This notebook extends the TF v2.x code from the single machine notebook 23_ds_single_machine. The modification are such that the code enables multi-machine training using the horovod framwork.
We will highlight the changes compared the single machine implementation.
First: Check if the data is in local. If not, go to notebook 1_data_and_preprocssing and download the data from dbfs to local.
ls 06_LHC/
LICENSE
README.md
data
h5
models
scripts
utils
Get the imports.
import argparse
from argparse import Namespace
from datetime import datetime
import numpy as np
import tensorflow as tf
import socket
import os
import sys
from sklearn.cluster import KMeans
from tqdm import tqdm
import h5py
#Added matplot for accuracy
import matplotlib.pyplot as plt
np.set_printoptions(edgeitems=1000)
from scipy.optimize import linear_sum_assignment
BASE_DIR = os.path.join(os.getcwd(), '06_LHC','scripts')
#os.path.dirname(os.path.abspath(__file__))
sys.path.append(BASE_DIR)
sys.path.append(os.path.join(BASE_DIR, '..', 'models'))
sys.path.append(os.path.join(BASE_DIR, '..', 'utils'))
import provider
import gapnet_classify as MODEL
Get the input parameters.
parserdict = {'max_dim': 3, #help='Dimension of the encoding layer [Default: 3]')
'n_clusters': 3, #help='Number of clusters [Default: 3]')
'gpu': 0, #help='GPU to use [default: GPU 0]')
'model': 'gapnet_clasify', #help='Model name [default: gapnet_classify]')
'log_dir': 'log', #help='Log dir [default: log]')
'num_point': 100, #help='Point Number [default: 100]')
'max_epoch': 100, #help='Epoch to run [default: 200]')
'epochs_pretrain': 20, #help='Epochs to for pretraining [default: 10]')
'batch_size': 1024, #help='Batch Size during training [default: 512]')
'learning_rate': 0.001, #help='Initial learning rate [default: 0.01]')
'momentum': 0.9, #help='Initial momentum [default: 0.9]')
'optimizer': 'adam', #help='adam or momentum [default: adam]')
'decay_step': 500000, #help='Decay step for lr decay [default: 500000]')
'wd': 0.0, #help='Weight Decay [Default: 0.0]')
'decay_rate': 0.5, #help='Decay rate for lr decay [default: 0.5]')
'output_dir': 'train_results', #help='Directory that stores all training logs and trained models')
'data_dir': os.path.join(os.getcwd(),'06_LHC', 'h5'), # '../h5', #help='directory with data [default: hdf5_data]')
'nfeat': 8, #help='Number of features [default: 8]')
'ncat': 20, #help='Number of categories [default: 20]')
}
FLAGS = Namespace(**parserdict)
H5_DIR = FLAGS.data_dir
EPOCH_CNT = 0
MAX_PRETRAIN = FLAGS.epochs_pretrain
BATCH_SIZE = FLAGS.batch_size
NUM_POINT = FLAGS.num_point
NUM_FEAT = FLAGS.nfeat
NUM_CLASSES = FLAGS.ncat
MAX_EPOCH = FLAGS.max_epoch
BASE_LEARNING_RATE = FLAGS.learning_rate
GPU_INDEX = FLAGS.gpu
MOMENTUM = FLAGS.momentum
OPTIMIZER = FLAGS.optimizer
DECAY_STEP = FLAGS.decay_step
DECAY_RATE = FLAGS.decay_rate
# MODEL = importlib.import_module(FLAGS.model) # import network module
MODEL_FILE = os.path.join(BASE_DIR, 'models', FLAGS.model + '.py')
LOG_DIR = os.path.join(os.getcwd(), '06_LHC', 'logs', FLAGS.log_dir)
if not os.path.exists(LOG_DIR): os.makedirs(LOG_DIR)
os.system('cp %s.py %s' % (MODEL_FILE, LOG_DIR)) # bkp of model def
os.system('cp train_kmeans.py %s' % (LOG_DIR)) # bkp of train procedure
BN_INIT_DECAY = 0.5
BN_DECAY_DECAY_RATE = 0.5
BN_DECAY_DECAY_STEP = float(DECAY_STEP)
BN_DECAY_CLIP = 0.99
LEARNING_RATE_CLIP = 1e-5
HOSTNAME = socket.gethostname()
TRAIN_FILES = provider.getDataFiles(os.path.join(H5_DIR, 'train_files_wztop.txt'))
TEST_FILES = provider.getDataFiles(os.path.join(H5_DIR, 'test_files_wztop.txt'))
Define the utils functions.
def get_learning_rate(batch):
learning_rate = tf.compat.v1.train.exponential_decay(
BASE_LEARNING_RATE, # Base learning rate.
batch * BATCH_SIZE, # Current index into the dataset.
