Wikipedia analysis using Latent Dirichlet Allocation (LDA)
Authors: Axel Berg, Johan Grönqvist, Jens Gulin
Completed: 2021-01-13 Edited: 2021-01-25
Introduction
As part of the course assignment to set up a scalable pipeline, we run topic analysis on Wikipedia articles. Latent Dirichlet Allocation (LDA) extracts topics from the corpus and we use those to assign each article to the most covered topic. As a proof-of-concept system, we make a simple recommender system, highlighting the highest scoring articles for the topic as a follow-up of the currently read article.
Although the pipeline is meant to be generalizable, this workbook is not streamlined, but also explores the data. This is to help presentation, and also to support any effort to re-use the pipeline on another data source. If this was an automatic job on a stable data source, the throughput would benefit from removing the intermediate snapshot storage and sample output.
We currently run the pipeline on Swedish Wikipedia. Changing the download and data cleaning slightly, it should work on other sources. Most of the cells are language agnostic, but stopwords and tokenization needs to be adapted to new languages. Swedish Wikipedia is a bit peculiar, having a high number of articles automatically generated from structured data by bots. We discard those articles from the analysis, since their relatively high number and uniform wording skewed the results. The detection of auto-generated articles is thus specific and could be skipped or changed for other languages.
Results
We provide a notebook, primarily in Scala programming language, that can run on a Databricks cluster (7.3 LTS, including Apache Spark 3.0.1, Scala 2.12). Since this was a shared cluster with dynamic scaling, the runtime performance isn't clearly defined, but some notable measures are mentioned for reference. The reference cluster has up to 8 workers, each with 4 CPU and no GPU.
The pipeline works well and the topics produced seems ok. We have done no further qualitative evaluation and no systematic search for optimal hyper-parameters. In regards to runtime performance, the scalable cluster handles the workload in a fair manner and we have not focused on optimization at this point.
There are several potential improvements that are outside of the scope of this project. They include changes to improve execution time and topic quality, as well as use-cases utilizing the created model.
Scope
This notebook exemplifies topic analysis on Swedish Wikipedia. For overview and documentation, the code is divided into sections. Use the outline to navigate to relevant parts. The following stages illustrate the flow of the pipeline.
- Folders and Files
- Prepare language specific stop-word lists.
- Download a data dump of all pages from Wikipedia (compressed XML of current state).
- Clean the data
- Keep only article-space pages not automatically generated by algorithms.
- Filter the XML to extract meta data and raw article text.
- Remove links and other markup-formatting.
- Generate the LDA model
- Remove stopwords
- Train the model
- Analyse the model
- Pick an article and explore its topics.
- Recommend similar articles.
References
- https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation
- https://spark.apache.org/docs/latest/api/scala/org/apache/spark/mllib/clustering/LDA.html
- https://dumps.wikimedia.org/svwiki/20201120/
- 034_LDA_20NewsGroupsSmall see notebook
scalable-data-science/000_2-sds-3-x-ml/034_LDA_20NewsGroupSmall - 034_LDA_20NewsGroupsSmall (link to databricks)
Acknowledgements
This work was partially supported by the Wallenberg AI, Autonomous Systems and Software Program (WASP) funded by the Knut and Alice Wallenberg Foundation.
Folders and Files
Define variables to make the rest of the notebook more generic.
To allow pipelines running in parallel and to simplify configurability, work is parameterized in a file and folder structure.
To simplify exploration, the data is saved to file as snapshots. This also avoids the need to rerun previous sections in every session.
// Setup Wikipedia source
val lang = "sv"
val freeze_date = "20201120"
val wp_file = s"${lang}wiki-${freeze_date}-pages-articles.xml"
val wp_zip_remote = s"https://dumps.wikimedia.org/${lang}wiki/${freeze_date}/${wp_file}.bz2"
// Stopwords download soure
val stopwords_remote = "https://raw.githubusercontent.com/peterdalle/svensktext/master/stoppord/stoppord.csv"
// Setup base paths for storage
val group = "05_lda" // directory name to separate file structure, allows to run different instances in parallel
val localpath=s"file:/databricks/driver/$group/"
val dir_local = s"$group/"
val dir = s"dbfs:/datasets/$group/"
// Some file names
val stopwords_file = "stopwords.csv"
val stopwords_store = s"${dir}${stopwords_file}"
val wp_store = s"${dir}${wp_file}"
val filtered_articles_store = s"${dir}filtered_articles_${lang}_${freeze_date}"
val lda_countVector_store = s"${dir}lda_countvector_${lang}_${freeze_date}"
val lda_model_store = s"${dir}lda_${lang}_${freeze_date}.model"
lang: String = sv
freeze_date: String = 20201120
wp_file: String = svwiki-20201120-pages-articles.xml
wp_zip_remote: String = https://dumps.wikimedia.org/svwiki/20201120/svwiki-20201120-pages-articles.xml.bz2
stopwords_remote: String = https://raw.githubusercontent.com/peterdalle/svensktext/master/stoppord/stoppord.csv
group: String = 05_lda
localpath: String = file:/databricks/driver/05_lda/
dir_local: String = 05_lda/
dir: String = dbfs:/datasets/05_lda/
stopwords_file: String = stopwords.csv
stopwords_store: String = dbfs:/datasets/05_lda/stopwords.csv
wp_store: String = dbfs:/datasets/05_lda/svwiki-20201120-pages-articles.xml
filtered_articles_store: String = dbfs:/datasets/05_lda/filtered_articles_sv_20201120
lda_countVector_store: String = dbfs:/datasets/05_lda/lda_countvector_sv_20201120
lda_model_store: String = dbfs:/datasets/05_lda/lda_sv_20201120.model
# Just check where local path is
pwd
/databricks/driver
// Run this only to force a clean start
/*
// Delete DBFS store
dbutils.fs.rm(dir,recurse=true)
// Delete local files
import org.apache.commons.io.FileUtils;
import java.io.File;
FileUtils.deleteDirectory(new File(dir_local))
*/
import org.apache.commons.io.FileUtils
import java.io.File
// Prepare DBFS store
dbutils.fs.mkdirs(dir)
display(dbutils.fs.ls(dir))
// Prepare local folder
import org.apache.commons.io.FileUtils;
import java.io.File;
FileUtils.forceMkdir(new File(dir_local));
// Check local files
import sys.process._ // For spawning shell commands
s"ls -l ./ ${dir_local}" !!
