFrame, min_token: Int, vocabSize: Int, minDF: Int, numTopics: Int, maxIter: Int, stopWords: Array[String])(org.apache.spark.mllib.clustering.LDAModel, org.apache.spark.ml.feature.CountVectorizerModel)
Stopwords
Stop words are highly relevant to get interesting topics distributions, with not all weight on very common words that do not carry much meaning for a particular topic. To do this we both use collections by others and input words we find meaningless for these particular settings.
wget https://raw.githubusercontent.com/peterdalle/svensktext/master/stoppord/stoppord.csv -O /tmp/stopwords.csv
--2021-01-11 14:30:09-- https://raw.githubusercontent.com/peterdalle/svensktext/master/stoppord/stoppord.csv
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.52.133
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.52.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1936 (1.9K) [text/plain]
Saving to: ‘/tmp/stopwords.csv’
0K . 100% 11.5M=0s
2021-01-11 14:30:09 (11.5 MB/s) - ‘/tmp/stopwords.csv’ saved [1936/1936]
cp file:/tmp/stopwords.csv dbfs:/datasets/student-project-01/stopwords.csv
res24: Boolean = true
//Creating a list with stopwords
import org.apache.spark.ml.feature.StopWordsRemover
val stoppord = sc.textFile("dbfs:/datasets/student-project-01/stopwords.csv").collect()
val stopwordList = Array("bara","lite","finns","vill","samt","inga","även","finns","ganska","också","igen","just","that","with","http","jpg","kanske","tycker","gillar", "bra","the","000","måste","tjej","tjejer","tjejen","tjejerna","kvinna","kvinnor","kille","killar","killen","män","rätt","män","com","and","html","många","aldrig","www","mpg","avi","wmv","fan","förhelvetet","riktigt","känner","väldigt","font","size","mms","2008","2009","95kr","dom","får","ska","kommer","två","vet","mer","pengar","pengarna","göra","fick","tror","andra","helt","kunna","behöver","betala","inget","dock","inget","tack"
).union(stoppord).union(StopWordsRemover.loadDefaultStopWords("swedish")) // In this step we add custom stop words and another premade list of stopwords.
Experiments
Below we we chosen some similar forums from FB and FL. First two regarding economics, and two discussing sex and relationships. Here we run the two economics forums and see how well TDA captures any topic structure.
Here one does not have to use similar forums, but if one is interested in only Flashback forums one could use only those. We could also of course join several of these forums together to try to capture even broader topic distributions
// Loading the forums we will do LDA on.
val file_path_FL = "dbfs:/datasets/student-project-01/familjeliv/familjeliv-allmanna-ekonomi_df"
val file_path_FB = "dbfs:/datasets/student-project-01/flashback/flashback-ekonomi_df"
//val file_path_FL = "dbfs:/datasets/student-project-01/familjeliv/familjeliv-sexsamlevnad_df"
//val file_path_FB = "dbfs:/datasets/student-project-01/flashback/flashback-sex_df"
val df_FL = load_df(file_path_FL)
val df_FB = load_df(file_path_FB)
file_path_FL: String = dbfs:/datasets/student-project-01/familjeliv/familjeliv-allmanna-ekonomi_df
file_path_FB: String = dbfs:/datasets/student-project-01/flashback/flashback-ekonomi_df
df_FL: org.apache.spark.sql.DataFrame = [thread_id: string, thread_title: string ... 5 more fields]
df_FB: org.apache.spark.sql.DataFrame = [thread_id: string, thread_title: string ... 5 more fields]
// Dataframes containg a forum from FB.