DECAY_STEP, # Decay step.
DECAY_RATE, # Decay rate.
staircase=True)
learning_rate = tf.minimum(learning_rate, LEARNING_RATE_CLIP) # CLIP THE LEARNING RATE!
return learning_rate
def get_bn_decay(batch):
bn_momentum = tf.compat.v1.train.exponential_decay(
BN_INIT_DECAY,
batch * BATCH_SIZE,
BN_DECAY_DECAY_STEP,
BN_DECAY_DECAY_RATE,
staircase=True)
bn_decay = tf.minimum(BN_DECAY_CLIP, 1 - bn_momentum)
return bn_decay
Modification: - create checkpoint directory for horovod - directory is user chosen
import os
import time
checkpoint_dir = '/dbfs/databricks/driver/06_LHC/logs/train/{}/'.format(time.time())
os.makedirs(checkpoint_dir)
Create horovod h5 loading function: - not the rank and size is inputed. - rank is the current device id - size is the total number of available GPUs - we split the data in the h5 file for each device.
def load_h5_hvd(h5_filename, rank=0, size=1):
f = h5py.File(h5_filename, 'r')
data = f['data'][rank::size]
label = f['pid'][rank::size]
seg = f['label'][rank::size]
print("loaded {0} events".format(len(data)))
return (data, label, seg)
Main training function. Modifications are: - import packages again. Otherwise single devices may cause problems. - initialise the horovod runner - copy the files from local to each GPU such that they are available for horovod. - scale the learning rate by the number of available devices. - add a horovod specific distributed optimizer. - use hooks for checkpoint saving ever 1000 steps. - switch from a normal TF training session to a monitored training session.
def train_hvd():
import horovod.tensorflow as hvd
import tensorflow as tf
import shutil
# do all the imports here again in order for hvd to work nicely
import horovod.tensorflow as hvd
import argparse, shlex
from datetime import datetime
import numpy as np
import tensorflow as tf
import socket
import os
import sys
from sklearn.cluster import KMeans
from tqdm import tqdm
np.set_printoptions(edgeitems=1000)
from scipy.optimize import linear_sum_assignment
BASE_DIR = os.path.join(os.getcwd(), '06_LHC','scripts')
sys.path.append(BASE_DIR)
sys.path.append(os.path.join(BASE_DIR, '..', 'models'))
sys.path.append(os.path.join(BASE_DIR, '..', 'utils'))
# HOROVOD: initialize Horovod.
hvd.init()
# HOROVOD: Copy files from local to each single GPU directory
src = "/dbfs/FileStore/06_LHC"
dst = os.path.join(os.getcwd(), '06_LHC')
print("Copying data/files to local horovod folder...")
shutil.copytree(src, dst)
print("Done with copying!")
import provider
import gapnet_classify as MODEL
with tf.Graph().as_default():
with tf.device('/gpu:' + str(GPU_INDEX)):
#ADDED THIS TO RECORD ACCURACY
epochs_acc = []
pointclouds_pl, labels_pl = MODEL.placeholder_inputs(BATCH_SIZE, NUM_POINT, NUM_FEAT)
is_training_pl = tf.compat.v1.placeholder(tf.bool, shape=())
# Note the global_step=batch parameter to minimize.
# That tells the optimizer to helpfully increment the 'batch' parameter for you every time it trains.
batch = tf.Variable(0)
alpha = tf.compat.v1.placeholder(dtype=tf.float32, shape=())
bn_decay = get_bn_decay(batch)
tf.compat.v1.summary.scalar('bn_decay', bn_decay)
print("--- Get model and loss")
pred, max_pool = MODEL.get_model(pointclouds_pl, is_training=is_training_pl,
bn_decay=bn_decay,
num_class=NUM_CLASSES, weight_decay=FLAGS.wd,
)
class_loss = MODEL.get_focal_loss(pred, labels_pl, NUM_CLASSES)
mu = tf.Variable(tf.zeros(shape=(FLAGS.n_clusters, FLAGS.max_dim)), name="mu",
trainable=True) # k centroids
kmeans_loss, stack_dist = MODEL.get_loss_kmeans(max_pool, mu, FLAGS.max_dim,
FLAGS.n_clusters, alpha)
full_loss = kmeans_loss + class_loss
print("--- Get training operator")
# Get training operator
learning_rate = get_learning_rate(batch)
# HOROVOD: scale learning rate from hvd dependent number of processes (=hvd.size)
tf.compat.v1.summary.scalar('learning_rate', learning_rate * hvd.size())
if OPTIMIZER == 'momentum':
optimizer = tf.compat.v1.train.MomentumOptimizer(learning_rate * hvd.size(), momentum=MOMENTUM)
elif OPTIMIZER == 'adam':
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate * hvd.size())
# HOROVOD: add Horovod Distributed Optimizer
optimizer = hvd.DistributedOptimizer(optimizer)
global_step = tf.compat.v1.train.get_or_create_global_step()
train_op_full = optimizer.minimize(full_loss, global_step=global_step) #batch)
train_op = optimizer.minimize(class_loss, global_step=global_step) #batch)