warning: there was one feature warning; for details, enable `:setting -feature' or `:replay -feature'
import sys.process._
res19: String =
"./:
total 24
drwxr-xr-x 2 root root 4096 Jan 26 04:22 05_lda
drwxr-xr-x 2 root root 4096 Jan 1 1970 conf
-rw-r--r-- 1 root root 733 Jan 26 03:34 derby.log
drwxr-xr-x 3 root root 4096 Jan 26 03:33 eventlogs
drwxr-xr-x 2 root root 4096 Jan 26 04:15 ganglia
drwxr-xr-x 2 root root 4096 Jan 26 04:03 logs
05_lda/:
total 0
"
We download a list of suitable stopwords from a separate location.
// Download stopwords to store.
val local = s"${dir_local}${stopwords_file}"
val remote = stopwords_remote
try
{
// -nc prevents download if already exist. !! converts wget output to string.
s"wget -nc -O${local} ${remote}" !!
}
catch
{
case e: Throwable => println("Exception: " + e)
}
--2021-01-26 04:23:45-- https://raw.githubusercontent.com/peterdalle/svensktext/master/stoppord/stoppord.csv
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.52.133
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.52.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1936 (1.9K) [text/plain]
Saving to: ‘05_lda/stopwords.csv’
0K . 100% 15.9M=0s
2021-01-26 04:23:45 (15.9 MB/s) - ‘05_lda/stopwords.csv’ saved [1936/1936]
warning: there was one feature warning; for details, enable `:setting -feature' or `:replay -feature'
local: String = 05_lda/stopwords.csv
remote: String = https://raw.githubusercontent.com/peterdalle/svensktext/master/stoppord/stoppord.csv
res20: Any = ""
// Check local stopwords file
s"ls -l ${dir_local}" !!
warning: there was one feature warning; for details, enable `:setting -feature' or `:replay -feature'
res21: String =
"total 4
-rw-r--r-- 1 root root 1936 Jan 26 04:23 stopwords.csv
"
Move stopwords to DBFS
dbutils.fs.cp(localpath + stopwords_file, dir)
res22: Boolean = true
Check that the file exists, and has some contents.
display(dbutils.fs.ls(stopwords_store))
| path | name | size |
|---|---|---|
| dbfs:/datasets/05_lda/stopwords.csv | stopwords.csv | 1936.0 |
Wikipedia downloads are available as compressed files, and language and data is chosen via the name of the file. For a specific date, file share looks like this on Wikimedia.
There are several files, we use "pages-articles". This monolith file requires unpacking on driver node. To allow parallel download and unpacking the multistream may be a better choice.
In the current setup, download takes 6 minutes, extracting takes 10 minutes, moving to DBFS an additional 3 min.
// Download Wikipedia xml to store. -nc prevents overwrite if already exist. !! converts wget output to string.
val local = s"${dir_local}${wp_file}.bz2"
val remote = wp_zip_remote
try
{
s"wget -nc -O${local} ${remote}" !!
}
catch
{
case e: Throwable => println("Exception: " + e)
}
Extract the .xml-file
// Unpack bz2 to xml.
val local = s"${dir_local}${wp_file}.bz2"
try
{
// -d unpack, -k keep source file, -v activate some output. !! converts output to string.
s"bzip2 -dk -f -v ${local}" !!