df_FB.show
// Overview of number of threads in different subforums
df_FL.groupBy($"forum_title").agg(count($"forum_title").as("count")).show(false)
+----------------------------------------------------------+-----+
|forum_title |count|
+----------------------------------------------------------+-----+
|Allmänna rubriker > Ekonomi & juridik > Konsument/Inhandla|26307|
|Allmänna rubriker > Ekonomi & juridik > Familjerätt |1623 |
|Allmänna rubriker > Ekonomi & juridik > Övrigt |1638 |
|Allmänna rubriker > Ekonomi & juridik > Ekonomi |24284|
|Allmänna rubriker > Ekonomi & juridik > Spartips |217 |
|Allmänna rubriker > Ekonomi & juridik > Juridik |3246 |
|Allmänna rubriker > Ekonomi & juridik > Företagande |957 |
|Allmänna rubriker > Ekonomi & juridik > Lån & skulder |1168 |
+----------------------------------------------------------+-----+
df_FB.groupBy($"forum_title").agg(count($"forum_title").as("count")).show(false)
+---------------------------------------------------+-----+
|forum_title |count|
+---------------------------------------------------+-----+
|Ekonomi > Privatekonomi |15154|
|Ekonomi > Bitcoin och andra virtuella valutor |524 |
|Ekonomi > Värdepapper, valutor och råvaror: allmänt|8300 |
|Ekonomi > Fonder |645 |
|Ekonomi > Företagande och företagsekonomi |12139|
|Ekonomi > Nationalekonomi |3114 |
|Ekonomi > Aktier |508 |
|Ekonomi > Ekonomi: övrigt |19308|
|Ekonomi > Offshore och skatteplanering |1567 |
+---------------------------------------------------+-----+
// Set parameters, and perform two different LDAs, one on FB and one on FL
val min_token = 4 // only accept tokens larger or equal to
val vocabSize = 10000 // Size of the vocab dictionary
val minDF = 5 // The minimum number of different documents a term must appear in to be included in the vocabulary
val minTF = 2 // The minimum number of times a term has to appear in a document to be included in the vocabulary
val numTopics_FL = no_forums(df_FL).toInt //4 // Number of topics in LDA model
val numTopics_FB = no_forums(df_FB).toInt
val maxIter = 8 // Maximum number of iterations for LDA model
val stopwords = stopwordList
val (ldaModel_FL, vectorizer_FL) = get_lda(df_FL, min_token, vocabSize, minDF, numTopics_FL, maxIter, stopwords)
val (ldaModel_FB, vectorizer_FB) = get_lda(df_FB, min_token, vocabSize, minDF, numTopics_FB, maxIter, stopwords)
Results
Here we will visualize the most important part of the different topic distributions, both for FB and for FL.
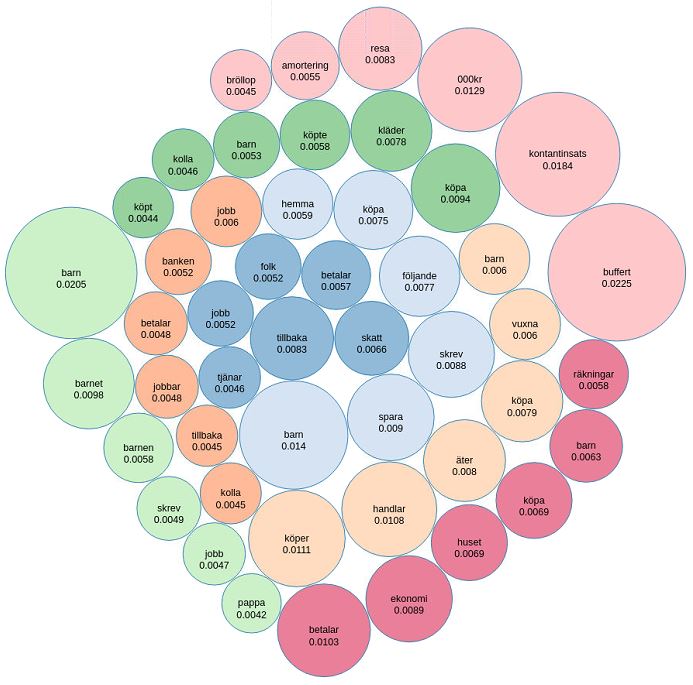
// Here we pick out the most important terms in each topic for FL.
val topicIndices = ldaModel_FL.describeTopics(maxTermsPerTopic = 5)
val vocabList = vectorizer_FL.vocabulary
val topics = topicIndices.map { case (terms, termWeights) =>
terms.map(vocabList(_)).zip(termWeights)
}
println(s"$numTopics_FL topics:")
topics.zipWithIndex.foreach { case (topic, i) =>
println(s"TOPIC $i")
topic.foreach { case (term, weight) => println(s"$term\t$weight") }
println(s"==========")
}
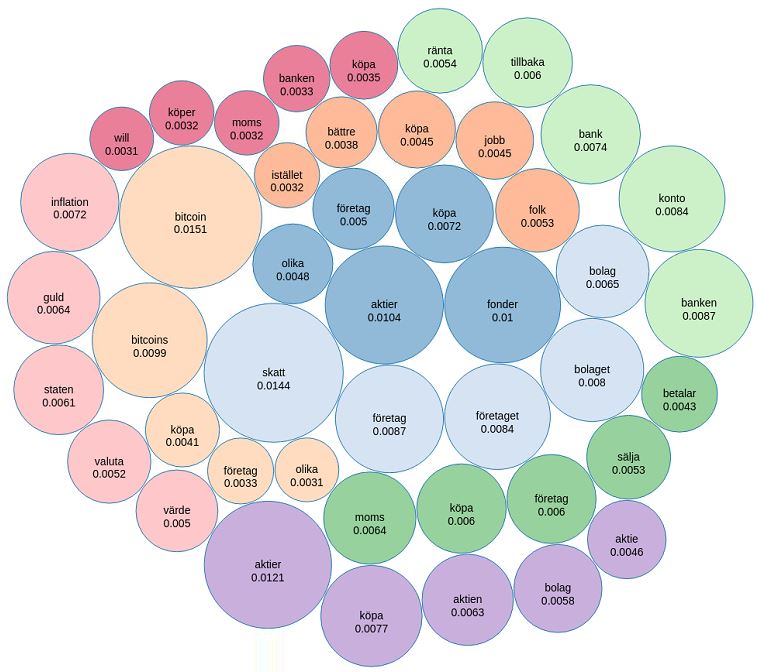
// Here we pick out the most important terms in each topic for FB.