# Add ops to save and restore all the variables.
saver = tf.compat.v1.train.Saver()
# HOROVOD
hooks = [
# Horovod: BroadcastGlobalVariablesHook broadcasts initial variable states
# from rank 0 to all other processes. This is necessary to ensure consistent
# initialization of all workers when training is started with random weights
# or restored from a checkpoint.
hvd.BroadcastGlobalVariablesHook(0),
#checkpoint_dir_mod = checkpoint_dir if hvd.rank() == 0 else None
tf.compat.v1.train.CheckpointSaverHook(checkpoint_dir=checkpoint_dir,
checkpoint_basename='cluster.ckpt',
save_steps=1_000
),
# this one basically prints every n steps the "step" and the "loss". Output is cleaner without
# tf.compat.v1.train.LoggingTensorHook(tensors={'step': global_step, 'loss': full_loss}, every_n_iter=75),
]
# Create a session
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
config.allow_soft_placement = True
config.log_device_placement = False
config.gpu_options.visible_device_list = str(hvd.local_rank())
# global variable initializer must be defined before session definition
init_global_step = tf.compat.v1.global_variables_initializer()
# MonitoredTrainingSession
# takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
#checkpoint_dir_mod = checkpoint_dir if hvd.rank() == 0 else None
sess = tf.compat.v1.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,
hooks=hooks,
config=config)
# get one batch_data from the training files in oder to inintialise the session
train_idxs = np.arange(0, len(TRAIN_FILES))
current_file = os.path.join(os.getcwd(), '06_LHC', 'h5', TRAIN_FILES[train_idxs[0]])
current_data, current_label, current_cluster = load_h5_hvd(current_file, hvd.rank(), hvd.size())
batch_data, batch_label = get_batch(current_data, current_label, 0, BATCH_SIZE)
#
feed_dict = {pointclouds_pl: batch_data,
labels_pl: batch_label,
is_training_pl: False,
alpha: 2 * (EPOCH_CNT - MAX_PRETRAIN + 1),}
#NOT SO CLEAR THAT init_global_step IS NECESSARY.
sess.run(init_global_step, feed_dict=feed_dict)
# hels with merging: CHANGE THIS IF POSSIBLE
sess.graph._unsafe_unfinalize()
# Add summary writers
merged = tf.compat.v1.summary.merge_all()
train_writer = tf.compat.v1.summary.FileWriter(os.path.join(LOG_DIR, 'train'), sess.graph)
test_writer = tf.compat.v1.summary.FileWriter(os.path.join(LOG_DIR, 'test'), sess.graph)
# Init variables
print("Total number of weights for the model: ", np.sum([np.prod(v.get_shape().as_list()) for v in tf.compat.v1.trainable_variables()]))
ops = {'pointclouds_pl': pointclouds_pl,
'labels_pl': labels_pl,
'is_training_pl': is_training_pl,
'max_pool': max_pool,
'pred': pred,
'alpha': alpha,
'mu': mu,
'stack_dist': stack_dist,
'class_loss': class_loss,
'kmeans_loss': kmeans_loss,
'train_op': train_op,
'train_op_full': train_op_full,
'merged': merged,
'step': batch,
'learning_rate': learning_rate
}
for epoch in range(MAX_EPOCH):
print('\n**** EPOCH %03d ****' % (epoch))
sys.stdout.flush()
is_full_training = epoch > MAX_PRETRAIN
max_pool = train_one_epoch(sess, ops, train_writer, hvd.rank(), hvd.size(), is_full_training)
if epoch == MAX_PRETRAIN:
centers = KMeans(n_clusters=FLAGS.n_clusters).fit(np.squeeze(max_pool))
centers = centers.cluster_centers_
sess.run(tf.compat.v1.assign(mu, centers))
#eval_one_epoch(sess, ops, test_writer, hvd.rank(), hvd.size(), is_full_training)
#Added these lines to record accuracy
epoch_acc = eval_one_epoch(sess, ops, test_writer, hvd.rank(), hvd.size(), is_full_training)
epochs_acc.append(epoch_acc)
"""if is_full_training:
save_path = saver.save(sess, os.path.join(LOG_DIR, 'cluster.ckpt'))
else:
save_path = saver.save(sess, os.path.join(LOG_DIR, 'model.ckpt'))"""
#print("Model saved in file: %s" % save_path)
return epochs_acc
Training utils.