}
catch
{
case e: Throwable => println("Exception: " + e)
}
05_lda/svwiki-20201120-pages-articles.xml.bz2: done
warning: there was one feature warning; for details, enable `:setting -feature' or `:replay -feature'
local: String = 05_lda/svwiki-20201120-pages-articles.xml.bz2
res27: Any = ""
s"ls ${dir_local}" !!
warning: there was one feature warning; for details, enable `:setting -feature' or `:replay -feature'
res28: String =
"stopwords.csv
svwiki-20201120-pages-articles.xml
svwiki-20201120-pages-articles.xml.bz2
"
Copy file to DBFS cluster
val local = s"${localpath}${wp_file}"
dbutils.fs.cp(local, dir)
local: String = file:/databricks/driver/05_lda/svwiki-20201120-pages-articles.xml
res29: Boolean = true
Verify that we now have an xml file with some contents. Swedish Wikipedia is 18 Gb unpacked.
display(dbutils.fs.ls(wp_store))
| path | name | size |
|---|---|---|
| dbfs:/datasets/05_lda/svwiki-20201120-pages-articles.xml | svwiki-20201120-pages-articles.xml | 1.8963312968e10 |
// Discard the local files no longer needed
import org.apache.commons.io.FileUtils;
import java.io.File;
FileUtils.cleanDirectory(new File(dir_local))
import org.apache.commons.io.FileUtils
import java.io.File
Clean the data
Before we can try to build an LDA model, we need to split the contents into separate pages, and discard anything that is not relevant article content.
In the current setup, loading and filtering takes 4 minutes, cleaning and saving snapshot takes another 6 minutes.
Extracting Pages
The full wikipedia dump is a very large xml files, each page (with meta data) is enclosed in <page> </page> tags, so we split it into an RDD.
// ---------------spark_import
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.sql.SQLContext
// ----------------xml_loader_import
import org.apache.hadoop.io.LongWritable
import org.apache.hadoop.io.Text
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.io.{ LongWritable, Text }
import com.databricks.spark.xml._
import org.apache.hadoop.conf.Configuration
// ---- Matching
import scala.util.matching.UnanchoredRegex
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.sql.SQLContext
import org.apache.hadoop.io.LongWritable
import org.apache.hadoop.io.Text
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.io.{LongWritable, Text}
import com.databricks.spark.xml._
import org.apache.hadoop.conf.Configuration
import scala.util.matching.UnanchoredRegex
Our function to read the data uses a library call to extract pages into an RDD.
def readWikiDump(sc: SparkContext, file: String) : RDD[String] = {
val conf = new Configuration()
conf.set(XmlInputFormat.START_TAG_KEY, "<page>")
conf.set(XmlInputFormat.END_TAG_KEY, "</page>")
val rdd = sc.newAPIHadoopFile(file,
classOf[XmlInputFormat],
classOf[LongWritable],
classOf[Text],
conf)
rdd.map{case (k,v) => (new String(v.copyBytes()))}
}
readWikiDump: (sc: org.apache.spark.SparkContext, file: String)org.apache.spark.rdd.RDD[String]
We look at a small sample to see that we succeeded in extracting pages, but we see that the pages still contain a lof of uninteresting bits in their text.
// Read the wiki dump
val dump = readWikiDump(sc, wp_store)
val n_wp_pages = dump.count()
dump.take(5)
Before we begin filtering the contents of pages, we want to discard:
- Pages that are redirects, i.e., pages containing a
<redirect_title="...">tag. - Non-articles, i.e., pages not in namespace 0 (not containing
<ns>0</ns>). - Any page containing the macro tag stating that it was generated by a robot.
val redirection = "<redirect title=".r
def is_not_redirect(source : String) = { redirection.findFirstIn(source) == None }
val ns0 = "<ns>0</ns>".r
def is_article(source : String) = { ns0.findFirstIn(source) != None }
val autogenerated = "robotskapad|Robotskapad".r
def is_not_autogenerated(source : String) = { autogenerated.findFirstIn(source) == None }
val articles = dump.filter(is_not_redirect).filter(is_article).filter(is_not_autogenerated)
val n_articles = articles.count()
articles.take(5)
Note that we have filtered away around 80% of the pages. Our initial list turned out to be mostly autogenerated articles, and those are not very interesting to our topic analysis pursuits, so better off discarded.
Meta data
Before we clean the xml and markup, we extract the article id and title, as we may want to use them when we analyze the resulting LDA model.
val id_regexp = raw"<id>([0-9]*)</id>".r
def extract_id(source : String) = {
val m = id_regexp.findFirstMatchIn(source).get
m.group(1).toLong
}
val title_regexp = raw"<title>([^\<\>]*)</title>".r
def extract_title(source : String) = {
val m = title_regexp.findFirstMatchIn(source).get
m.group(1)
}
val labelled_articles = articles.map(source => (extract_id(source), extract_title(source), source))
labelled_articles.take(5).map({case(id, title, contents) => title})
id_regexp: scala.util.matching.Regex = <id>([0-9]*)</id>
extract_id: (source: String)Long
title_regexp: scala.util.matching.Regex = <title>([^\<\>]*)</title>
extract_title: (source: String)String
labelled_articles: org.apache.spark.rdd.RDD[(Long, String, String)] = MapPartitionsRDD[1021] at map at command-2629358840275853:13
res11: Array[String] = Array(Amager, Afrika, Amerika, Abbekås, Alingsås)
To break out of the xml structure we perform the following steps:
- Replace html-strings
&,", ,<and>by&, `,,<and>, repsectively. * First the&, as it's used as the&in other sequences, e.g.. * The<and>from<and>are used in tags. * The"from"` is irrelevant, so we drop it entirely.- This is not an exhaustive list, so there may be other
- Remove the following start- and stop-tags, and the contents in between:
- id
- ns
- parentid
- timestamp
- contributor
- comment
- model
- format
- sha1
- We remove any tag, i.e., anything of the form
<A>for any stringA. - We remove anything enclosed in double-curly-braces, i.e., anything on the form
{{A}}for anyA.