val topicIndices = ldaModel_FB.describeTopics(maxTermsPerTopic = 5)
val vocabList = vectorizer_FB.vocabulary
val topics = topicIndices.map { case (terms, termWeights) =>
terms.map(vocabList(_)).zip(termWeights)
}
println(s"$numTopics_FB topics:")
topics.zipWithIndex.foreach { case (topic, i) =>
println(s"TOPIC $i")
topic.foreach { case (term, weight) => println(s"$term\t$weight") }
println(s"==========")
}
// Zip topic terms with topic IDs
val termArray = topics.zipWithIndex
// Transform data into the form (term, probability, topicId)
val termRDD = sc.parallelize(termArray)
val termRDD2 =termRDD.flatMap( (x: (Array[(String, Double)], Int)) => {
val arrayOfTuple = x._1
val topicId = x._2
arrayOfTuple.map(el => (el._1, el._2, topicId))
})
// Create DF with proper column names
val termDF = termRDD2.toDF.withColumnRenamed("_1", "term").withColumnRenamed("_2", "probability").withColumnRenamed("_3", "topicId")
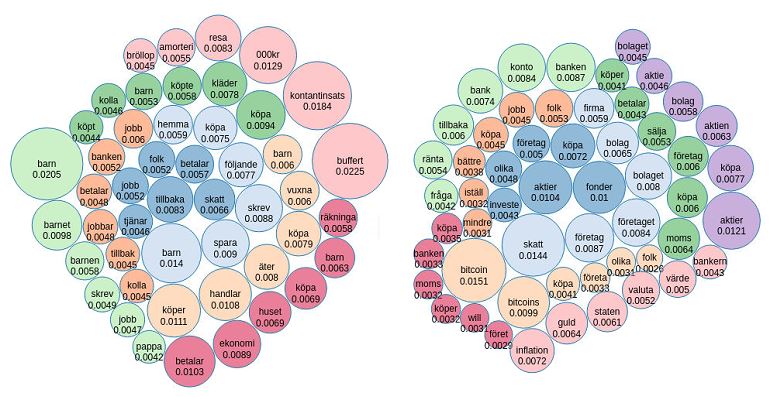
display(termDF)
// Creates JSON data to display topic distribution of forum in FB
val rawJson = termDF.toJSON.collect().mkString(",\n")
displayHTML(s"""
<!DOCTYPE html>
<meta charset="utf-8">
<style>
circle {
fill: rgb(31, 119, 180);
fill-opacity: 0.5;
stroke: rgb(31, 119, 180);
stroke-width: 1px;
}
.leaf circle {
fill: #ff7f0e;
fill-opacity: 1;
}
text {
font: 14px sans-serif;
}
</style>
<body>
<script src="https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.5/d3.min.js"></script>
<script>
var json = {
"name": "data",
"children": [
{
"name": "topics",
"children": [
${rawJson}
]
}
]
};
var r = 1000,
format = d3.format(",d"),
fill = d3.scale.category20c();
var bubble = d3.layout.pack()
.sort(null)
.size([r, r])
.padding(1.5);
var vis = d3.select("body").append("svg")
.attr("width", r)
.attr("height", r)
.attr("class", "bubble");
var node = vis.selectAll("g.node")
.data(bubble.nodes(classes(json))
.filter(function(d) { return !d.children; }))
.enter().append("g")
.attr("class", "node")
.attr("transform", function(d) { return "translate(" + d.x + "," + d.y + ")"; })
color = d3.scale.category20();
node.append("title")
.text(function(d) { return d.className + ": " + format(d.value); });
node.append("circle")
.attr("r", function(d) { return d.r; })
.style("fill", function(d) {return color(d.topicName);});
var text = node.append("text")
.attr("text-anchor", "middle")
.attr("dy", ".3em")
.text(function(d) { return d.className.substring(0, d.r / 3)});
text.append("tspan")
.attr("dy", "1.2em")
.attr("x", 0)
.text(function(d) {return Math.ceil(d.value * 10000) /10000; });
// Returns a flattened hierarchy containing all leaf nodes under the root.