def get_batch(data, label, start_idx, end_idx):
batch_label = label[start_idx:end_idx]
batch_data = data[start_idx:end_idx, :, :]
return batch_data, batch_label
def cluster_acc(y_true, y_pred):
"""
Calculate clustering accuracy. Require scikit-learn installed
"""
y_true = y_true.astype(np.int64)
D = max(y_pred.max(), y_true.max()) + 1
w = np.zeros((D, D), dtype=np.int64)
for i in range(y_pred.size):
w[y_pred[i], y_true[i]] += 1
ind = linear_sum_assignment(w.max() - w)
ind = np.asarray(ind)
ind = np.transpose(ind)
return sum([w[i, j] for i, j in ind]) * 1.0 / y_pred.size
One epoch training and evaluation functions: - the applicable horovod rank and size is fed into both functions. - use the rank and size to load the correct h5 data. - remove progress bars since progress bars from each device would overlap.
def train_one_epoch(sess, ops, train_writer, hvd_rank, hvd_size, is_full_training):
""" ops: dict mapping from string to tf ops """
is_training = True
train_idxs = np.arange(0, len(TRAIN_FILES))
acc = loss_sum = 0
y_pool = []
for fn in range(len(TRAIN_FILES)):
# print('----' + str(fn) + '-----')
current_file = os.path.join(os.getcwd(), '06_LHC', 'h5', TRAIN_FILES[train_idxs[fn]])
current_data, current_label, current_cluster = load_h5_hvd(current_file, hvd_rank, hvd_size)
current_label = np.squeeze(current_label)
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
# num_batches = 5
print(str(datetime.now()))
# initialise progress bar
#process_desc = "TRAINING: Loss {:2.3e}"
#progress_bar = tqdm(initial=0, leave=True, total=num_batches,
# desc=process_desc.format(0),
# position=0)
for batch_idx in range(num_batches):
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx + 1) * BATCH_SIZE
batch_data, batch_label = get_batch(current_data, current_label, start_idx, end_idx)
cur_batch_size = end_idx - start_idx
# print(batch_weight)
feed_dict = {ops['pointclouds_pl']: batch_data,
ops['labels_pl']: batch_label,
ops['is_training_pl']: is_training,
ops['alpha']: 2 * (EPOCH_CNT - MAX_PRETRAIN + 1),}
if is_full_training:
summary, step, _, loss_val, dist, lr = sess.run([ops['merged'], ops['step'],
ops['train_op_full'], ops['kmeans_loss'],
ops['stack_dist'], ops['learning_rate']],
feed_dict=feed_dict)
batch_cluster = np.array([np.where(r == 1)[0][0] for r in current_cluster[start_idx:end_idx]])
cluster_assign = np.zeros((cur_batch_size), dtype=int)
for i in range(cur_batch_size):
index_closest_cluster = np.argmin(dist[:, i])
cluster_assign[i] = index_closest_cluster
acc += cluster_acc(batch_cluster, cluster_assign)
else:
summary, step, _, loss_val, max_pool, lr = sess.run([ops['merged'], ops['step'],
ops['train_op'], ops['class_loss'],
ops['max_pool'], ops['learning_rate']],
feed_dict=feed_dict)
if len(y_pool) == 0:
y_pool = np.squeeze(max_pool)
else:
y_pool = np.concatenate((y_pool, np.squeeze(max_pool)), axis=0)
loss_sum += np.mean(loss_val)
#train_writer.add_summary(summary, step)
if hvd_rank == 0:
train_writer.add_summary(summary, step)
# Update train bar
#process_desc.format(loss_val)
#progress_bar.update(1)
#progress_bar.close()
print('learning rate: %f' % (lr))
print('train mean loss: %f' % (loss_sum / float(num_batches)))
#if is_full_training:
print('train clustering accuracy: %f' % (acc / float(num_batches)))
return y_pool
def eval_one_epoch(sess, ops, test_writer, hvd_rank, hvd_size, is_full_training):
""" ops: dict mapping from string to tf ops """
global EPOCH_CNT
is_training = False
test_idxs = np.arange(0, len(TEST_FILES))
# Test on all data: last batch might be smaller than BATCH_SIZE
loss_sum = acc = 0
acc_kmeans = 0
for fn in range(len(TEST_FILES)):
# print('----' + str(fn) + '-----')
current_file = os.path.join(os.getcwd(), '06_LHC', 'h5', TEST_FILES[test_idxs[fn]])
current_data, current_label, current_cluster = load_h5_hvd(current_file, hvd_rank, hvd_size)
current_label = np.squeeze(current_label)
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
"""process_desc = "VALIDATION: Loss {:2.3e}"
progress_bar = tqdm(initial=0, leave=True, total=num_batches,
desc=process_desc.format(0),
position=0)"""
for batch_idx in range(num_batches):
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx + 1) * BATCH_SIZE
batch_data, batch_label = get_batch(current_data, current_label, start_idx, end_idx)
cur_batch_size = end_idx - start_idx
feed_dict = {ops['pointclouds_pl']: batch_data,
ops['is_training_pl']: is_training,
ops['labels_pl']: batch_label,
ops['alpha']: 2 * (EPOCH_CNT - MAX_PRETRAIN + 1),}
if is_full_training:
summary, step, loss_val, max_pool, dist, mu = sess.run([ops['merged'], ops['step'],
ops['kmeans_loss'],
ops['max_pool'], ops['stack_dist'],
ops['mu']],
feed_dict=feed_dict)
batch_cluster = np.array([np.where(r == 1)[0][0] for r in current_cluster[start_idx:end_idx]])
cluster_assign = np.zeros((cur_batch_size), dtype=int)
for i in range(cur_batch_size):
index_closest_cluster = np.argmin(dist[:, i])
cluster_assign[i] = index_closest_cluster
acc += cluster_acc(batch_cluster, cluster_assign)
else:
summary, step, loss_val = sess.run([ops['merged'], ops['step'],
ops['class_loss']],
feed_dict=feed_dict)
#test_writer.add_summary(summary, step)
if hvd_rank == 0:
test_writer.add_summary(summary, step)
loss_sum += np.mean(loss_val)
"""# Update train bar
process_desc.format(loss_val)
progress_bar.update(1)"""
#progress_bar.close()
total_loss = loss_sum * 1.0 / float(num_batches)
print('test mean loss: %f' % (total_loss))
#if is_full_training:
print('testing clustering accuracy: %f' % (acc / float(num_batches)))
return acc/float(num_batches)
EPOCH_CNT += 1
Run the training: - initialise the Horovod runner with np=2 GPUs. The cluster does not allow more GPUs - run the horovod runner with the given training function.
from sparkdl import HorovodRunner
hr = HorovodRunner(np=2)
epochs_acc=hr.run(train_hvd)
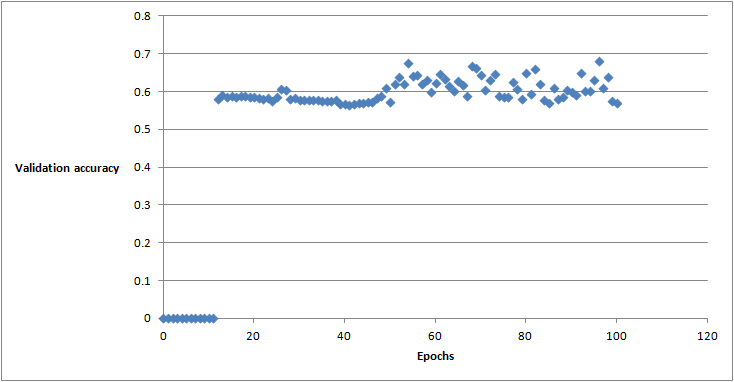
plt.plot(epochs_acc)
plt.ylabel('Validation accuracy')
plt.xlabel('epochs')
plt.show()
plt.savefig('distributed.png')
print(epochs_acc)
Results: - Execution of the command for np=2 GPUs takes 3.39 hours. - Plot below show the validation accuracy vs epoch. - Note that we switch to the full loss after n=10 epochs. - We observe an improvement in the cluster validation set accuracy after around 50 epochs. - Highest cluster validation set accuracy lies at about 68%. - Output of the algorithm is the stored model.
checkpoint_dir