def filter_xml(source : String) = {
val noAmp = raw"&".r.replaceAllIn(source, "&")
val noNbsp = raw" ".r.replaceAllIn(noAmp, " ")
val noQuot = raw""".r.replaceAllIn(noNbsp, "")
val noLt = raw"<".r.replaceAllIn(noQuot, "<")
val noGt = raw">".r.replaceAllIn(noLt, ">")
val tags = Seq("id", "ns", "parentid", "timestamp", "contributor", "comment", "model", "format", "sha1")
var current = noGt
for (tag <- tags) {
val start = s"<$tag>".r
val end = s"</$tag>".r
while (start.findAllIn(current).hasNext) {
val a = start.findAllIn(current).start
val b = end.findAllIn(current).start
val len = current.length
current = current.substring(0, a) + current.substring(b+tag.length+3, current.length)
assert (current.length < len)
}
}
current = raw"<[^<>]*>".r.replaceAllIn(current, "")
// A loop to remove innermost curly braces, then outer such things.
val curly = raw"\{[^\{\}]*\}".r
while (curly.findAllIn(current).hasNext)
{
current = curly.replaceAllIn(current, "")
}
current
}
val filtered_xml = labelled_articles.map({ case(id, title, source) => (id, title, filter_xml(source)) })
filtered_xml.take(5)
The resulting strings contain a lot of markup structure, and we clean it by:
- Removing all
$and\, as scala will otherwise try to help us by doing magic to them. - Removing all of the sections "Se även", "Referenser", "Noter", "Källor" and "Externa länkar"
- Remove links:
- Replace unnamed internal links
[[LinkName]]byLinkName - Replace named internal links
[[Link|Properties|Name]]byName - Replace unnamed internal links again to clean up
- Replace named external links
[Link Name]byName - Replace unnamed external links
[Link]byLink
- Replace unnamed internal links
- Convert all text to lower case
- Remove quotation marks
' - Remove repeated whitespace, as the obtained results contain a lot of whitespace.
Note: The last line in the cell below incorrectly gets rendered as a string, as the databricks notebook does not realize that (on line 3) the string raw"\" ends there, but it guesses that \" is a quoted character and that the string continues to the end of the cell.
def sanitize(source: String) : String = {
val noDollar = source.replaceAllLiterally("$", "")
val noBackSlash = noDollar.replaceAllLiterally(raw"\", "")
noBackSlash
}
val sanitized_xml = filtered_xml.map({case(id, title, source) => (id, title, sanitize(source))})
sanitize: (source: String)String
sanitized_xml: org.apache.spark.rdd.RDD[(Long, String, String)] = MapPartitionsRDD[1026] at map at command-2629358840275860:7
def filterMarkup(source: String) : String = {
// Loop to remove some specific sections
val sections = Seq("Se även", "Referenser", "Noter", "Källor", "Externa länkar")
var current = source
for (section <- sections) {
val regexp = s"[=]+ *$section *[=]+".r
if (regexp.findAllIn(current).hasNext)
{
val a = regexp.findAllIn(current).start
val pre = current.substring(0, a)
var post = current.substring(a, current.length)
post = regexp.replaceAllIn(post, "")
if ("^=".r.findAllIn(post).hasNext) {
val b = "^=".r.findAllIn(post).start
post = post.substring(b, post.length)
}
else {
post = ""
}
current = pre + post
}
}
// Unnamed internal links appear in figure captions, confusing later matching
val noUnnamedInternalLinks = raw"\[\[([^\|\]]*)\]\]".r.replaceAllIn(current, m => m.group(1))
// Loop to remove internal links and their properties
current = noUnnamedInternalLinks
val regexp = raw"\[\[[^\|\[]*\|([^\[\]]*)\]\]".r
while (regexp.findAllIn(current).hasNext) {
val len = current.length
current = regexp.replaceAllIn(current, m => "[[" + m.group(1) + "]]")
assert (current.length < len)
}
val noNamedInternalLinks = current
val noInternalLinks = raw"\[\[([^\]]*)\]\]".r.replaceAllIn(noNamedInternalLinks, m => m.group(1))
val noNamedExternalLinks = raw"\[[^ \[]*\ ([^\]]*)\]".r.replaceAllIn(noInternalLinks, m => m.group(1))
val noExternalLinks = raw"\[([^\]]*)\]".r.replaceAllIn(noNamedExternalLinks, m => m.group(1))
val lowerCase = noExternalLinks.toLowerCase
val noQuoteChars = raw"'".r.replaceAllIn(lowerCase, "")
// Loop to remove double whitespace characters
current = noQuoteChars
val doubleWhitespace = raw"\s(\s)".r
while (doubleWhitespace.findAllIn(current).hasNext) {
current = doubleWhitespace.replaceAllIn(current, m => m.group(1))
}
val noDoubleWhitespace = current
noDoubleWhitespace
}
val filtered = sanitized_xml.map({case (id, title, source) => (id, title, filterMarkup(source))})
filtered.take(2)
Before leaving this section, we may want to save our results, so that the next section can reload it.