function classes(root) {
var classes = [];
function recurse(term, node) {
if (node.children) node.children.forEach(function(child) { recurse(node.term, child); });
else classes.push({topicName: node.topicId, className: node.term, value: node.probability});
}
recurse(null, root);
return {children: classes};
}
</script>
""")
// Similar as above but for FL
val topicIndices = ldaModel_FL.describeTopics(maxTermsPerTopic = 6)
val vocabList = vectorizer_FL.vocabulary
val topics = topicIndices.map { case (terms, termWeights) =>
terms.map(vocabList(_)).zip(termWeights)
}
println(s"$numTopics_FL topics:")
topics.zipWithIndex.foreach { case (topic, i) =>
println(s"TOPIC $i")
topic.foreach { case (term, weight) => println(s"$term\t$weight") }
println(s"==========")
}
// Zip topic terms with topic IDs
val termArray = topics.zipWithIndex
// Transform data into the form (term, probability, topicId)
val termRDD = sc.parallelize(termArray)
val termRDD2 =termRDD.flatMap( (x: (Array[(String, Double)], Int)) => {
val arrayOfTuple = x._1
val topicId = x._2
arrayOfTuple.map(el => (el._1, el._2, topicId))
})
// Create DF with proper column names
val termDF = termRDD2.toDF.withColumnRenamed("_1", "term").withColumnRenamed("_2", "probability").withColumnRenamed("_3", "topicId")
// Create JSON data to display topic distribution of forum in FB
val rawJson = termDF.toJSON.collect().mkString(",\n")
displayHTML(s"""
<!DOCTYPE html>
<meta charset="utf-8">
<style>
circle {
fill: rgb(31, 119, 180);
fill-opacity: 0.5;
stroke: rgb(31, 119, 180);
stroke-width: 1px;
}
.leaf circle {
fill: #ff7f0e;
fill-opacity: 1;
}
text {
font: 14px sans-serif;
}
</style>
<body>
<script src="https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.5/d3.min.js"></script>
<script>
var json = {
"name": "data",
"children": [
{
"name": "topics",
"children": [
${rawJson}
]
}
]
};
var r = 1000,
format = d3.format(",d"),
fill = d3.scale.category20c();
var bubble = d3.layout.pack()
.sort(null)
.size([r, r])
.padding(1.5);
var vis = d3.select("body").append("svg")
.attr("width", r)
.attr("height", r)
.attr("class", "bubble");
var node = vis.selectAll("g.node")
.data(bubble.nodes(classes(json))
.filter(function(d) { return !d.children; }))
.enter().append("g")
.attr("class", "node")
.attr("transform", function(d) { return "translate(" + d.x + "," + d.y + ")"; })
color = d3.scale.category20();
node.append("title")
.text(function(d) { return d.className + ": " + format(d.value); });
node.append("circle")
.attr("r", function(d) { return d.r; })
.style("fill", function(d) {return color(d.topicName);});
var text = node.append("text")
.attr("text-anchor", "middle")
.attr("dy", ".3em")
.text(function(d) { return d.className.substring(0, d.r / 3)});
text.append("tspan")
.attr("dy", "1.2em")
.attr("x", 0)
.text(function(d) {return Math.ceil(d.value * 10000) /10000; });
// Returns a flattened hierarchy containing all leaf nodes under the root.