// dbutils.fs.rm(filtered_articles_store, recurse=true)
res19: Boolean = true
val outputs = filtered.map({case (id, title, contents) => (id, title.replaceAllLiterally(",", "**COMMA**"), contents.replaceAllLiterally("\n", "**NEWLINE**"))})
outputs.saveAsTextFile(filtered_articles_store);
outputs: org.apache.spark.rdd.RDD[(Long, String, String)] = MapPartitionsRDD[1038] at map at command-4443336225071544:1
We now turn to the spark library for our next set of preparatory steps, and as the library work on dataframes, we do so as well.
Loading previous results
If we want to continue from the result saved at the end of the previous section, we can reload the data here.
val format = "^\\(([^,]*),([^,]*),(.*)\\)$".r
def parse_line(s : String) = {
assert (s(0) == '(')
val firstComma = s.indexOf(",")
val id = s.substring(1, firstComma).toLong
val afterId = s.substring(firstComma+1, s.length)
val nextComma = afterId.indexOf(",")
val title = afterId.substring(0, nextComma)
val contents = afterId.substring(nextComma+1, afterId.length-1)
assert (afterId(afterId.length-1) == ')')
(id, title.replaceAllLiterally("**COMMA**", ","), contents.replaceAllLiterally("**NEWLINE**", "\n"))
}
val filtered = spark.sparkContext.textFile(filtered_articles_store).map(parse_line)
val n_articles = filtered.count()
format: scala.util.matching.Regex = ^\(([^,]*),([^,]*),(.*)\)$
parse_line: (s: String)(Long, String, String)
filtered: org.apache.spark.rdd.RDD[(Long, String, String)] = MapPartitionsRDD[1042] at map at command-4443336225071727:15
n_articles: Long = 813245
DataFrame
The tokenization and stopword removal work on dataframes, so we create one, and look at some samples.
val corpus_df = filtered.toDF("id", "title", "contents")
corpus_df: org.apache.spark.sql.DataFrame = [id: bigint, title: string ... 1 more field]
The command below is the first step that requires all of the above steps to be completed for all the elements in the rdd, and it therefore takes a few minutes.
display(corpus_df.sample(0.0001))
Tokenization
In order to feed the articles into the LDA model, we first need to perform word tokenization. This splits the article into words, each matching the regular expression. In this case we ignore all non-alphabetic characters and only keep words with a minimal length of 4 characters in order to avoid short words that are not relevant to the subject.
import org.apache.spark.ml.feature.RegexTokenizer
// Set params for RegexTokenizer
val tokenizer = new RegexTokenizer()
.setGaps(true) // pattern below identifies non-word alphabet
.setPattern("[^a-zåäö]+") // break word and remove any detected non-word character(s).
.setMinTokenLength(4) // Filter away tokens with length < 4
.setInputCol("contents") // name of the input column
.setOutputCol("tokens") // name of the output column
// Tokenize document
val tokenized_df = tokenizer.transform(corpus_df)
import org.apache.spark.ml.feature.RegexTokenizer
tokenizer: org.apache.spark.ml.feature.RegexTokenizer = RegexTokenizer: uid=regexTok_5d41547188e0, minTokenLength=4, gaps=true, pattern=[^a-zåäö]+, toLowercase=true
tokenized_df: org.apache.spark.sql.DataFrame = [id: bigint, title: string ... 2 more fields]
display(tokenized_df.sample(0.0001))
Remove Stopwords
Next, we remove the stopwords from the article. This should be done iteratively, as the final model might find patterns in words that are not relevant. In our first iteration we found several words being used that were not relevant so we added them to the list of stopwords and repeated the experiment, which lead to better results. This step can be repeated several times in order to improve the model further.
We load the stopwords we downloaded near the beginning of this notebook, and we add some custom stopwords that are relevant to wikipedia pages and articles.
val swedish_stopwords = sc.textFile(stopwords_store).collect()
val wikipedia_stopwords = Array("label", "note", "area", "unit", "type", "mark", "long", "right", "kartposition", "quot", "text", "title", "page", "timestamp", "revision", "name", "username", "sha1", "format", "coord", "left", "center", "align", "region", "nasa", "source", "mouth", "species", "highest", "style", "kategori", "http", "wikipedia", "referenser", "källor", "noter")
// Combine newly identified stopwords to our exising list of stopwords
val stopwords = swedish_stopwords.union(wikipedia_stopwords)
The spark ML library gives us functions to remove stopwords.
import org.apache.spark.ml.feature.StopWordsRemover
val remover = new StopWordsRemover()
.setStopWords(stopwords)
.setInputCol("tokens")
.setOutputCol("filtered")
val filtered_df = remover.transform(tokenized_df)
import org.apache.spark.ml.feature.StopWordsRemover
remover: org.apache.spark.ml.feature.StopWordsRemover = StopWordsRemover: uid=stopWords_ecf00fa02fd5, numStopWords=366, locale=en, caseSensitive=false
filtered_df: org.apache.spark.sql.DataFrame = [id: bigint, title: string ... 3 more fields]
Vector of token counts
The LDA model takes word counts as input, so the next step is to count words that appear in the articles.
There are some hyperparameters to consider here, we focus on two:
- vocabSize - the number of words kept as the vocabulary. The vectorizer will pick the words that appear most frequently in all articles.
- minDF - the minimum number of articles that each word must appear in (i.e. document frequency). Will discard words that are very frequent in a small number of articles, but less frequent in general, and thus not generalizing to a larger topic.
We found that using a vocab size of 10 000 and a minDF of 5 worked well, but these can be experimented with further in order to obtain even better clusterings.
import org.apache.spark.ml.feature.CountVectorizer
val vectorizer = new CountVectorizer()
.setInputCol("filtered")
.setOutputCol("features")
.setVocabSize(10000)
.setMinDF(5) // the minimum number of different documents a term must appear in to be included in the vocabulary.
.fit(filtered_df)
import org.apache.spark.ml.feature.CountVectorizer
vectorizer: org.apache.spark.ml.feature.CountVectorizerModel = CountVectorizerModel: uid=cntVec_ad38aa4e1641, vocabularySize=10000
Next, we convert the dataframe to an RDD that contains the word counts
import org.apache.spark.ml.linalg.Vector
val countVectors = vectorizer.transform(filtered_df).select("id", "features")
val lda_countVector = countVectors.map { case Row(id: Long, countVector: Vector) => (id, countVector) }
val lda_countVector_mllib = lda_countVector.map { case (id, vector) => (id, org.apache.spark.mllib.linalg.Vectors.fromML(vector)) }.rdd
lda_countVector_mllib.take(1)
import org.apache.spark.ml.linalg.Vector
countVectors: org.apache.spark.sql.DataFrame = [id: bigint, features: vector]
lda_countVector: org.apache.spark.sql.Dataset[(Long, org.apache.spark.ml.linalg.Vector)] = [_1: bigint, _2: vector]
lda_countVector_mllib: org.apache.spark.rdd.RDD[(Long, org.apache.spark.mllib.linalg.Vector)] = MapPartitionsRDD[1088] at rdd at command-4443336225071537:5
res41: Array[(Long, org.apache.spark.mllib.linalg.Vector)] = Array((1,(10000,[1,2,8,9,15,17,20,26,37,38,39,42,48,50,51,55,64,67,68,71,75,80,81,85,86,94,95,96,106,114,117,118,128,129,140,149,150,156,161,189,195,208,216,297,299,332,336,399,409,427,452,457,459,461,465,535,540,572,603,612,686,739,747,806,849,904,922,983,1002,1013,1037,1081,1128,1167,1170,1175,1272,1274,1295,1334,1374,1387,1474,1578,1593,1602,1707,1750,1764,1792,1835,1852,1927,2022,2027,2114,2182,2268,2358,2612,2726,2766,2929,3316,3386,3415,3468,3486,3588,3593,3634,3693,3735,4156,4184,4335,4339,4470,4579,4675,4691,4851,5046,5083,5118,5186,5355,5653,5712,5801,6051,6080,6140,6751,7381,7491,7602,8758,8892,8944,8990,9148,9185,9375,9416,9737,9779,9870],[7.0,2.0,1.0,3.0,3.0,1.0,1.0,4.0,4.0,1.0,1.0,1.0,2.0,1.0,1.0,1.0,1.0,3.0,1.0,1.0,1.0,1.0,1.0,5.0,2.0,2.0,1.0,4.0,2.0,1.0,4.0,1.0,2.0,1.0,1.0,1.0,1.0,1.0,2.0,1.0,2.0,2.0,1.0,1.0,1.0,1.0,3.0,1.0,2.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,4.0,1.0,3.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,2.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,2.0,1.0,1.0,1.0,1.0,1.0,1.0,2.0,1.0,1.0,2.0,1.0,1.0,1.0,4.0,1.0,1.0,1.0,1.0,2.0,1.0,2.0,1.0,2.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,3.0,1.0,1.0,1.0,1.0,2.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,2.0,1.0,1.0,1.0,1.0,1.0,2.0,1.0,1.0,2.0,1.0,1.0,1.0,1.0,1.0,1.0])))
We can also save the countvector file for later use.
println(lda_countVector_store)
// lda_countVector_mllib.saveAsTextFile(lda_countVector_store);
dbfs:/datasets/05_lda/lda_countvector_sv_20201120
Hyper-parameters
It's now time to define our LDA model. We choose the online LDA due to speed and simplicity, altough one could also try using the expectation maximization algorithm here instead.
The online LDA takes two hyperparameters:
- The number of topics to cluster - this should be set to some reasonable number depending on what the purpose of the clustering is. Sometimes we might have a-priori knowledge of what the number of topics ought to be, but for Wikipedia it is not obvious how this parameter should be determined.
- The number of iterations - this can be increased in order to trade off between increased computational time and better clustering.
In this examples, we choose 50 topics since this makes it easy to visualize the results. We use 20 iterations, which yields a reasonable runtime (about 16 minutes).
val numTopics = 50
val maxIterations = 20
numTopics: Int = 50
maxIterations: Int = 20
LDA model
Let's review what the LDA model does.