function classes(root) {
var classes = [];
function recurse(term, node) {
if (node.children) node.children.forEach(function(child) { recurse(node.term, child); });
else classes.push({topicName: node.topicId, className: node.term, value: node.probability});
}
recurse(null, root);
return {children: classes};
}
</script>
""")
def rawJson(lda_model: org.apache.spark.mllib.clustering.LDAModel, vectorizer: org.apache.spark.ml.feature.CountVectorizerModel): String = {
val topicIndices = lda_model.describeTopics(maxTermsPerTopic = 6)
val vocabList = vectorizer.vocabulary
val topics = topicIndices.map { case (terms, termWeights) =>
terms.map(vocabList(_)).zip(termWeights)
}
println(s"$numTopics_FL topics:")
topics.zipWithIndex.foreach { case (topic, i) =>
println(s"TOPIC $i")
topic.foreach { case (term, weight) => println(s"$term\t$weight") }
println(s"==========")
}
// Zip topic terms with topic IDs
val termArray = topics.zipWithIndex
// Transform data into the form (term, probability, topicId)
val termRDD = sc.parallelize(termArray)
val termRDD2 =termRDD.flatMap( (x: (Array[(String, Double)], Int)) => {
val arrayOfTuple = x._1
val topicId = x._2
arrayOfTuple.map(el => (el._1, el._2, topicId))
})
// Create DF with proper column names
val termDF = termRDD2.toDF.withColumnRenamed("_1", "term").withColumnRenamed("_2", "probability").withColumnRenamed("_3", "topicId")
// Create JSON data to display topic distribution
termDF.toJSON.collect().mkString(",\n")
}
// Create JSON data to display topic distribution
val rawJson_FL = rawJson(ldaModel_FL, vectorizer_FL)
val rawJson_FB = rawJson(ldaModel_FB, vectorizer_FB)
displayHTML(s"""
<!DOCTYPE html>
<meta charset="utf-8">
<style>
circle {
fill: rgb(31, 119, 180);
fill-opacity: 0.5;
stroke: rgb(31, 119, 180);
stroke-width: 1px;
}
.leaf circle {
fill: #ff7f0e;
fill-opacity: 1;
}
text {
font: 12px sans-serif;
}
</style>
<body>
<script src="https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.5/d3.min.js"></script>
<script>
/////////////////////////////////////////////////////////////////////////////
var json_FL = {
"name": "data",
"children": [
{
"name": "topics",
"children": [
${rawJson_FL}
]
}
]
};
var r1 = 500,
format = d3.format(",d"),
fill = d3.scale.category20c();
var bubble1 = d3.layout.pack()
.sort(null)
.size([r1, r1])
.padding(1.5);
var vis1 = d3.select("body").append("svg")
.attr("width", r1)
.attr("height", r1)
.attr("class", "bubble1");
var node = vis1.selectAll("g.node")
.data(bubble1.nodes(classes(json_FL))
.filter(function(d) { return !d.children; }))
.enter().append("g")
.attr("class", "node")
.attr("transform", function(d) { return "translate(" + d.x + "," + d.y + ")"; })
color = d3.scale.category20();
node.append("title")
.text(function(d) { return d.className + ": " + format(d.value); });
node.append("circle")
.attr("r", function(d) { return d.r; })
.style("fill", function(d) {return color(d.topicName);});
var text = node.append("text")
.attr("text-anchor", "middle")
.attr("dy", ".3em")
.text(function(d) { return d.className.substring(0, d.r / 3)});
text.append("tspan")
.attr("dy", "1.2em")
.attr("x", 0)
.text(function(d) {return Math.ceil(d.value * 10000) /10000; });
/////////////////////////////////////////////////////////////////////////////
var json_FB = {
"name": "data",
"children": [
{
"name": "topics",
"children": [
${rawJson_FB}
]
}
]
};
var r2 = 500,
format = d3.format(",d"),
fill = d3.scale.category20c();
var bubble2 = d3.layout.pack()
.sort(null)
.size([r2, r2])
.padding(1.5);
var vis2 = d3.select("body").append("svg")
.attr("width", r2)
.attr("height", r2)
.attr("class", "bubble1");
var node = vis2.selectAll("g.node")
.data(bubble1.nodes(classes(json_FB))
.filter(function(d) { return !d.children; }))
.enter().append("g")
.attr("class", "node")
.attr("transform", function(d) { return "translate(" + d.x + "," + d.y + ")"; })
color = d3.scale.category20();
node.append("title")
.text(function(d) { return d.className + ": " + format(d.value); });
node.append("circle")
.attr("r", function(d) { return d.r; })
.style("fill", function(d) {return color(d.topicName);});
var text = node.append("text")
.attr("text-anchor", "middle")
.attr("dy", ".3em")
.text(function(d) { return d.className.substring(0, d.r / 3)});
text.append("tspan")
.attr("dy", "1.2em")
.attr("x", 0)
.text(function(d) {return Math.ceil(d.value * 10000) /10000; });
/////////////////////////////////////////////////////////////////////////////
// Returns a flattened hierarchy containing all leaf nodes under the root.
function classes(root) {
var classes = [];
function recurse(term, node) {
if (node.children) node.children.forEach(function(child) { recurse(node.term, child); });
else classes.push({topicName: node.topicId, className: node.term, value: node.probability});
}
recurse(null, root);
return {children: classes};
}
</script>
""")