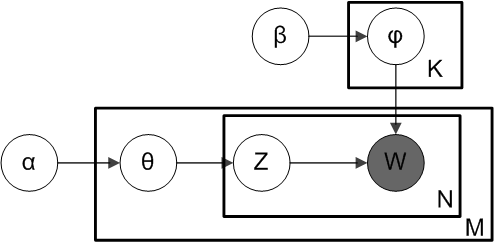
Illustration of the LDA algorithm (CC BY-SA: https://commons.wikimedia.org/wiki/File:Smoothed_LDA.png)
{kind=link}
Explaining the notation, we have:
- \(K\) - number of topics
- \(M\) - number of documents
- \(N_i\) - the number of words per document (different for each document i, of course)
- \(\theta_i\) - the topic distribution for document i
- \(\varphi_k\) - the word distribution for topic k
- \(z_{ij}\) - the topic for the j-th word in document i
- \(w_{ij}\) - the j-th word in document i
- \(\alpha\) - Dirichlet prior on the per-document topic distributions
- \(\beta\) - Dirichlet prior on the per-topic word distribution
When performing online LDA, we are fitting the data to this model by estimating values for \(\alpha\) and \(\beta\) iteratively. First, each word is randomly assigned to a topic. Then, using variational inference, the topics are reassigned in an iterative way using the empirical distributions of words within each document.
This can all be done using spark's built-in LDA optimizer.
import org.apache.spark.mllib.clustering.{LDA, OnlineLDAOptimizer}
val lda = new LDA()
.setOptimizer(new OnlineLDAOptimizer().setMiniBatchFraction(0.8))
.setK(numTopics)
.setMaxIterations(maxIterations)
.setDocConcentration(-1) // use default values
.setTopicConcentration(-1) // use default values
import org.apache.spark.mllib.clustering.{LDA, OnlineLDAOptimizer}
lda: org.apache.spark.mllib.clustering.LDA = org.apache.spark.mllib.clustering.LDA@54e767e2
The next cell is where the magic happens. We invole the disitributed LDA training functionality to obtain the model.
val ldaModel = lda.run(lda_countVector_mllib)
ldaModel: org.apache.spark.mllib.clustering.LDAModel = org.apache.spark.mllib.clustering.LocalLDAModel@5c324bb0
// Save the model to file for later use.
dbutils.fs.rm(lda_model_store, recurse=true)
ldaModel.save(sc, lda_model_store)
We prepare by extracting a few relevant terms per topic, looking them up in the vocabulary.
val maxTermsPerTopic = 8
val topicIndices = ldaModel.describeTopics(maxTermsPerTopic)
val vocabList = vectorizer.vocabulary
val topics = topicIndices.map { case (terms, termWeights) =>
terms.map(vocabList(_)).zip(termWeights)
}
println(s"$numTopics topics:")
topics.zipWithIndex.foreach { case (topic, i) =>
println(s"TOPIC $i")
topic.foreach { case (term, weight) => println(s"$term\t$weight") }
println(s"==========")
}
Zip topic terms with topic IDs
val termArray = topics.zipWithIndex
// Transform data into the form (term, probability, topicId)
val termRDD = sc.parallelize(termArray)
val termRDD2 = termRDD.flatMap( (x: (Array[(String, Double)], Int) ) => {
val arrayOfTuple = x._1
val topicId = x._2
arrayOfTuple.map(el => (el._1, el._2, topicId))
})
termRDD: org.apache.spark.rdd.RDD[(Array[(String, Double)], Int)] = ParallelCollectionRDD[1881] at parallelize at command-4443336225072171:2
termRDD2: org.apache.spark.rdd.RDD[(String, Double, Int)] = MapPartitionsRDD[1882] at flatMap at command-4443336225072171:3
// Create DF with proper column names
val termDF = termRDD2.toDF.withColumnRenamed("_1", "term").withColumnRenamed("_2", "probability").withColumnRenamed("_3", "topicId")
termDF: org.apache.spark.sql.DataFrame = [term: string, probability: double ... 1 more field]
display(termDF)
Create JSON data
val rawJson = termDF.toJSON.collect().mkString(",\n")
Plot visualization
displayHTML(s"""
<!DOCTYPE html>
<meta charset="utf-8">
<style>
circle {
fill: rgb(31, 119, 180);
fill-opacity: 0.5;
stroke: rgb(31, 119, 180);
stroke-width: 1px;
}
.leaf circle {
fill: #ff7f0e;
fill-opacity: 1;
}
text {
font: 14px sans-serif;
}
</style>
<body>
<script src="https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.5/d3.min.js"></script>
<script>
var json = {
"name": "data",
"children": [
{
"name": "topics",
"children": [
${rawJson}
]
}
]
};
var r = 1000,
format = d3.format(",d"),
fill = d3.scale.category20c();
var bubble = d3.layout.pack()
.sort(null)
.size([r, r])
.padding(1.5);
var vis = d3.select("body").append("svg")
.attr("width", r)
.attr("height", r)
.attr("class", "bubble");
var node = vis.selectAll("g.node")
.data(bubble.nodes(classes(json))
.filter(function(d) { return !d.children; }))
.enter().append("g")
.attr("class", "node")
.attr("transform", function(d) { return "translate(" + d.x + "," + d.y + ")"; })
color = d3.scale.category20();
node.append("title")
.text(function(d) { return d.className + ": " + format(d.value); });
node.append("circle")
.attr("r", function(d) { return d.r; })
.style("fill", function(d) {return color(d.topicName);});
var text = node.append("text")
.attr("text-anchor", "middle")
.attr("dy", ".3em")
.text(function(d) { return d.className.substring(0, d.r / 3)});
text.append("tspan")
.attr("dy", "1.2em")
.attr("x", 0)
.text(function(d) {return Math.ceil(d.value * 10000) /10000; });
// Returns a flattened hierarchy containing all leaf nodes under the root.
function classes(root) {
var classes = [];
function recurse(term, node) {
if (node.children) node.children.forEach(function(child) { recurse(node.term, child); });
else classes.push({topicName: node.topicId, className: node.term, value: node.probability});
}
recurse(null, root);
return {children: classes};
}
</script>
""")

Finding Articles
If we are reading an article, we can use our LDA model to find other articles on the same topic.
When we created our model earlier, we did it as an LDA, but we need to be more specific, so we reload it as a LocalLDAModel.
// Load the model
import org.apache.spark.mllib.clustering.LocalLDAModel
val model = LocalLDAModel.load(sc, lda_model_store)
import org.apache.spark.mllib.clustering.LocalLDAModel
model: org.apache.spark.mllib.clustering.LocalLDAModel = org.apache.spark.mllib.clustering.LocalLDAModel@6067f4d5
// Load the countvector
// val lda_countVector_mllib_loaded = sc.textFile("lda_countvector_sv_20201208") // This doesn't work, need to figure out how to parse the loaded rdd
// print(lda_countVector_mllib_loaded)
We sample some articles.
val numsample = 20
val sample = lda_countVector_mllib.takeSample(false, numsample)
Compute topic distributions, and extract some additional information about them.
val sampleRdd = sc.makeRDD(sample)
val topicDistributions = model.topicDistributions(sampleRdd)
val MLTopics = topicDistributions.map({case(id, vs) => (id, vs.argmax)})
val ids = MLTopics.map({case(id, vs)=>id}).collect()
val selection = filtered.filter({case(id, title, contents) => ids.contains(id)}).map({case(id, title, contents) => (id, title)}).collect()
val allTopicProbs = model.topicDistributions(lda_countVector_mllib)
sampleRdd: org.apache.spark.rdd.RDD[(Long, org.apache.spark.mllib.linalg.Vector)] = ParallelCollectionRDD[2329] at makeRDD at command-4443336225072182:1
topicDistributions: org.apache.spark.rdd.RDD[(Long, org.apache.spark.mllib.linalg.Vector)] = MapPartitionsRDD[2330] at map at LDAModel.scala:373
MLTopics: org.apache.spark.rdd.RDD[(Long, Int)] = MapPartitionsRDD[2331] at map at command-4443336225072182:3
ids: Array[Long] = Array(2779114, 226060, 1613204, 4970370, 700470, 636341, 4987605, 766457, 4965484, 82392, 7982574, 7973374, 367933, 1204225, 1225253, 503655, 821159, 8299631, 4684122, 1695311)
selection: Array[(Long, String)] = Array((82392,Senmedeltiden), (226060,Río Verde, San Luis Potosí), (367933,Kontrollsumma), (503655,Adam Kårsnäs), (636341,Live at McCabe's Guitar Shop), (700470,R2-0), (766457,Pakistanska muslimska förbundet - L), (821159,Fisher Athletic FC), (1204225,Financial Institutions Reform, Recovery and Enforcement Act of 1989), (1225253,Gardar), (1613204,Bessan), (1695311,Borneol), (2779114,Sara Branham Matthews), (4684122,Cecil Blachford), (4965484,Riddarsynerätt), (4970370,Kenyaskratthärfågel), (4987605,Rihannas diskografi), (7973374,Ahtisaariplanen), (7982574,James S. Brown), (8299631,Mount Roper))
allTopicProbs: org.apache.spark.rdd.RDD[(Long, org.apache.spark.mllib.linalg.Vector)] = MapPartitionsRDD[2335] at map at LDAModel.scala:373
For each of our selected articles, we can now look for other articles that very strongly belong to the same topic.
for ( (article_id, topic_id) <- MLTopics.collect() ) {
val title = selection.filter({case(id, title) => id == article_id})(0)._2
val topicProbs = allTopicProbs.map({case(id, vs) => (id, vs(topic_id))})
val top5articles = topicProbs.takeOrdered(5)(Ordering[Double].reverse.on(_._2))
val top5ids = top5articles.map(_._1)
val top5titles = filtered.filter({case(id, title, contents) => top5ids.contains(id) }).map({case(id, title, contents) => (title)}).collect
println(s"Top 5 articles on the same topic as ${title}:")
for (t <- top5titles) println(s" * ${t}")
println("")
}